
Browse Source
Docs theme latest (#4179)
* docs: remove specs, they live in spec repo (#4172) * docs: remove specs, they live in spec repo - moving specs to spec repo - https://github.com/tendermint/spec/pull/62 PR for updating them Signed-off-by: Marko Baricevic <marbar3778@yahoo.com> * add makefile command to copy in sepcs from specREPO - move cloning of spec repo to pre and post scripts Signed-off-by: Marko Baricevic <marbar3778@yahoo.com>pull/4200/head
 Marko
5 years ago
Marko
5 years ago
committed by
 GitHub
GitHub
GitHub
No known key found for this signature in database
GPG Key ID: 4AEE18F83AFDEB23
48 changed files with 327 additions and 5351 deletions
Unified View
Diff Options
-
+1 -0docs/.vuepress/config.js
-
+321 -192docs/package-lock.json
-
+1 -1docs/package.json
-
+2 -1docs/post.sh
-
+2 -1docs/pre.sh
-
+0 -89docs/spec/README.md
-
+0 -23docs/spec/abci/README.md
-
+0 -529docs/spec/abci/abci.md
-
+0 -453docs/spec/abci/apps.md
-
+0 -109docs/spec/abci/client-server.md
-
+0 -350docs/spec/blockchain/encoding.md
-
+0 -5docs/spec/blockchain/readme.md
-
+0 -144docs/spec/blockchain/state.md
-
+0 -3docs/spec/consensus/abci.md
-
+0 -54docs/spec/consensus/bft-time.md
-
+0 -335docs/spec/consensus/consensus.md
-
+0 -42docs/spec/consensus/creating-proposal.md
-
+0 -319docs/spec/consensus/fork-accountability.md
-
+0 -329docs/spec/consensus/light-client.md
-
+0 -5docs/spec/consensus/readme.md
-
+0 -205docs/spec/consensus/signing.md
-
+0 -32docs/spec/consensus/wal.md
-
+0 -38docs/spec/p2p/config.md
-
+0 -111docs/spec/p2p/connection.md
-
+0 -66docs/spec/p2p/node.md
-
+0 -119docs/spec/p2p/peer.md
-
+0 -5docs/spec/p2p/readme.md
-
BINdocs/spec/reactors/block_sync/bcv1/img/bc-reactor-new-datastructs.png
-
BINdocs/spec/reactors/block_sync/bcv1/img/bc-reactor-new-fsm.png
-
BINdocs/spec/reactors/block_sync/bcv1/img/bc-reactor-new-goroutines.png
-
+0 -237docs/spec/reactors/block_sync/bcv1/impl-v1.md
-
BINdocs/spec/reactors/block_sync/img/bc-reactor-routines.png
-
BINdocs/spec/reactors/block_sync/img/bc-reactor.png
-
+0 -44docs/spec/reactors/block_sync/impl.md
-
+0 -308docs/spec/reactors/block_sync/reactor.md
-
+0 -364docs/spec/reactors/consensus/consensus-reactor.md
-
+0 -184docs/spec/reactors/consensus/consensus.md
-
+0 -291docs/spec/reactors/consensus/proposer-selection.md
-
+0 -10docs/spec/reactors/evidence/reactor.md
-
+0 -8docs/spec/reactors/mempool/concurrency.md
-
+0 -54docs/spec/reactors/mempool/config.md
-
+0 -43docs/spec/reactors/mempool/functionality.md
-
+0 -61docs/spec/reactors/mempool/messages.md
-
+0 -22docs/spec/reactors/mempool/reactor.md
-
+0 -132docs/spec/reactors/pex/pex.md
-
+0 -12docs/spec/reactors/pex/reactor.md
-
+0 -5docs/spec/reactors/readme.md
-
+0 -16docs/spec/scripts/crypto.go
+ 1
- 0
docs/.vuepress/config.js
View File
+ 321
- 192
docs/package-lock.json
View File
+ 1
- 1
docs/package.json
View File
+ 2
- 1
docs/post.sh
View File
| @ -1,3 +1,4 @@ | |||||
| #!/bin/bash | #!/bin/bash | ||||
| rm -rf ./.vuepress/public/rpc | |||||
| rm -rf ./.vuepress/public/rpc | |||||
| rm -rf ./spec | |||||
+ 2
- 1
docs/pre.sh
View File
| @ -1,3 +1,4 @@ | |||||
| #!/bin/bash | #!/bin/bash | ||||
| cp -a ../rpc/swagger/ .vuepress/public/rpc/ | |||||
| cp -a ../rpc/swagger/ .vuepress/public/rpc/ | |||||
| git clone https://github.com/tendermint/spec.git specRepo && cp -r specRepo/spec . && rm -rf specRepo | |||||
+ 0
- 89
docs/spec/README.md
View File
| @ -1,89 +0,0 @@ | |||||
| --- | |||||
| order: 1 | |||||
| title: Overview | |||||
| parent: | |||||
| title: Tendermint Spec | |||||
| order: 7 | |||||
| --- | |||||
| # Tendermint Spec | |||||
| This is a markdown specification of the Tendermint blockchain. | |||||
| It defines the base data structures, how they are validated, | |||||
| and how they are communicated over the network. | |||||
| If you find discrepancies between the spec and the code that | |||||
| do not have an associated issue or pull request on github, | |||||
| please submit them to our [bug bounty](https://tendermint.com/security)! | |||||
| ## Contents | |||||
| - [Overview](#overview) | |||||
| ### Data Structures | |||||
| - [Encoding and Digests](./blockchain/encoding.md) | |||||
| - [Blockchain](./blockchain/blockchain.md) | |||||
| - [State](./blockchain/state.md) | |||||
| ### Consensus Protocol | |||||
| - [Consensus Algorithm](./consensus/consensus.md) | |||||
| - [Creating a proposal](./consensus/creating-proposal.md) | |||||
| - [Time](./consensus/bft-time.md) | |||||
| - [Light-Client](./consensus/light-client.md) | |||||
| ### P2P and Network Protocols | |||||
| - [The Base P2P Layer](./p2p/node.md): multiplex the protocols ("reactors") on authenticated and encrypted TCP connections | |||||
| - [Peer Exchange (PEX)](./reactors/pex/reactor.md): gossip known peer addresses so peers can find each other | |||||
| - [Block Sync](./reactors/block_sync/reactor.md): gossip blocks so peers can catch up quickly | |||||
| - [Consensus](./reactors/consensus/consensus.md): gossip votes and block parts so new blocks can be committed | |||||
| - [Mempool](./reactors/mempool/reactor.md): gossip transactions so they get included in blocks | |||||
| - [Evidence](./reactors/evidence/reactor.md): sending invalid evidence will stop the peer | |||||
| ### Software | |||||
| - [ABCI](./abci/README.md): Details about interactions between the | |||||
| application and consensus engine over ABCI | |||||
| - [Write-Ahead Log](./consensus/wal.md): Details about how the consensus | |||||
| engine preserves data and recovers from crash failures | |||||
| ## Overview | |||||
| Tendermint provides Byzantine Fault Tolerant State Machine Replication using | |||||
| hash-linked batches of transactions. Such transaction batches are called "blocks". | |||||
| Hence, Tendermint defines a "blockchain". | |||||
| Each block in Tendermint has a unique index - its Height. | |||||
| Height's in the blockchain are monotonic. | |||||
| Each block is committed by a known set of weighted Validators. | |||||
| Membership and weighting within this validator set may change over time. | |||||
| Tendermint guarantees the safety and liveness of the blockchain | |||||
| so long as less than 1/3 of the total weight of the Validator set | |||||
| is malicious or faulty. | |||||
| A commit in Tendermint is a set of signed messages from more than 2/3 of | |||||
| the total weight of the current Validator set. Validators take turns proposing | |||||
| blocks and voting on them. Once enough votes are received, the block is considered | |||||
| committed. These votes are included in the _next_ block as proof that the previous block | |||||
| was committed - they cannot be included in the current block, as that block has already been | |||||
| created. | |||||
| Once a block is committed, it can be executed against an application. | |||||
| The application returns results for each of the transactions in the block. | |||||
| The application can also return changes to be made to the validator set, | |||||
| as well as a cryptographic digest of its latest state. | |||||
| Tendermint is designed to enable efficient verification and authentication | |||||
| of the latest state of the blockchain. To achieve this, it embeds | |||||
| cryptographic commitments to certain information in the block "header". | |||||
| This information includes the contents of the block (eg. the transactions), | |||||
| the validator set committing the block, as well as the various results returned by the application. | |||||
| Note, however, that block execution only occurs _after_ a block is committed. | |||||
| Thus, application results can only be included in the _next_ block. | |||||
| Also note that information like the transaction results and the validator set are never | |||||
| directly included in the block - only their cryptographic digests (Merkle roots) are. | |||||
| Hence, verification of a block requires a separate data structure to store this information. | |||||
| We call this the `State`. Block verification also requires access to the previous block. | |||||
+ 0
- 23
docs/spec/abci/README.md
View File
| @ -1,23 +0,0 @@ | |||||
| --- | |||||
| cards: true | |||||
| --- | |||||
| # ABCI | |||||
| ABCI is the interface between Tendermint (a state-machine replication engine) | |||||
| and your application (the actual state machine). It consists of a set of | |||||
| _methods_, where each method has a corresponding `Request` and `Response` | |||||
| message type. Tendermint calls the ABCI methods on the ABCI application by sending the `Request*` | |||||
| messages and receiving the `Response*` messages in return. | |||||
| All message types are defined in a [protobuf file](https://github.com/tendermint/tendermint/blob/master/abci/types/types.proto). | |||||
| This allows Tendermint to run applications written in any programming language. | |||||
| This specification is split as follows: | |||||
| - [Methods and Types](./abci.md) - complete details on all ABCI methods and | |||||
| message types | |||||
| - [Applications](./apps.md) - how to manage ABCI application state and other | |||||
| details about building ABCI applications | |||||
| - [Client and Server](./client-server.md) - for those looking to implement their | |||||
| own ABCI application servers | |||||
+ 0
- 529
docs/spec/abci/abci.md
View File
| @ -1,529 +0,0 @@ | |||||
| # Methods and Types | |||||
| ## Overview | |||||
| The ABCI message types are defined in a [protobuf | |||||
| file](https://github.com/tendermint/tendermint/blob/master/abci/types/types.proto). | |||||
| ABCI methods are split across 3 separate ABCI _connections_: | |||||
| - `Consensus Connection`: `InitChain, BeginBlock, DeliverTx, EndBlock, Commit` | |||||
| - `Mempool Connection`: `CheckTx` | |||||
| - `Info Connection`: `Info, SetOption, Query` | |||||
| The `Consensus Connection` is driven by a consensus protocol and is responsible | |||||
| for block execution. | |||||
| The `Mempool Connection` is for validating new transactions, before they're | |||||
| shared or included in a block. | |||||
| The `Info Connection` is for initialization and for queries from the user. | |||||
| Additionally, there is a `Flush` method that is called on every connection, | |||||
| and an `Echo` method that is just for debugging. | |||||
| More details on managing state across connections can be found in the section on | |||||
| [ABCI Applications](apps.md). | |||||
| ## Errors | |||||
| Some methods (`Echo, Info, InitChain, BeginBlock, EndBlock, Commit`), | |||||
| don't return errors because an error would indicate a critical failure | |||||
| in the application and there's nothing Tendermint can do. The problem | |||||
| should be addressed and both Tendermint and the application restarted. | |||||
| All other methods (`SetOption, Query, CheckTx, DeliverTx`) return an | |||||
| application-specific response `Code uint32`, where only `0` is reserved | |||||
| for `OK`. | |||||
| Finally, `Query`, `CheckTx`, and `DeliverTx` include a `Codespace string`, whose | |||||
| intended use is to disambiguate `Code` values returned by different domains of the | |||||
| application. The `Codespace` is a namespace for the `Code`. | |||||
| ## Events | |||||
| Some methods (`CheckTx, BeginBlock, DeliverTx, EndBlock`) | |||||
| include an `Events` field in their `Response*`. Each event contains a type and a | |||||
| list of attributes, which are key-value pairs denoting something about what happened | |||||
| during the method's execution. | |||||
| Events can be used to index transactions and blocks according to what happened | |||||
| during their execution. Note that the set of events returned for a block from | |||||
| `BeginBlock` and `EndBlock` are merged. In case both methods return the same | |||||
| tag, only the value defined in `EndBlock` is used. | |||||
| Each event has a `type` which is meant to categorize the event for a particular | |||||
| `Response*` or tx. A `Response*` or tx may contain multiple events with duplicate | |||||
| `type` values, where each distinct entry is meant to categorize attributes for a | |||||
| particular event. Every key and value in an event's attributes must be UTF-8 | |||||
| encoded strings along with the event type itself. | |||||
| Example: | |||||
| ```go | |||||
| abci.ResponseDeliverTx{ | |||||
| // ... | |||||
| Events: []abci.Event{ | |||||
| { | |||||
| Type: "validator.provisions", | |||||
| Attributes: cmn.KVPairs{ | |||||
| cmn.KVPair{Key: []byte("address"), Value: []byte("...")}, | |||||
| cmn.KVPair{Key: []byte("amount"), Value: []byte("...")}, | |||||
| cmn.KVPair{Key: []byte("balance"), Value: []byte("...")}, | |||||
| }, | |||||
| }, | |||||
| { | |||||
| Type: "validator.provisions", | |||||
| Attributes: cmn.KVPairs{ | |||||
| cmn.KVPair{Key: []byte("address"), Value: []byte("...")}, | |||||
| cmn.KVPair{Key: []byte("amount"), Value: []byte("...")}, | |||||
| cmn.KVPair{Key: []byte("balance"), Value: []byte("...")}, | |||||
| }, | |||||
| }, | |||||
| { | |||||
| Type: "validator.slashed", | |||||
| Attributes: cmn.KVPairs{ | |||||
| cmn.KVPair{Key: []byte("address"), Value: []byte("...")}, | |||||
| cmn.KVPair{Key: []byte("amount"), Value: []byte("...")}, | |||||
| cmn.KVPair{Key: []byte("reason"), Value: []byte("...")}, | |||||
| }, | |||||
| }, | |||||
| // ... | |||||
| }, | |||||
| } | |||||
| ``` | |||||
| ## Determinism | |||||
| ABCI applications must implement deterministic finite-state machines to be | |||||
| securely replicated by the Tendermint consensus. This means block execution | |||||
| over the Consensus Connection must be strictly deterministic: given the same | |||||
| ordered set of requests, all nodes will compute identical responses, for all | |||||
| BeginBlock, DeliverTx, EndBlock, and Commit. This is critical, because the | |||||
| responses are included in the header of the next block, either via a Merkle root | |||||
| or directly, so all nodes must agree on exactly what they are. | |||||
| For this reason, it is recommended that applications not be exposed to any | |||||
| external user or process except via the ABCI connections to a consensus engine | |||||
| like Tendermint Core. The application must only change its state based on input | |||||
| from block execution (BeginBlock, DeliverTx, EndBlock, Commit), and not through | |||||
| any other kind of request. This is the only way to ensure all nodes see the same | |||||
| transactions and compute the same results. | |||||
| If there is some non-determinism in the state machine, consensus will eventually | |||||
| fail as nodes disagree over the correct values for the block header. The | |||||
| non-determinism must be fixed and the nodes restarted. | |||||
| Sources of non-determinism in applications may include: | |||||
| - Hardware failures | |||||
| - Cosmic rays, overheating, etc. | |||||
| - Node-dependent state | |||||
| - Random numbers | |||||
| - Time | |||||
| - Underspecification | |||||
| - Library version changes | |||||
| - Race conditions | |||||
| - Floating point numbers | |||||
| - JSON serialization | |||||
| - Iterating through hash-tables/maps/dictionaries | |||||
| - External Sources | |||||
| - Filesystem | |||||
| - Network calls (eg. some external REST API service) | |||||
| See [#56](https://github.com/tendermint/abci/issues/56) for original discussion. | |||||
| Note that some methods (`SetOption, Query, CheckTx, DeliverTx`) return | |||||
| explicitly non-deterministic data in the form of `Info` and `Log` fields. The `Log` is | |||||
| intended for the literal output from the application's logger, while the | |||||
| `Info` is any additional info that should be returned. These are the only fields | |||||
| that are not included in block header computations, so we don't need agreement | |||||
| on them. All other fields in the `Response*` must be strictly deterministic. | |||||
| ## Block Execution | |||||
| The first time a new blockchain is started, Tendermint calls | |||||
| `InitChain`. From then on, the following sequence of methods is executed for each | |||||
| block: | |||||
| `BeginBlock, [DeliverTx], EndBlock, Commit` | |||||
| where one `DeliverTx` is called for each transaction in the block. | |||||
| The result is an updated application state. | |||||
| Cryptographic commitments to the results of DeliverTx, EndBlock, and | |||||
| Commit are included in the header of the next block. | |||||
| ## Messages | |||||
| ### Echo | |||||
| - **Request**: | |||||
| - `Message (string)`: A string to echo back | |||||
| - **Response**: | |||||
| - `Message (string)`: The input string | |||||
| - **Usage**: | |||||
| - Echo a string to test an abci client/server implementation | |||||
| ### Flush | |||||
| - **Usage**: | |||||
| - Signals that messages queued on the client should be flushed to | |||||
| the server. It is called periodically by the client | |||||
| implementation to ensure asynchronous requests are actually | |||||
| sent, and is called immediately to make a synchronous request, | |||||
| which returns when the Flush response comes back. | |||||
| ### Info | |||||
| - **Request**: | |||||
| - `Version (string)`: The Tendermint software semantic version | |||||
| - `BlockVersion (uint64)`: The Tendermint Block Protocol version | |||||
| - `P2PVersion (uint64)`: The Tendermint P2P Protocol version | |||||
| - **Response**: | |||||
| - `Data (string)`: Some arbitrary information | |||||
| - `Version (string)`: The application software semantic version | |||||
| - `AppVersion (uint64)`: The application protocol version | |||||
| - `LastBlockHeight (int64)`: Latest block for which the app has | |||||
| called Commit | |||||
| - `LastBlockAppHash ([]byte)`: Latest result of Commit | |||||
| - **Usage**: | |||||
| - Return information about the application state. | |||||
| - Used to sync Tendermint with the application during a handshake | |||||
| that happens on startup. | |||||
| - The returned `AppVersion` will be included in the Header of every block. | |||||
| - Tendermint expects `LastBlockAppHash` and `LastBlockHeight` to | |||||
| be updated during `Commit`, ensuring that `Commit` is never | |||||
| called twice for the same block height. | |||||
| ### SetOption | |||||
| - **Request**: | |||||
| - `Key (string)`: Key to set | |||||
| - `Value (string)`: Value to set for key | |||||
| - **Response**: | |||||
| - `Code (uint32)`: Response code | |||||
| - `Log (string)`: The output of the application's logger. May | |||||
| be non-deterministic. | |||||
| - `Info (string)`: Additional information. May | |||||
| be non-deterministic. | |||||
| - **Usage**: | |||||
| - Set non-consensus critical application specific options. | |||||
| - e.g. Key="min-fee", Value="100fermion" could set the minimum fee | |||||
| required for CheckTx (but not DeliverTx - that would be | |||||
| consensus critical). | |||||
| ### InitChain | |||||
| - **Request**: | |||||
| - `Time (google.protobuf.Timestamp)`: Genesis time. | |||||
| - `ChainID (string)`: ID of the blockchain. | |||||
| - `ConsensusParams (ConsensusParams)`: Initial consensus-critical parameters. | |||||
| - `Validators ([]ValidatorUpdate)`: Initial genesis validators. | |||||
| - `AppStateBytes ([]byte)`: Serialized initial application state. Amino-encoded JSON bytes. | |||||
| - **Response**: | |||||
| - `ConsensusParams (ConsensusParams)`: Initial | |||||
| consensus-critical parameters. | |||||
| - `Validators ([]ValidatorUpdate)`: Initial validator set (if non empty). | |||||
| - **Usage**: | |||||
| - Called once upon genesis. | |||||
| - If ResponseInitChain.Validators is empty, the initial validator set will be the RequestInitChain.Validators | |||||
| - If ResponseInitChain.Validators is not empty, the initial validator set will be the | |||||
| ResponseInitChain.Validators (regardless of what is in RequestInitChain.Validators). | |||||
| - This allows the app to decide if it wants to accept the initial validator | |||||
| set proposed by tendermint (ie. in the genesis file), or if it wants to use | |||||
| a different one (perhaps computed based on some application specific | |||||
| information in the genesis file). | |||||
| ### Query | |||||
| - **Request**: | |||||
| - `Data ([]byte)`: Raw query bytes. Can be used with or in lieu | |||||
| of Path. | |||||
| - `Path (string)`: Path of request, like an HTTP GET path. Can be | |||||
| used with or in liue of Data. | |||||
| - Apps MUST interpret '/store' as a query by key on the | |||||
| underlying store. The key SHOULD be specified in the Data field. | |||||
| - Apps SHOULD allow queries over specific types like | |||||
| '/accounts/...' or '/votes/...' | |||||
| - `Height (int64)`: The block height for which you want the query | |||||
| (default=0 returns data for the latest committed block). Note | |||||
| that this is the height of the block containing the | |||||
| application's Merkle root hash, which represents the state as it | |||||
| was after committing the block at Height-1 | |||||
| - `Prove (bool)`: Return Merkle proof with response if possible | |||||
| - **Response**: | |||||
| - `Code (uint32)`: Response code. | |||||
| - `Log (string)`: The output of the application's logger. May | |||||
| be non-deterministic. | |||||
| - `Info (string)`: Additional information. May | |||||
| be non-deterministic. | |||||
| - `Index (int64)`: The index of the key in the tree. | |||||
| - `Key ([]byte)`: The key of the matching data. | |||||
| - `Value ([]byte)`: The value of the matching data. | |||||
| - `Proof (Proof)`: Serialized proof for the value data, if requested, to be | |||||
| verified against the `AppHash` for the given Height. | |||||
| - `Height (int64)`: The block height from which data was derived. | |||||
| Note that this is the height of the block containing the | |||||
| application's Merkle root hash, which represents the state as it | |||||
| was after committing the block at Height-1 | |||||
| - `Codespace (string)`: Namespace for the `Code`. | |||||
| - **Usage**: | |||||
| - Query for data from the application at current or past height. | |||||
| - Optionally return Merkle proof. | |||||
| - Merkle proof includes self-describing `type` field to support many types | |||||
| of Merkle trees and encoding formats. | |||||
| ### BeginBlock | |||||
| - **Request**: | |||||
| - `Hash ([]byte)`: The block's hash. This can be derived from the | |||||
| block header. | |||||
| - `Header (struct{})`: The block header. | |||||
| - `LastCommitInfo (LastCommitInfo)`: Info about the last commit, including the | |||||
| round, and the list of validators and which ones signed the last block. | |||||
| - `ByzantineValidators ([]Evidence)`: List of evidence of | |||||
| validators that acted maliciously. | |||||
| - **Response**: | |||||
| - `Tags ([]cmn.KVPair)`: Key-Value tags for filtering and indexing | |||||
| - **Usage**: | |||||
| - Signals the beginning of a new block. Called prior to | |||||
| any DeliverTxs. | |||||
| - The header contains the height, timestamp, and more - it exactly matches the | |||||
| Tendermint block header. We may seek to generalize this in the future. | |||||
| - The `LastCommitInfo` and `ByzantineValidators` can be used to determine | |||||
| rewards and punishments for the validators. NOTE validators here do not | |||||
| include pubkeys. | |||||
| ### CheckTx | |||||
| - **Request**: | |||||
| - `Tx ([]byte)`: The request transaction bytes | |||||
| - `Type (CheckTxType)`: What type of `CheckTx` request is this? At present, | |||||
| there are two possible values: `CheckTx_New` (the default, which says | |||||
| that a full check is required), and `CheckTx_Recheck` (when the mempool is | |||||
| initiating a normal recheck of a transaction). | |||||
| - **Response**: | |||||
| - `Code (uint32)`: Response code | |||||
| - `Data ([]byte)`: Result bytes, if any. | |||||
| - `Log (string)`: The output of the application's logger. May | |||||
| be non-deterministic. | |||||
| - `Info (string)`: Additional information. May | |||||
| be non-deterministic. | |||||
| - `GasWanted (int64)`: Amount of gas requested for transaction. | |||||
| - `GasUsed (int64)`: Amount of gas consumed by transaction. | |||||
| - `Tags ([]cmn.KVPair)`: Key-Value tags for filtering and indexing | |||||
| transactions (eg. by account). | |||||
| - `Codespace (string)`: Namespace for the `Code`. | |||||
| - **Usage**: | |||||
| - Technically optional - not involved in processing blocks. | |||||
| - Guardian of the mempool: every node runs CheckTx before letting a | |||||
| transaction into its local mempool. | |||||
| - The transaction may come from an external user or another node | |||||
| - CheckTx need not execute the transaction in full, but rather a light-weight | |||||
| yet stateful validation, like checking signatures and account balances, but | |||||
| not running code in a virtual machine. | |||||
| - Transactions where `ResponseCheckTx.Code != 0` will be rejected - they will not be broadcast to | |||||
| other nodes or included in a proposal block. | |||||
| - Tendermint attributes no other value to the response code | |||||
| ### DeliverTx | |||||
| - **Request**: | |||||
| - `Tx ([]byte)`: The request transaction bytes. | |||||
| - **Response**: | |||||
| - `Code (uint32)`: Response code. | |||||
| - `Data ([]byte)`: Result bytes, if any. | |||||
| - `Log (string)`: The output of the application's logger. May | |||||
| be non-deterministic. | |||||
| - `Info (string)`: Additional information. May | |||||
| be non-deterministic. | |||||
| - `GasWanted (int64)`: Amount of gas requested for transaction. | |||||
| - `GasUsed (int64)`: Amount of gas consumed by transaction. | |||||
| - `Tags ([]cmn.KVPair)`: Key-Value tags for filtering and indexing | |||||
| transactions (eg. by account). | |||||
| - `Codespace (string)`: Namespace for the `Code`. | |||||
| - **Usage**: | |||||
| - The workhorse of the application - non-optional. | |||||
| - Execute the transaction in full. | |||||
| - `ResponseDeliverTx.Code == 0` only if the transaction is fully valid. | |||||
| ### EndBlock | |||||
| - **Request**: | |||||
| - `Height (int64)`: Height of the block just executed. | |||||
| - **Response**: | |||||
| - `ValidatorUpdates ([]ValidatorUpdate)`: Changes to validator set (set | |||||
| voting power to 0 to remove). | |||||
| - `ConsensusParamUpdates (ConsensusParams)`: Changes to | |||||
| consensus-critical time, size, and other parameters. | |||||
| - `Tags ([]cmn.KVPair)`: Key-Value tags for filtering and indexing | |||||
| - **Usage**: | |||||
| - Signals the end of a block. | |||||
| - Called after all transactions, prior to each Commit. | |||||
| - Validator updates returned by block `H` impact blocks `H+1`, `H+2`, and | |||||
| `H+3`, but only effects changes on the validator set of `H+2`: | |||||
| - `H+1`: NextValidatorsHash | |||||
| - `H+2`: ValidatorsHash (and thus the validator set) | |||||
| - `H+3`: LastCommitInfo (ie. the last validator set) | |||||
| - Consensus params returned for block `H` apply for block `H+1` | |||||
| ### Commit | |||||
| - **Response**: | |||||
| - `Data ([]byte)`: The Merkle root hash of the application state | |||||
| - **Usage**: | |||||
| - Persist the application state. | |||||
| - Return an (optional) Merkle root hash of the application state | |||||
| - `ResponseCommit.Data` is included as the `Header.AppHash` in the next block | |||||
| - it may be empty | |||||
| - Later calls to `Query` can return proofs about the application state anchored | |||||
| in this Merkle root hash | |||||
| - Note developers can return whatever they want here (could be nothing, or a | |||||
| constant string, etc.), so long as it is deterministic - it must not be a | |||||
| function of anything that did not come from the | |||||
| BeginBlock/DeliverTx/EndBlock methods. | |||||
| ## Data Types | |||||
| ### Header | |||||
| - **Fields**: | |||||
| - `Version (Version)`: Version of the blockchain and the application | |||||
| - `ChainID (string)`: ID of the blockchain | |||||
| - `Height (int64)`: Height of the block in the chain | |||||
| - `Time (google.protobuf.Timestamp)`: Time of the previous block. | |||||
| For heights > 1, it's the weighted median of the timestamps of the valid | |||||
| votes in the block.LastCommit. | |||||
| For height == 1, it's genesis time. | |||||
| - `LastBlockID (BlockID)`: Hash of the previous (parent) block | |||||
| - `LastCommitHash ([]byte)`: Hash of the previous block's commit | |||||
| - `ValidatorsHash ([]byte)`: Hash of the validator set for this block | |||||
| - `NextValidatorsHash ([]byte)`: Hash of the validator set for the next block | |||||
| - `ConsensusHash ([]byte)`: Hash of the consensus parameters for this block | |||||
| - `AppHash ([]byte)`: Data returned by the last call to `Commit` - typically the | |||||
| Merkle root of the application state after executing the previous block's | |||||
| transactions | |||||
| - `LastResultsHash ([]byte)`: Hash of the ABCI results returned by the last block | |||||
| - `EvidenceHash ([]byte)`: Hash of the evidence included in this block | |||||
| - `ProposerAddress ([]byte)`: Original proposer for the block | |||||
| - **Usage**: | |||||
| - Provided in RequestBeginBlock | |||||
| - Provides important context about the current state of the blockchain - | |||||
| especially height and time. | |||||
| - Provides the proposer of the current block, for use in proposer-based | |||||
| reward mechanisms. | |||||
| ### Version | |||||
| - **Fields**: | |||||
| - `Block (uint64)`: Protocol version of the blockchain data structures. | |||||
| - `App (uint64)`: Protocol version of the application. | |||||
| - **Usage**: | |||||
| - Block version should be static in the life of a blockchain. | |||||
| - App version may be updated over time by the application. | |||||
| ### Validator | |||||
| - **Fields**: | |||||
| - `Address ([]byte)`: Address of the validator (hash of the public key) | |||||
| - `Power (int64)`: Voting power of the validator | |||||
| - **Usage**: | |||||
| - Validator identified by address | |||||
| - Used in RequestBeginBlock as part of VoteInfo | |||||
| - Does not include PubKey to avoid sending potentially large quantum pubkeys | |||||
| over the ABCI | |||||
| ### ValidatorUpdate | |||||
| - **Fields**: | |||||
| - `PubKey (PubKey)`: Public key of the validator | |||||
| - `Power (int64)`: Voting power of the validator | |||||
| - **Usage**: | |||||
| - Validator identified by PubKey | |||||
| - Used to tell Tendermint to update the validator set | |||||
| ### VoteInfo | |||||
| - **Fields**: | |||||
| - `Validator (Validator)`: A validator | |||||
| - `SignedLastBlock (bool)`: Indicates whether or not the validator signed | |||||
| the last block | |||||
| - **Usage**: | |||||
| - Indicates whether a validator signed the last block, allowing for rewards | |||||
| based on validator availability | |||||
| ### PubKey | |||||
| - **Fields**: | |||||
| - `Type (string)`: Type of the public key. A simple string like `"ed25519"`. | |||||
| In the future, may indicate a serialization algorithm to parse the `Data`, | |||||
| for instance `"amino"`. | |||||
| - `Data ([]byte)`: Public key data. For a simple public key, it's just the | |||||
| raw bytes. If the `Type` indicates an encoding algorithm, this is the | |||||
| encoded public key. | |||||
| - **Usage**: | |||||
| - A generic and extensible typed public key | |||||
| ### Evidence | |||||
| - **Fields**: | |||||
| - `Type (string)`: Type of the evidence. A hierarchical path like | |||||
| "duplicate/vote". | |||||
| - `Validator (Validator`: The offending validator | |||||
| - `Height (int64)`: Height when the offense was committed | |||||
| - `Time (google.protobuf.Timestamp)`: Time of the block at height `Height`. | |||||
| It is the proposer's local time when block was created. | |||||
| - `TotalVotingPower (int64)`: Total voting power of the validator set at | |||||
| height `Height` | |||||
| ### LastCommitInfo | |||||
| - **Fields**: | |||||
| - `Round (int32)`: Commit round. | |||||
| - `Votes ([]VoteInfo)`: List of validators addresses in the last validator set | |||||
| with their voting power and whether or not they signed a vote. | |||||
| ### ConsensusParams | |||||
| - **Fields**: | |||||
| - `Block (BlockParams)`: Parameters limiting the size of a block and time between consecutive blocks. | |||||
| - `Evidence (EvidenceParams)`: Parameters limiting the validity of | |||||
| evidence of byzantine behaviour. | |||||
| - `Validator (ValidatorParams)`: Parameters limitng the types of pubkeys validators can use. | |||||
| ### BlockParams | |||||
| - **Fields**: | |||||
| - `MaxBytes (int64)`: Max size of a block, in bytes. | |||||
| - `MaxGas (int64)`: Max sum of `GasWanted` in a proposed block. | |||||
| - NOTE: blocks that violate this may be committed if there are Byzantine proposers. | |||||
| It's the application's responsibility to handle this when processing a | |||||
| block! | |||||
| ### EvidenceParams | |||||
| - **Fields**: | |||||
| - `MaxAge (int64)`: Max age of evidence, in blocks. Evidence older than this | |||||
| is considered stale and ignored. | |||||
| - This should correspond with an app's "unbonding period" or other | |||||
| similar mechanism for handling Nothing-At-Stake attacks. | |||||
| - NOTE: this should change to time (instead of blocks)! | |||||
| ### ValidatorParams | |||||
| - **Fields**: | |||||
| - `PubKeyTypes ([]string)`: List of accepted pubkey types. Uses same | |||||
| naming as `PubKey.Type`. | |||||
| ### Proof | |||||
| - **Fields**: | |||||
| - `Ops ([]ProofOp)`: List of chained Merkle proofs, of possibly different types | |||||
| - The Merkle root of one op is the value being proven in the next op. | |||||
| - The Merkle root of the final op should equal the ultimate root hash being | |||||
| verified against. | |||||
| ### ProofOp | |||||
| - **Fields**: | |||||
| - `Type (string)`: Type of Merkle proof and how it's encoded. | |||||
| - `Key ([]byte)`: Key in the Merkle tree that this proof is for. | |||||
| - `Data ([]byte)`: Encoded Merkle proof for the key. | |||||
+ 0
- 453
docs/spec/abci/apps.md
View File
| @ -1,453 +0,0 @@ | |||||
| # Applications | |||||
| Please ensure you've first read the spec for [ABCI Methods and Types](abci.md) | |||||
| Here we cover the following components of ABCI applications: | |||||
| - [Connection State](#state) - the interplay between ABCI connections and application state | |||||
| and the differences between `CheckTx` and `DeliverTx`. | |||||
| - [Transaction Results](#transaction-results) - rules around transaction | |||||
| results and validity | |||||
| - [Validator Set Updates](#validator-updates) - how validator sets are | |||||
| changed during `InitChain` and `EndBlock` | |||||
| - [Query](#query) - standards for using the `Query` method and proofs about the | |||||
| application state | |||||
| - [Crash Recovery](#crash-recovery) - handshake protocol to synchronize | |||||
| Tendermint and the application on startup. | |||||
| ## State | |||||
| Since Tendermint maintains three concurrent ABCI connections, it is typical | |||||
| for an application to maintain a distinct state for each, and for the states to | |||||
| be synchronized during `Commit`. | |||||
| ### Commit | |||||
| Application state should only be persisted to disk during `Commit`. | |||||
| Before `Commit` is called, Tendermint locks and flushes the mempool so that no new messages will | |||||
| be received on the mempool connection. This provides an opportunity to safely update all three | |||||
| states to the latest committed state at once. | |||||
| When `Commit` completes, it unlocks the mempool. | |||||
| WARNING: if the ABCI app logic processing the `Commit` message sends a | |||||
| `/broadcast_tx_sync` or `/broadcast_tx_commit` and waits for the response | |||||
| before proceeding, it will deadlock. Executing those `broadcast_tx` calls | |||||
| involves acquiring a lock that is held during the `Commit` call, so it's not | |||||
| possible. If you make the call to the `broadcast_tx` endpoints concurrently, | |||||
| that's no problem, it just can't be part of the sequential logic of the | |||||
| `Commit` function. | |||||
| ### Consensus Connection | |||||
| The Consensus Connection should maintain a `DeliverTxState` - | |||||
| the working state for block execution. It should be updated by the calls to | |||||
| `BeginBlock`, `DeliverTx`, and `EndBlock` during block execution and committed to | |||||
| disk as the "latest committed state" during `Commit`. | |||||
| Updates made to the DeliverTxState by each method call must be readable by each subsequent method - | |||||
| ie. the updates are linearizable. | |||||
| ### Mempool Connection | |||||
| The Mempool Connection should maintain a `CheckTxState` | |||||
| to sequentially process pending transactions in the mempool that have | |||||
| not yet been committed. It should be initialized to the latest committed state | |||||
| at the end of every `Commit`. | |||||
| The CheckTxState may be updated concurrently with the DeliverTxState, as | |||||
| messages may be sent concurrently on the Consensus and Mempool connections. However, | |||||
| before calling `Commit`, Tendermint will lock and flush the mempool connection, | |||||
| ensuring that all existing CheckTx are responded to and no new ones can | |||||
| begin. | |||||
| After `Commit`, CheckTx is run again on all transactions that remain in the | |||||
| node's local mempool after filtering those included in the block. To prevent the | |||||
| mempool from rechecking all transactions every time a block is committed, set | |||||
| the configuration option `mempool.recheck=false`. As of Tendermint v0.32.1, | |||||
| an additional `Type` parameter is made available to the CheckTx function that | |||||
| indicates whether an incoming transaction is new (`CheckTxType_New`), or a | |||||
| recheck (`CheckTxType_Recheck`). | |||||
| Finally, the mempool will unlock and new transactions can be processed through CheckTx again. | |||||
| Note that CheckTx doesn't have to check everything that affects transaction validity; the | |||||
| expensive things can be skipped. In fact, CheckTx doesn't have to check | |||||
| anything; it might say that any transaction is a valid transaction. | |||||
| Unlike DeliverTx, CheckTx is just there as | |||||
| a sort of weak filter to keep invalid transactions out of the blockchain. It's | |||||
| weak, because a Byzantine node doesn't care about CheckTx; it can propose a | |||||
| block full of invalid transactions if it wants. | |||||
| ### Info Connection | |||||
| The Info Connection should maintain a `QueryState` for answering queries from the user, | |||||
| and for initialization when Tendermint first starts up (both described further | |||||
| below). | |||||
| It should always contain the latest committed state associated with the | |||||
| latest committed block. | |||||
| QueryState should be set to the latest `DeliverTxState` at the end of every `Commit`, | |||||
| ie. after the full block has been processed and the state committed to disk. | |||||
| Otherwise it should never be modified. | |||||
| ## Transaction Results | |||||
| `ResponseCheckTx` and `ResponseDeliverTx` contain the same fields. | |||||
| The `Info` and `Log` fields are non-deterministic values for debugging/convenience purposes | |||||
| that are otherwise ignored. | |||||
| The `Data` field must be strictly deterministic, but can be arbitrary data. | |||||
| ### Gas | |||||
| Ethereum introduced the notion of `gas` as an abstract representation of the | |||||
| cost of resources used by nodes when processing transactions. Every operation in the | |||||
| Ethereum Virtual Machine uses some amount of gas, and gas can be accepted at a market-variable price. | |||||
| Users propose a maximum amount of gas for their transaction; if the tx uses less, they get | |||||
| the difference credited back. Tendermint adopts a similar abstraction, | |||||
| though uses it only optionally and weakly, allowing applications to define | |||||
| their own sense of the cost of execution. | |||||
| In Tendermint, the `ConsensusParams.Block.MaxGas` limits the amount of `gas` that can be used in a block. | |||||
| The default value is `-1`, meaning no limit, or that the concept of gas is | |||||
| meaningless. | |||||
| Responses contain a `GasWanted` and `GasUsed` field. The former is the maximum | |||||
| amount of gas the sender of a tx is willing to use, and the later is how much it actually | |||||
| used. Applications should enforce that `GasUsed <= GasWanted` - ie. tx execution | |||||
| should halt before it can use more resources than it requested. | |||||
| When `MaxGas > -1`, Tendermint enforces the following rules: | |||||
| - `GasWanted <= MaxGas` for all txs in the mempool | |||||
| - `(sum of GasWanted in a block) <= MaxGas` when proposing a block | |||||
| If `MaxGas == -1`, no rules about gas are enforced. | |||||
| Note that Tendermint does not currently enforce anything about Gas in the consensus, only the mempool. | |||||
| This means it does not guarantee that committed blocks satisfy these rules! | |||||
| It is the application's responsibility to return non-zero response codes when gas limits are exceeded. | |||||
| The `GasUsed` field is ignored completely by Tendermint. That said, applications should enforce: | |||||
| - `GasUsed <= GasWanted` for any given transaction | |||||
| - `(sum of GasUsed in a block) <= MaxGas` for every block | |||||
| In the future, we intend to add a `Priority` field to the responses that can be | |||||
| used to explicitly prioritize txs in the mempool for inclusion in a block | |||||
| proposal. See [#1861](https://github.com/tendermint/tendermint/issues/1861). | |||||
| ### CheckTx | |||||
| If `Code != 0`, it will be rejected from the mempool and hence | |||||
| not broadcasted to other peers and not included in a proposal block. | |||||
| `Data` contains the result of the CheckTx transaction execution, if any. It is | |||||
| semantically meaningless to Tendermint. | |||||
| `Tags` include any tags for the execution, though since the transaction has not | |||||
| been committed yet, they are effectively ignored by Tendermint. | |||||
| ### DeliverTx | |||||
| If DeliverTx returns `Code != 0`, the transaction will be considered invalid, | |||||
| though it is still included in the block. | |||||
| `Data` contains the result of the CheckTx transaction execution, if any. It is | |||||
| semantically meaningless to Tendermint. | |||||
| Both the `Code` and `Data` are included in a structure that is hashed into the | |||||
| `LastResultsHash` of the next block header. | |||||
| `Tags` include any tags for the execution, which Tendermint will use to index | |||||
| the transaction by. This allows transactions to be queried according to what | |||||
| events took place during their execution. | |||||
| See issue [#1007](https://github.com/tendermint/tendermint/issues/1007) for how | |||||
| the tags will be hashed into the next block header. | |||||
| ## Validator Updates | |||||
| The application may set the validator set during InitChain, and update it during | |||||
| EndBlock. | |||||
| Note that the maximum total power of the validator set is bounded by | |||||
| `MaxTotalVotingPower = MaxInt64 / 8`. Applications are responsible for ensuring | |||||
| they do not make changes to the validator set that cause it to exceed this | |||||
| limit. | |||||
| Additionally, applications must ensure that a single set of updates does not contain any duplicates - | |||||
| a given public key can only appear in an update once. If an update includes | |||||
| duplicates, the block execution will fail irrecoverably. | |||||
| ### InitChain | |||||
| ResponseInitChain can return a list of validators. | |||||
| If the list is empty, Tendermint will use the validators loaded in the genesis | |||||
| file. | |||||
| If the list is not empty, Tendermint will use it for the validator set. | |||||
| This way the application can determine the initial validator set for the | |||||
| blockchain. | |||||
| ### EndBlock | |||||
| Updates to the Tendermint validator set can be made by returning | |||||
| `ValidatorUpdate` objects in the `ResponseEndBlock`: | |||||
| ``` | |||||
| message ValidatorUpdate { | |||||
| PubKey pub_key | |||||
| int64 power | |||||
| } | |||||
| message PubKey { | |||||
| string type | |||||
| bytes data | |||||
| } | |||||
| ``` | |||||
| The `pub_key` currently supports only one type: | |||||
| - `type = "ed25519"` and `data = <raw 32-byte public key>` | |||||
| The `power` is the new voting power for the validator, with the | |||||
| following rules: | |||||
| - power must be non-negative | |||||
| - if power is 0, the validator must already exist, and will be removed from the | |||||
| validator set | |||||
| - if power is non-0: | |||||
| - if the validator does not already exist, it will be added to the validator | |||||
| set with the given power | |||||
| - if the validator does already exist, its power will be adjusted to the given power | |||||
| - the total power of the new validator set must not exceed MaxTotalVotingPower | |||||
| Note the updates returned in block `H` will only take effect at block `H+2`. | |||||
| ## Consensus Parameters | |||||
| ConsensusParams enforce certain limits in the blockchain, like the maximum size | |||||
| of blocks, amount of gas used in a block, and the maximum acceptable age of | |||||
| evidence. They can be set in InitChain and updated in EndBlock. | |||||
| ### Block.MaxBytes | |||||
| The maximum size of a complete Amino encoded block. | |||||
| This is enforced by Tendermint consensus. | |||||
| This implies a maximum tx size that is this MaxBytes, less the expected size of | |||||
| the header, the validator set, and any included evidence in the block. | |||||
| Must have `0 < MaxBytes < 100 MB`. | |||||
| ### Block.MaxGas | |||||
| The maximum of the sum of `GasWanted` in a proposed block. | |||||
| This is *not* enforced by Tendermint consensus. | |||||
| It is left to the app to enforce (ie. if txs are included past the | |||||
| limit, they should return non-zero codes). It is used by Tendermint to limit the | |||||
| txs included in a proposed block. | |||||
| Must have `MaxGas >= -1`. | |||||
| If `MaxGas == -1`, no limit is enforced. | |||||
| ### Block.TimeIotaMs | |||||
| The minimum time between consecutive blocks (in milliseconds). | |||||
| This is enforced by Tendermint consensus. | |||||
| Must have `TimeIotaMs > 0` to ensure time monotonicity. | |||||
| ### EvidenceParams.MaxAge | |||||
| This is the maximum age of evidence. | |||||
| This is enforced by Tendermint consensus. | |||||
| If a block includes evidence older than this, the block will be rejected | |||||
| (validators won't vote for it). | |||||
| Must have `MaxAge > 0`. | |||||
| ### Updates | |||||
| The application may set the ConsensusParams during InitChain, and update them during | |||||
| EndBlock. If the ConsensusParams is empty, it will be ignored. Each field | |||||
| that is not empty will be applied in full. For instance, if updating the | |||||
| Block.MaxBytes, applications must also set the other Block fields (like | |||||
| Block.MaxGas), even if they are unchanged, as they will otherwise cause the | |||||
| value to be updated to 0. | |||||
| #### InitChain | |||||
| ResponseInitChain includes a ConsensusParams. | |||||
| If its nil, Tendermint will use the params loaded in the genesis | |||||
| file. If it's not nil, Tendermint will use it. | |||||
| This way the application can determine the initial consensus params for the | |||||
| blockchain. | |||||
| #### EndBlock | |||||
| ResponseEndBlock includes a ConsensusParams. | |||||
| If its nil, Tendermint will do nothing. | |||||
| If it's not nil, Tendermint will use it. | |||||
| This way the application can update the consensus params over time. | |||||
| Note the updates returned in block `H` will take effect right away for block | |||||
| `H+1`. | |||||
| ## Query | |||||
| Query is a generic method with lots of flexibility to enable diverse sets | |||||
| of queries on application state. Tendermint makes use of Query to filter new peers | |||||
| based on ID and IP, and exposes Query to the user over RPC. | |||||
| Note that calls to Query are not replicated across nodes, but rather query the | |||||
| local node's state - hence they may return stale reads. For reads that require | |||||
| consensus, use a transaction. | |||||
| The most important use of Query is to return Merkle proofs of the application state at some height | |||||
| that can be used for efficient application-specific lite-clients. | |||||
| Note Tendermint has technically no requirements from the Query | |||||
| message for normal operation - that is, the ABCI app developer need not implement | |||||
| Query functionality if they do not wish too. | |||||
| ### Query Proofs | |||||
| The Tendermint block header includes a number of hashes, each providing an | |||||
| anchor for some type of proof about the blockchain. The `ValidatorsHash` enables | |||||
| quick verification of the validator set, the `DataHash` gives quick | |||||
| verification of the transactions included in the block, etc. | |||||
| The `AppHash` is unique in that it is application specific, and allows for | |||||
| application-specific Merkle proofs about the state of the application. | |||||
| While some applications keep all relevant state in the transactions themselves | |||||
| (like Bitcoin and its UTXOs), others maintain a separated state that is | |||||
| computed deterministically *from* transactions, but is not contained directly in | |||||
| the transactions themselves (like Ethereum contracts and accounts). | |||||
| For such applications, the `AppHash` provides a much more efficient way to verify lite-client proofs. | |||||
| ABCI applications can take advantage of more efficient lite-client proofs for | |||||
| their state as follows: | |||||
| - return the Merkle root of the deterministic application state in | |||||
| `ResponseCommit.Data`. | |||||
| - it will be included as the `AppHash` in the next block. | |||||
| - return efficient Merkle proofs about that application state in `ResponseQuery.Proof` | |||||
| that can be verified using the `AppHash` of the corresponding block. | |||||
| For instance, this allows an application's lite-client to verify proofs of | |||||
| absence in the application state, something which is much less efficient to do using the block hash. | |||||
| Some applications (eg. Ethereum, Cosmos-SDK) have multiple "levels" of Merkle trees, | |||||
| where the leaves of one tree are the root hashes of others. To support this, and | |||||
| the general variability in Merkle proofs, the `ResponseQuery.Proof` has some minimal structure: | |||||
| ``` | |||||
| message Proof { | |||||
| repeated ProofOp ops | |||||
| } | |||||
| message ProofOp { | |||||
| string type = 1; | |||||
| bytes key = 2; | |||||
| bytes data = 3; | |||||
| } | |||||
| ``` | |||||
| Each `ProofOp` contains a proof for a single key in a single Merkle tree, of the specified `type`. | |||||
| This allows ABCI to support many different kinds of Merkle trees, encoding | |||||
| formats, and proofs (eg. of presence and absence) just by varying the `type`. | |||||
| The `data` contains the actual encoded proof, encoded according to the `type`. | |||||
| When verifying the full proof, the root hash for one ProofOp is the value being | |||||
| verified for the next ProofOp in the list. The root hash of the final ProofOp in | |||||
| the list should match the `AppHash` being verified against. | |||||
| ### Peer Filtering | |||||
| When Tendermint connects to a peer, it sends two queries to the ABCI application | |||||
| using the following paths, with no additional data: | |||||
| - `/p2p/filter/addr/<IP:PORT>`, where `<IP:PORT>` denote the IP address and | |||||
| the port of the connection | |||||
| - `p2p/filter/id/<ID>`, where `<ID>` is the peer node ID (ie. the | |||||
| pubkey.Address() for the peer's PubKey) | |||||
| If either of these queries return a non-zero ABCI code, Tendermint will refuse | |||||
| to connect to the peer. | |||||
| ### Paths | |||||
| Queries are directed at paths, and may optionally include additional data. | |||||
| The expectation is for there to be some number of high level paths | |||||
| differentiating concerns, like `/p2p`, `/store`, and `/app`. Currently, | |||||
| Tendermint only uses `/p2p`, for filtering peers. For more advanced use, see the | |||||
| implementation of | |||||
| [Query in the Cosmos-SDK](https://github.com/cosmos/cosmos-sdk/blob/v0.23.1/baseapp/baseapp.go#L333). | |||||
| ## Crash Recovery | |||||
| On startup, Tendermint calls the `Info` method on the Info Connection to get the latest | |||||
| committed state of the app. The app MUST return information consistent with the | |||||
| last block it succesfully completed Commit for. | |||||
| If the app succesfully committed block H but not H+1, then `last_block_height = H` and `last_block_app_hash = <hash returned by Commit for block H>`. If the app | |||||
| failed during the Commit of block H, then `last_block_height = H-1` and | |||||
| `last_block_app_hash = <hash returned by Commit for block H-1, which is the hash in the header of block H>`. | |||||
| We now distinguish three heights, and describe how Tendermint syncs itself with | |||||
| the app. | |||||
| ``` | |||||
| storeBlockHeight = height of the last block Tendermint saw a commit for | |||||
| stateBlockHeight = height of the last block for which Tendermint completed all | |||||
| block processing and saved all ABCI results to disk | |||||
| appBlockHeight = height of the last block for which ABCI app succesfully | |||||
| completed Commit | |||||
| ``` | |||||
| Note we always have `storeBlockHeight >= stateBlockHeight` and `storeBlockHeight >= appBlockHeight` | |||||
| Note also we never call Commit on an ABCI app twice for the same height. | |||||
| The procedure is as follows. | |||||
| First, some simple start conditions: | |||||
| If `appBlockHeight == 0`, then call InitChain. | |||||
| If `storeBlockHeight == 0`, we're done. | |||||
| Now, some sanity checks: | |||||
| If `storeBlockHeight < appBlockHeight`, error | |||||
| If `storeBlockHeight < stateBlockHeight`, panic | |||||
| If `storeBlockHeight > stateBlockHeight+1`, panic | |||||
| Now, the meat: | |||||
| If `storeBlockHeight == stateBlockHeight && appBlockHeight < storeBlockHeight`, | |||||
| replay all blocks in full from `appBlockHeight` to `storeBlockHeight`. | |||||
| This happens if we completed processing the block, but the app forgot its height. | |||||
| If `storeBlockHeight == stateBlockHeight && appBlockHeight == storeBlockHeight`, we're done. | |||||
| This happens if we crashed at an opportune spot. | |||||
| If `storeBlockHeight == stateBlockHeight+1` | |||||
| This happens if we started processing the block but didn't finish. | |||||
| If `appBlockHeight < stateBlockHeight` | |||||
| replay all blocks in full from `appBlockHeight` to `storeBlockHeight-1`, | |||||
| and replay the block at `storeBlockHeight` using the WAL. | |||||
| This happens if the app forgot the last block it committed. | |||||
| If `appBlockHeight == stateBlockHeight`, | |||||
| replay the last block (storeBlockHeight) in full. | |||||
| This happens if we crashed before the app finished Commit | |||||
| If `appBlockHeight == storeBlockHeight` | |||||
| update the state using the saved ABCI responses but dont run the block against the real app. | |||||
| This happens if we crashed after the app finished Commit but before Tendermint saved the state. | |||||
+ 0
- 109
docs/spec/abci/client-server.md
View File
| @ -1,109 +0,0 @@ | |||||
| # Client and Server | |||||
| This section is for those looking to implement their own ABCI Server, perhaps in | |||||
| a new programming language. | |||||
| You are expected to have read [ABCI Methods and Types](./abci.md) and [ABCI | |||||
| Applications](./apps.md). | |||||
| ## Message Protocol | |||||
| The message protocol consists of pairs of requests and responses defined in the | |||||
| [protobuf file](https://github.com/tendermint/tendermint/blob/master/abci/types/types.proto). | |||||
| Some messages have no fields, while others may include byte-arrays, strings, integers, | |||||
| or custom protobuf types. | |||||
| For more details on protobuf, see the [documentation](https://developers.google.com/protocol-buffers/docs/overview). | |||||
| For each request, a server should respond with the corresponding | |||||
| response, where the order of requests is preserved in the order of | |||||
| responses. | |||||
| ## Server Implementations | |||||
| To use ABCI in your programming language of choice, there must be a ABCI | |||||
| server in that language. Tendermint supports three implementations of the ABCI, written in Go: | |||||
| - In-process (Golang only) | |||||
| - ABCI-socket | |||||
| - GRPC | |||||
| The latter two can be tested using the `abci-cli` by setting the `--abci` flag | |||||
| appropriately (ie. to `socket` or `grpc`). | |||||
| See examples, in various stages of maintenance, in | |||||
| [Go](https://github.com/tendermint/tendermint/tree/master/abci/server), | |||||
| [JavaScript](https://github.com/tendermint/js-abci), | |||||
| [Python](https://github.com/tendermint/tendermint/tree/master/abci/example/python3/abci), | |||||
| [C++](https://github.com/mdyring/cpp-tmsp), and | |||||
| [Java](https://github.com/jTendermint/jabci). | |||||
| ### In Process | |||||
| The simplest implementation uses function calls within Golang. | |||||
| This means ABCI applications written in Golang can be compiled with TendermintCore and run as a single binary. | |||||
| ### GRPC | |||||
| If GRPC is available in your language, this is the easiest approach, | |||||
| though it will have significant performance overhead. | |||||
| To get started with GRPC, copy in the [protobuf | |||||
| file](https://github.com/tendermint/tendermint/blob/master/abci/types/types.proto) | |||||
| and compile it using the GRPC plugin for your language. For instance, | |||||
| for golang, the command is `protoc --go_out=plugins=grpc:. types.proto`. | |||||
| See the [grpc documentation for more details](http://www.grpc.io/docs/). | |||||
| `protoc` will autogenerate all the necessary code for ABCI client and | |||||
| server in your language, including whatever interface your application | |||||
| must satisfy to be used by the ABCI server for handling requests. | |||||
| Note the length-prefixing used in the socket implementation (TSP) does not apply for GRPC. | |||||
| ### TSP | |||||
| Tendermint Socket Protocol is an asynchronous, raw socket server which provides ordered message passing over unix or tcp. | |||||
| Messages are serialized using Protobuf3 and length-prefixed with a [signed Varint](https://developers.google.com/protocol-buffers/docs/encoding?csw=1#signed-integers) | |||||
| If GRPC is not available in your language, or you require higher | |||||
| performance, or otherwise enjoy programming, you may implement your own | |||||
| ABCI server using the Tendermint Socket Protocol. The first step is still to auto-generate the relevant data | |||||
| types and codec in your language using `protoc`. In addition to being proto3 encoded, messages coming over | |||||
| the socket are length-prefixed to facilitate use as a streaming protocol. proto3 doesn't have an | |||||
| official length-prefix standard, so we use our own. The first byte in | |||||
| the prefix represents the length of the Big Endian encoded length. The | |||||
| remaining bytes in the prefix are the Big Endian encoded length. | |||||
| For example, if the proto3 encoded ABCI message is 0xDEADBEEF (4 | |||||
| bytes), the length-prefixed message is 0x0104DEADBEEF. If the proto3 | |||||
| encoded ABCI message is 65535 bytes long, the length-prefixed message | |||||
| would be like 0x02FFFF.... | |||||
| The benefit of using this `varint` encoding over the old version (where integers were encoded as `<len of len><big endian len>` is that | |||||
| it is the standard way to encode integers in Protobuf. It is also generally shorter. | |||||
| As noted above, this prefixing does not apply for GRPC. | |||||
| An ABCI server must also be able to support multiple connections, as | |||||
| Tendermint uses three connections. | |||||
| ### Async vs Sync | |||||
| The main ABCI server (ie. non-GRPC) provides ordered asynchronous messages. | |||||
| This is useful for DeliverTx and CheckTx, since it allows Tendermint to forward | |||||
| transactions to the app before it's finished processing previous ones. | |||||
| Thus, DeliverTx and CheckTx messages are sent asynchronously, while all other | |||||
| messages are sent synchronously. | |||||
| ## Client | |||||
| There are currently two use-cases for an ABCI client. One is a testing | |||||
| tool, as in the `abci-cli`, which allows ABCI requests to be sent via | |||||
| command line. The other is a consensus engine, such as Tendermint Core, | |||||
| which makes requests to the application every time a new transaction is | |||||
| received or a block is committed. | |||||
| It is unlikely that you will need to implement a client. For details of | |||||
| our client, see | |||||
| [here](https://github.com/tendermint/tendermint/tree/master/abci/client). | |||||
+ 0
- 350
docs/spec/blockchain/encoding.md
View File
| @ -1,350 +0,0 @@ | |||||
| # Encoding | |||||
| ## Amino | |||||
| Tendermint uses the proto3 derivative [Amino](https://github.com/tendermint/go-amino) for all data structures. | |||||
| Think of Amino as an object-oriented proto3 with native JSON support. | |||||
| The goal of the Amino encoding protocol is to bring parity between application | |||||
| logic objects and persistence objects. | |||||
| Please see the [Amino | |||||
| specification](https://github.com/tendermint/go-amino#amino-encoding-for-go) for | |||||
| more details. | |||||
| Notably, every object that satisfies an interface (eg. a particular kind of p2p message, | |||||
| or a particular kind of pubkey) is registered with a global name, the hash of | |||||
| which is included in the object's encoding as the so-called "prefix bytes". | |||||
| We define the `func AminoEncode(obj interface{}) []byte` function to take an | |||||
| arbitrary object and return the Amino encoded bytes. | |||||
| ## Byte Arrays | |||||
| The encoding of a byte array is simply the raw-bytes prefixed with the length of | |||||
| the array as a `UVarint` (what proto calls a `Varint`). | |||||
| For details on varints, see the [protobuf | |||||
| spec](https://developers.google.com/protocol-buffers/docs/encoding#varints). | |||||
| For example, the byte-array `[0xA, 0xB]` would be encoded as `0x020A0B`, | |||||
| while a byte-array containing 300 entires beginning with `[0xA, 0xB, ...]` would | |||||
| be encoded as `0xAC020A0B...` where `0xAC02` is the UVarint encoding of 300. | |||||
| ## Hashing | |||||
| Tendermint uses `SHA256` as its hash function. | |||||
| Objects are always Amino encoded before being hashed. | |||||
| So `SHA256(obj)` is short for `SHA256(AminoEncode(obj))`. | |||||
| ## Public Key Cryptography | |||||
| Tendermint uses Amino to distinguish between different types of private keys, | |||||
| public keys, and signatures. Additionally, for each public key, Tendermint | |||||
| defines an Address function that can be used as a more compact identifier in | |||||
| place of the public key. Here we list the concrete types, their names, | |||||
| and prefix bytes for public keys and signatures, as well as the address schemes | |||||
| for each PubKey. Note for brevity we don't | |||||
| include details of the private keys beyond their type and name, as they can be | |||||
| derived the same way as the others using Amino. | |||||
| All registered objects are encoded by Amino using a 4-byte PrefixBytes that | |||||
| uniquely identifies the object and includes information about its underlying | |||||
| type. For details on how PrefixBytes are computed, see the [Amino | |||||
| spec](https://github.com/tendermint/go-amino#computing-the-prefix-and-disambiguation-bytes). | |||||
| In what follows, we provide the type names and prefix bytes directly. | |||||
| Notice that when encoding byte-arrays, the length of the byte-array is appended | |||||
| to the PrefixBytes. Thus the encoding of a byte array becomes `<PrefixBytes> <Length> <ByteArray>`. In other words, to encode any type listed below you do not need to be | |||||
| familiar with amino encoding. | |||||
| You can simply use below table and concatenate Prefix || Length (of raw bytes) || raw bytes | |||||
| ( while || stands for byte concatenation here). | |||||
| | Type | Name | Prefix | Length | Notes | | |||||
| | ----------------------- | ---------------------------------- | ---------- | -------- | ----- | | |||||
| | PubKeyEd25519 | tendermint/PubKeyEd25519 | 0x1624DE64 | 0x20 | | | |||||
| | PubKeySecp256k1 | tendermint/PubKeySecp256k1 | 0xEB5AE987 | 0x21 | | | |||||
| | PrivKeyEd25519 | tendermint/PrivKeyEd25519 | 0xA3288910 | 0x40 | | | |||||
| | PrivKeySecp256k1 | tendermint/PrivKeySecp256k1 | 0xE1B0F79B | 0x20 | | | |||||
| | PubKeyMultisigThreshold | tendermint/PubKeyMultisigThreshold | 0x22C1F7E2 | variable | | | |||||
| ### Example | |||||
| For example, the 33-byte (or 0x21-byte in hex) Secp256k1 pubkey | |||||
| `020BD40F225A57ED383B440CF073BC5539D0341F5767D2BF2D78406D00475A2EE9` | |||||
| would be encoded as | |||||
| `EB5AE98721020BD40F225A57ED383B440CF073BC5539D0341F5767D2BF2D78406D00475A2EE9` | |||||
| ### Key Types | |||||
| Each type specifies it's own pubkey, address, and signature format. | |||||
| #### Ed25519 | |||||
| TODO: pubkey | |||||
| The address is the first 20-bytes of the SHA256 hash of the raw 32-byte public key: | |||||
| ``` | |||||
| address = SHA256(pubkey)[:20] | |||||
| ``` | |||||
| The signature is the raw 64-byte ED25519 signature. | |||||
| #### Secp256k1 | |||||
| TODO: pubkey | |||||
| The address is the RIPEMD160 hash of the SHA256 hash of the OpenSSL compressed public key: | |||||
| ``` | |||||
| address = RIPEMD160(SHA256(pubkey)) | |||||
| ``` | |||||
| This is the same as Bitcoin. | |||||
| The signature is the 64-byte concatenation of ECDSA `r` and `s` (ie. `r || s`), | |||||
| where `s` is lexicographically less than its inverse, to prevent malleability. | |||||
| This is like Ethereum, but without the extra byte for pubkey recovery, since | |||||
| Tendermint assumes the pubkey is always provided anyway. | |||||
| #### Multisig | |||||
| TODO | |||||
| ## Other Common Types | |||||
| ### BitArray | |||||
| The BitArray is used in some consensus messages to represent votes received from | |||||
| validators, or parts received in a block. It is represented | |||||
| with a struct containing the number of bits (`Bits`) and the bit-array itself | |||||
| encoded in base64 (`Elems`). | |||||
| ```go | |||||
| type BitArray struct { | |||||
| Bits int | |||||
| Elems []uint64 | |||||
| } | |||||
| ``` | |||||
| This type is easily encoded directly by Amino. | |||||
| Note BitArray receives a special JSON encoding in the form of `x` and `_` | |||||
| representing `1` and `0`. Ie. the BitArray `10110` would be JSON encoded as | |||||
| `"x_xx_"` | |||||
| ### Part | |||||
| Part is used to break up blocks into pieces that can be gossiped in parallel | |||||
| and securely verified using a Merkle tree of the parts. | |||||
| Part contains the index of the part (`Index`), the actual | |||||
| underlying data of the part (`Bytes`), and a Merkle proof that the part is contained in | |||||
| the set (`Proof`). | |||||
| ```go | |||||
| type Part struct { | |||||
| Index int | |||||
| Bytes []byte | |||||
| Proof SimpleProof | |||||
| } | |||||
| ``` | |||||
| See details of SimpleProof, below. | |||||
| ### MakeParts | |||||
| Encode an object using Amino and slice it into parts. | |||||
| Tendermint uses a part size of 65536 bytes, and allows a maximum of 1601 parts | |||||
| (see `types.MaxBlockPartsCount`). This corresponds to the hard-coded block size | |||||
| limit of 100MB. | |||||
| ```go | |||||
| func MakeParts(block Block) []Part | |||||
| ``` | |||||
| ## Merkle Trees | |||||
| For an overview of Merkle trees, see | |||||
| [wikipedia](https://en.wikipedia.org/wiki/Merkle_tree) | |||||
| We use the RFC 6962 specification of a merkle tree, with sha256 as the hash function. | |||||
| Merkle trees are used throughout Tendermint to compute a cryptographic digest of a data structure. | |||||
| The differences between RFC 6962 and the simplest form a merkle tree are that: | |||||
| 1. leaf nodes and inner nodes have different hashes. | |||||
| This is for "second pre-image resistance", to prevent the proof to an inner node being valid as the proof of a leaf. | |||||
| The leaf nodes are `SHA256(0x00 || leaf_data)`, and inner nodes are `SHA256(0x01 || left_hash || right_hash)`. | |||||
| 2. When the number of items isn't a power of two, the left half of the tree is as big as it could be. | |||||
| (The largest power of two less than the number of items) This allows new leaves to be added with less | |||||
| recomputation. For example: | |||||
| ``` | |||||
| Simple Tree with 6 items Simple Tree with 7 items | |||||
| * * | |||||
| / \ / \ | |||||
| / \ / \ | |||||
| / \ / \ | |||||
| / \ / \ | |||||
| * * * * | |||||
| / \ / \ / \ / \ | |||||
| / \ / \ / \ / \ | |||||
| / \ / \ / \ / \ | |||||
| * * h4 h5 * * * h6 | |||||
| / \ / \ / \ / \ / \ | |||||
| h0 h1 h2 h3 h0 h1 h2 h3 h4 h5 | |||||
| ``` | |||||
| ### MerkleRoot | |||||
| The function `MerkleRoot` is a simple recursive function defined as follows: | |||||
| ```go | |||||
| // SHA256(0x00 || leaf) | |||||
| func leafHash(leaf []byte) []byte { | |||||
| return tmhash.Sum(append(0x00, leaf...)) | |||||
| } | |||||
| // SHA256(0x01 || left || right) | |||||
| func innerHash(left []byte, right []byte) []byte { | |||||
| return tmhash.Sum(append(0x01, append(left, right...)...)) | |||||
| } | |||||
| // largest power of 2 less than k | |||||
| func getSplitPoint(k int) { ... } | |||||
| func MerkleRoot(items [][]byte) []byte{ | |||||
| switch len(items) { | |||||
| case 0: | |||||
| return nil | |||||
| case 1: | |||||
| return leafHash(items[0]) | |||||
| default: | |||||
| k := getSplitPoint(len(items)) | |||||
| left := MerkleRoot(items[:k]) | |||||
| right := MerkleRoot(items[k:]) | |||||
| return innerHash(left, right) | |||||
| } | |||||
| } | |||||
| ``` | |||||
| Note: `MerkleRoot` operates on items which are arbitrary byte arrays, not | |||||
| necessarily hashes. For items which need to be hashed first, we introduce the | |||||
| `Hashes` function: | |||||
| ``` | |||||
| func Hashes(items [][]byte) [][]byte { | |||||
| return SHA256 of each item | |||||
| } | |||||
| ``` | |||||
| Note: we will abuse notion and invoke `MerkleRoot` with arguments of type `struct` or type `[]struct`. | |||||
| For `struct` arguments, we compute a `[][]byte` containing the amino encoding of each | |||||
| field in the struct, in the same order the fields appear in the struct. | |||||
| For `[]struct` arguments, we compute a `[][]byte` by amino encoding the individual `struct` elements. | |||||
| ### Simple Merkle Proof | |||||
| Proof that a leaf is in a Merkle tree is composed as follows: | |||||
| ```golang | |||||
| type SimpleProof struct { | |||||
| Total int | |||||
| Index int | |||||
| LeafHash []byte | |||||
| Aunts [][]byte | |||||
| } | |||||
| ``` | |||||
| Which is verified as follows: | |||||
| ```golang | |||||
| func (proof SimpleProof) Verify(rootHash []byte, leaf []byte) bool { | |||||
| assert(proof.LeafHash, leafHash(leaf) | |||||
| computedHash := computeHashFromAunts(proof.Index, proof.Total, proof.LeafHash, proof.Aunts) | |||||
| return computedHash == rootHash | |||||
| } | |||||
| func computeHashFromAunts(index, total int, leafHash []byte, innerHashes [][]byte) []byte{ | |||||
| assert(index < total && index >= 0 && total > 0) | |||||
| if total == 1{ | |||||
| assert(len(proof.Aunts) == 0) | |||||
| return leafHash | |||||
| } | |||||
| assert(len(innerHashes) > 0) | |||||
| numLeft := getSplitPoint(total) // largest power of 2 less than total | |||||
| if index < numLeft { | |||||
| leftHash := computeHashFromAunts(index, numLeft, leafHash, innerHashes[:len(innerHashes)-1]) | |||||
| assert(leftHash != nil) | |||||
| return innerHash(leftHash, innerHashes[len(innerHashes)-1]) | |||||
| } | |||||
| rightHash := computeHashFromAunts(index-numLeft, total-numLeft, leafHash, innerHashes[:len(innerHashes)-1]) | |||||
| assert(rightHash != nil) | |||||
| return innerHash(innerHashes[len(innerHashes)-1], rightHash) | |||||
| } | |||||
| ``` | |||||
| The number of aunts is limited to 100 (`MaxAunts`) to protect the node against DOS attacks. | |||||
| This limits the tree size to 2^100 leaves, which should be sufficient for any | |||||
| conceivable purpose. | |||||
| ### IAVL+ Tree | |||||
| Because Tendermint only uses a Simple Merkle Tree, application developers are expect to use their own Merkle tree in their applications. For example, the IAVL+ Tree - an immutable self-balancing binary tree for persisting application state is used by the [Cosmos SDK](https://github.com/cosmos/cosmos-sdk/blob/ae77f0080a724b159233bd9b289b2e91c0de21b5/docs/interfaces/lite/specification.md) | |||||
| ## JSON | |||||
| ### Amino | |||||
| Amino also supports JSON encoding - registered types are simply encoded as: | |||||
| ``` | |||||
| { | |||||
| "type": "<amino type name>", | |||||
| "value": <JSON> | |||||
| } | |||||
| ``` | |||||
| For instance, an ED25519 PubKey would look like: | |||||
| ``` | |||||
| { | |||||
| "type": "tendermint/PubKeyEd25519", | |||||
| "value": "uZ4h63OFWuQ36ZZ4Bd6NF+/w9fWUwrOncrQsackrsTk=" | |||||
| } | |||||
| ``` | |||||
| Where the `"value"` is the base64 encoding of the raw pubkey bytes, and the | |||||
| `"type"` is the amino name for Ed25519 pubkeys. | |||||
| ### Signed Messages | |||||
| Signed messages (eg. votes, proposals) in the consensus are encoded using Amino. | |||||
| When signing, the elements of a message are re-ordered so the fixed-length fields | |||||
| are first, making it easy to quickly check the type, height, and round. | |||||
| The `ChainID` is also appended to the end. | |||||
| We call this encoding the SignBytes. For instance, SignBytes for a vote is the Amino encoding of the following struct: | |||||
| ```go | |||||
| type CanonicalVote struct { | |||||
| Type byte | |||||
| Height int64 `binary:"fixed64"` | |||||
| Round int64 `binary:"fixed64"` | |||||
| BlockID CanonicalBlockID | |||||
| Timestamp time.Time | |||||
| ChainID string | |||||
| } | |||||
| ``` | |||||
| The field ordering and the fixed sized encoding for the first three fields is optimized to ease parsing of SignBytes | |||||
| in HSMs. It creates fixed offsets for relevant fields that need to be read in this context. | |||||
| For more details, see the [signing spec](../consensus/signing.md). | |||||
| Also, see the motivating discussion in | |||||
| [#1622](https://github.com/tendermint/tendermint/issues/1622). | |||||
+ 0
- 5
docs/spec/blockchain/readme.md
View File
| @ -1,5 +0,0 @@ | |||||
| --- | |||||
| cards: true | |||||
| --- | |||||
| # Blockchain | |||||
+ 0
- 144
docs/spec/blockchain/state.md
View File
| @ -1,144 +0,0 @@ | |||||
| # State | |||||
| ## State | |||||
| The state contains information whose cryptographic digest is included in block headers, and thus is | |||||
| necessary for validating new blocks. For instance, the validators set and the results of | |||||
| transactions are never included in blocks, but their Merkle roots are - the state keeps track of them. | |||||
| Note that the `State` object itself is an implementation detail, since it is never | |||||
| included in a block or gossipped over the network, and we never compute | |||||
| its hash. Thus we do not include here details of how the `State` object is | |||||
| persisted or queried. That said, the types it contains are part of the specification, since | |||||
| their Merkle roots are included in blocks and their values are used in | |||||
| validation. | |||||
| ```go | |||||
| type State struct { | |||||
| Version Version | |||||
| LastResults []Result | |||||
| AppHash []byte | |||||
| LastValidators []Validator | |||||
| Validators []Validator | |||||
| NextValidators []Validator | |||||
| ConsensusParams ConsensusParams | |||||
| } | |||||
| ``` | |||||
| Note there is a hard-coded limit of 10000 validators. This is inherited from the | |||||
| limit on the number of votes in a commit. | |||||
| ### Result | |||||
| ```go | |||||
| type Result struct { | |||||
| Code uint32 | |||||
| Data []byte | |||||
| } | |||||
| ``` | |||||
| `Result` is the result of executing a transaction against the application. | |||||
| It returns a result code and an arbitrary byte array (ie. a return value). | |||||
| NOTE: the Result needs to be updated to include more fields returned from | |||||
| processing transactions, like gas variables and tags - see | |||||
| [issue 1007](https://github.com/tendermint/tendermint/issues/1007). | |||||
| ### Validator | |||||
| A validator is an active participant in the consensus with a public key and a voting power. | |||||
| Validator's also contain an address field, which is a hash digest of the PubKey. | |||||
| ```go | |||||
| type Validator struct { | |||||
| Address []byte | |||||
| PubKey PubKey | |||||
| VotingPower int64 | |||||
| } | |||||
| ``` | |||||
| When hashing the Validator struct, the address is not included, | |||||
| because it is redundant with the pubkey. | |||||
| The `state.Validators`, `state.LastValidators`, and `state.NextValidators`, must always be sorted by validator address, | |||||
| so that there is a canonical order for computing the MerkleRoot. | |||||
| We also define a `TotalVotingPower` function, to return the total voting power: | |||||
| ```go | |||||
| func TotalVotingPower(vals []Validators) int64{ | |||||
| sum := 0 | |||||
| for v := range vals{ | |||||
| sum += v.VotingPower | |||||
| } | |||||
| return sum | |||||
| } | |||||
| ``` | |||||
| ### ConsensusParams | |||||
| ConsensusParams define various limits for blockchain data structures. | |||||
| Like validator sets, they are set during genesis and can be updated by the application through ABCI. | |||||
| When hashed, only a subset of the params are included, to allow the params to | |||||
| evolve without breaking the header. | |||||
| ```go | |||||
| type ConsensusParams struct { | |||||
| Block | |||||
| Evidence | |||||
| Validator | |||||
| } | |||||
| type hashedParams struct { | |||||
| BlockMaxBytes int64 | |||||
| BlockMaxGas int64 | |||||
| } | |||||
| func (params ConsensusParams) Hash() []byte { | |||||
| SHA256(hashedParams{ | |||||
| BlockMaxBytes: params.Block.MaxBytes, | |||||
| BlockMaxGas: params.Block.MaxGas, | |||||
| }) | |||||
| } | |||||
| type BlockParams struct { | |||||
| MaxBytes int64 | |||||
| MaxGas int64 | |||||
| TimeIotaMs int64 | |||||
| } | |||||
| type EvidenceParams struct { | |||||
| MaxAge int64 | |||||
| } | |||||
| type ValidatorParams struct { | |||||
| PubKeyTypes []string | |||||
| } | |||||
| ``` | |||||
| #### Block | |||||
| The total size of a block is limited in bytes by the `ConsensusParams.Block.MaxBytes`. | |||||
| Proposed blocks must be less than this size, and will be considered invalid | |||||
| otherwise. | |||||
| Blocks should additionally be limited by the amount of "gas" consumed by the | |||||
| transactions in the block, though this is not yet implemented. | |||||
| The minimal time between consecutive blocks is controlled by the | |||||
| `ConsensusParams.Block.TimeIotaMs`. | |||||
| #### Evidence | |||||
| For evidence in a block to be valid, it must satisfy: | |||||
| ``` | |||||
| block.Header.Height - evidence.Height < ConsensusParams.Evidence.MaxAge | |||||
| ``` | |||||
| #### Validator | |||||
| Validators from genesis file and `ResponseEndBlock` must have pubkeys of type ∈ | |||||
| `ConsensusParams.Validator.PubKeyTypes`. | |||||
+ 0
- 3
docs/spec/consensus/abci.md
View File
| @ -1,3 +0,0 @@ | |||||
| # ABCI | |||||
| [Moved](../software/abci.md) | |||||
+ 0
- 54
docs/spec/consensus/bft-time.md
View File
| @ -1,54 +0,0 @@ | |||||
| # BFT Time | |||||
| Tendermint provides a deterministic, Byzantine fault-tolerant, source of time. | |||||
| Time in Tendermint is defined with the Time field of the block header. | |||||
| It satisfies the following properties: | |||||
| - Time Monotonicity: Time is monotonically increasing, i.e., given | |||||
| a header H1 for height h1 and a header H2 for height `h2 = h1 + 1`, `H1.Time < H2.Time`. | |||||
| - Time Validity: Given a set of Commit votes that forms the `block.LastCommit` field, a range of | |||||
| valid values for the Time field of the block header is defined only by | |||||
| Precommit messages (from the LastCommit field) sent by correct processes, i.e., | |||||
| a faulty process cannot arbitrarily increase the Time value. | |||||
| In the context of Tendermint, time is of type int64 and denotes UNIX time in milliseconds, i.e., | |||||
| corresponds to the number of milliseconds since January 1, 1970. Before defining rules that need to be enforced by the | |||||
| Tendermint consensus protocol, so the properties above holds, we introduce the following definition: | |||||
| - median of a Commit is equal to the median of `Vote.Time` fields of the `Vote` messages, | |||||
| where the value of `Vote.Time` is counted number of times proportional to the process voting power. As in Tendermint | |||||
| the voting power is not uniform (one process one vote), a vote message is actually an aggregator of the same votes whose | |||||
| number is equal to the voting power of the process that has casted the corresponding votes message. | |||||
| Let's consider the following example: | |||||
| - we have four processes p1, p2, p3 and p4, with the following voting power distribution (p1, 23), (p2, 27), (p3, 10) | |||||
| and (p4, 10). The total voting power is 70 (`N = 3f+1`, where `N` is the total voting power, and `f` is the maximum voting | |||||
| power of the faulty processes), so we assume that the faulty processes have at most 23 of voting power. | |||||
| Furthermore, we have the following vote messages in some LastCommit field (we ignore all fields except Time field): | |||||
| - (p1, 100), (p2, 98), (p3, 1000), (p4, 500). We assume that p3 and p4 are faulty processes. Let's assume that the | |||||
| `block.LastCommit` message contains votes of processes p2, p3 and p4. Median is then chosen the following way: | |||||
| the value 98 is counted 27 times, the value 1000 is counted 10 times and the value 500 is counted also 10 times. | |||||
| So the median value will be the value 98. No matter what set of messages with at least `2f+1` voting power we | |||||
| choose, the median value will always be between the values sent by correct processes. | |||||
| We ensure Time Monotonicity and Time Validity properties by the following rules: | |||||
| - let rs denotes `RoundState` (consensus internal state) of some process. Then | |||||
| `rs.ProposalBlock.Header.Time == median(rs.LastCommit) && | |||||
| rs.Proposal.Timestamp == rs.ProposalBlock.Header.Time`. | |||||
| - Furthermore, when creating the `vote` message, the following rules for determining `vote.Time` field should hold: | |||||
| - if `rs.LockedBlock` is defined then | |||||
| `vote.Time = max(rs.LockedBlock.Timestamp + config.BlockTimeIota, time.Now())`, where `time.Now()` | |||||
| denotes local Unix time in milliseconds, and `config.BlockTimeIota` is a configuration parameter that corresponds | |||||
| to the minimum timestamp increment of the next block. | |||||
| - else if `rs.Proposal` is defined then | |||||
| `vote.Time = max(rs.Proposal.Timestamp + config.BlockTimeIota, time.Now())`, | |||||
| - otherwise, `vote.Time = time.Now())`. In this case vote is for `nil` so it is not taken into account for | |||||
| the timestamp of the next block. | |||||
+ 0
- 335
docs/spec/consensus/consensus.md
View File
| @ -1,335 +0,0 @@ | |||||
| # Byzantine Consensus Algorithm | |||||
| ## Terms | |||||
| - The network is composed of optionally connected _nodes_. Nodes | |||||
| directly connected to a particular node are called _peers_. | |||||
| - The consensus process in deciding the next block (at some _height_ | |||||
| `H`) is composed of one or many _rounds_. | |||||
| - `NewHeight`, `Propose`, `Prevote`, `Precommit`, and `Commit` | |||||
| represent state machine states of a round. (aka `RoundStep` or | |||||
| just "step"). | |||||
| - A node is said to be _at_ a given height, round, and step, or at | |||||
| `(H,R,S)`, or at `(H,R)` in short to omit the step. | |||||
| - To _prevote_ or _precommit_ something means to broadcast a [prevote | |||||
| vote](https://godoc.org/github.com/tendermint/tendermint/types#Vote) | |||||
| or [first precommit | |||||
| vote](https://godoc.org/github.com/tendermint/tendermint/types#FirstPrecommit) | |||||
| for something. | |||||
| - A vote _at_ `(H,R)` is a vote signed with the bytes for `H` and `R` | |||||
| included in its [sign-bytes](../blockchain/blockchain.md#vote). | |||||
| - _+2/3_ is short for "more than 2/3" | |||||
| - _1/3+_ is short for "1/3 or more" | |||||
| - A set of +2/3 of prevotes for a particular block or `<nil>` at | |||||
| `(H,R)` is called a _proof-of-lock-change_ or _PoLC_ for short. | |||||
| ## State Machine Overview | |||||
| At each height of the blockchain a round-based protocol is run to | |||||
| determine the next block. Each round is composed of three _steps_ | |||||
| (`Propose`, `Prevote`, and `Precommit`), along with two special steps | |||||
| `Commit` and `NewHeight`. | |||||
| In the optimal scenario, the order of steps is: | |||||
| ``` | |||||
| NewHeight -> (Propose -> Prevote -> Precommit)+ -> Commit -> NewHeight ->... | |||||
| ``` | |||||
| The sequence `(Propose -> Prevote -> Precommit)` is called a _round_. | |||||
| There may be more than one round required to commit a block at a given | |||||
| height. Examples for why more rounds may be required include: | |||||
| - The designated proposer was not online. | |||||
| - The block proposed by the designated proposer was not valid. | |||||
| - The block proposed by the designated proposer did not propagate | |||||
| in time. | |||||
| - The block proposed was valid, but +2/3 of prevotes for the proposed | |||||
| block were not received in time for enough validator nodes by the | |||||
| time they reached the `Precommit` step. Even though +2/3 of prevotes | |||||
| are necessary to progress to the next step, at least one validator | |||||
| may have voted `<nil>` or maliciously voted for something else. | |||||
| - The block proposed was valid, and +2/3 of prevotes were received for | |||||
| enough nodes, but +2/3 of precommits for the proposed block were not | |||||
| received for enough validator nodes. | |||||
| Some of these problems are resolved by moving onto the next round & | |||||
| proposer. Others are resolved by increasing certain round timeout | |||||
| parameters over each successive round. | |||||
| ## State Machine Diagram | |||||
| ``` | |||||
| +-------------------------------------+ | |||||
| v |(Wait til `CommmitTime+timeoutCommit`) | |||||
| +-----------+ +-----+-----+ | |||||
| +----------> | Propose +--------------+ | NewHeight | | |||||
| | +-----------+ | +-----------+ | |||||
| | | ^ | |||||
| |(Else, after timeoutPrecommit) v | | |||||
| +-----+-----+ +-----------+ | | |||||
| | Precommit | <------------------------+ Prevote | | | |||||
| +-----+-----+ +-----------+ | | |||||
| |(When +2/3 Precommits for block found) | | |||||
| v | | |||||
| +--------------------------------------------------------------------+ | |||||
| | Commit | | |||||
| | | | |||||
| | * Set CommitTime = now; | | |||||
| | * Wait for block, then stage/save/commit block; | | |||||
| +--------------------------------------------------------------------+ | |||||
| ``` | |||||
| # Background Gossip | |||||
| A node may not have a corresponding validator private key, but it | |||||
| nevertheless plays an active role in the consensus process by relaying | |||||
| relevant meta-data, proposals, blocks, and votes to its peers. A node | |||||
| that has the private keys of an active validator and is engaged in | |||||
| signing votes is called a _validator-node_. All nodes (not just | |||||
| validator-nodes) have an associated state (the current height, round, | |||||
| and step) and work to make progress. | |||||
| Between two nodes there exists a `Connection`, and multiplexed on top of | |||||
| this connection are fairly throttled `Channel`s of information. An | |||||
| epidemic gossip protocol is implemented among some of these channels to | |||||
| bring peers up to speed on the most recent state of consensus. For | |||||
| example, | |||||
| - Nodes gossip `PartSet` parts of the current round's proposer's | |||||
| proposed block. A LibSwift inspired algorithm is used to quickly | |||||
| broadcast blocks across the gossip network. | |||||
| - Nodes gossip prevote/precommit votes. A node `NODE_A` that is ahead | |||||
| of `NODE_B` can send `NODE_B` prevotes or precommits for `NODE_B`'s | |||||
| current (or future) round to enable it to progress forward. | |||||
| - Nodes gossip prevotes for the proposed PoLC (proof-of-lock-change) | |||||
| round if one is proposed. | |||||
| - Nodes gossip to nodes lagging in blockchain height with block | |||||
| [commits](https://godoc.org/github.com/tendermint/tendermint/types#Commit) | |||||
| for older blocks. | |||||
| - Nodes opportunistically gossip `HasVote` messages to hint peers what | |||||
| votes it already has. | |||||
| - Nodes broadcast their current state to all neighboring peers. (but | |||||
| is not gossiped further) | |||||
| There's more, but let's not get ahead of ourselves here. | |||||
| ## Proposals | |||||
| A proposal is signed and published by the designated proposer at each | |||||
| round. The proposer is chosen by a deterministic and non-choking round | |||||
| robin selection algorithm that selects proposers in proportion to their | |||||
| voting power (see | |||||
| [implementation](https://github.com/tendermint/tendermint/blob/master/types/validator_set.go)). | |||||
| A proposal at `(H,R)` is composed of a block and an optional latest | |||||
| `PoLC-Round < R` which is included iff the proposer knows of one. This | |||||
| hints the network to allow nodes to unlock (when safe) to ensure the | |||||
| liveness property. | |||||
| ## State Machine Spec | |||||
| ### Propose Step (height:H,round:R) | |||||
| Upon entering `Propose`: | |||||
| - The designated proposer proposes a block at `(H,R)`. | |||||
| The `Propose` step ends: | |||||
| - After `timeoutProposeR` after entering `Propose`. --> goto | |||||
| `Prevote(H,R)` | |||||
| - After receiving proposal block and all prevotes at `PoLC-Round`. --> | |||||
| goto `Prevote(H,R)` | |||||
| - After [common exit conditions](#common-exit-conditions) | |||||
| ### Prevote Step (height:H,round:R) | |||||
| Upon entering `Prevote`, each validator broadcasts its prevote vote. | |||||
| - First, if the validator is locked on a block since `LastLockRound` | |||||
| but now has a PoLC for something else at round `PoLC-Round` where | |||||
| `LastLockRound < PoLC-Round < R`, then it unlocks. | |||||
| - If the validator is still locked on a block, it prevotes that. | |||||
| - Else, if the proposed block from `Propose(H,R)` is good, it | |||||
| prevotes that. | |||||
| - Else, if the proposal is invalid or wasn't received on time, it | |||||
| prevotes `<nil>`. | |||||
| The `Prevote` step ends: | |||||
| - After +2/3 prevotes for a particular block or `<nil>`. -->; goto | |||||
| `Precommit(H,R)` | |||||
| - After `timeoutPrevote` after receiving any +2/3 prevotes. --> goto | |||||
| `Precommit(H,R)` | |||||
| - After [common exit conditions](#common-exit-conditions) | |||||
| ### Precommit Step (height:H,round:R) | |||||
| Upon entering `Precommit`, each validator broadcasts its precommit vote. | |||||
| - If the validator has a PoLC at `(H,R)` for a particular block `B`, it | |||||
| (re)locks (or changes lock to) and precommits `B` and sets | |||||
| `LastLockRound = R`. | |||||
| - Else, if the validator has a PoLC at `(H,R)` for `<nil>`, it unlocks | |||||
| and precommits `<nil>`. | |||||
| - Else, it keeps the lock unchanged and precommits `<nil>`. | |||||
| A precommit for `<nil>` means "I didn’t see a PoLC for this round, but I | |||||
| did get +2/3 prevotes and waited a bit". | |||||
| The Precommit step ends: | |||||
| - After +2/3 precommits for `<nil>`. --> goto `Propose(H,R+1)` | |||||
| - After `timeoutPrecommit` after receiving any +2/3 precommits. --> goto | |||||
| `Propose(H,R+1)` | |||||
| - After [common exit conditions](#common-exit-conditions) | |||||
| ### Common exit conditions | |||||
| - After +2/3 precommits for a particular block. --> goto | |||||
| `Commit(H)` | |||||
| - After any +2/3 prevotes received at `(H,R+x)`. --> goto | |||||
| `Prevote(H,R+x)` | |||||
| - After any +2/3 precommits received at `(H,R+x)`. --> goto | |||||
| `Precommit(H,R+x)` | |||||
| ### Commit Step (height:H) | |||||
| - Set `CommitTime = now()` | |||||
| - Wait until block is received. --> goto `NewHeight(H+1)` | |||||
| ### NewHeight Step (height:H) | |||||
| - Move `Precommits` to `LastCommit` and increment height. | |||||
| - Set `StartTime = CommitTime+timeoutCommit` | |||||
| - Wait until `StartTime` to receive straggler commits. --> goto | |||||
| `Propose(H,0)` | |||||
| ## Proofs | |||||
| ### Proof of Safety | |||||
| Assume that at most -1/3 of the voting power of validators is byzantine. | |||||
| If a validator commits block `B` at round `R`, it's because it saw +2/3 | |||||
| of precommits at round `R`. This implies that 1/3+ of honest nodes are | |||||
| still locked at round `R' > R`. These locked validators will remain | |||||
| locked until they see a PoLC at `R' > R`, but this won't happen because | |||||
| 1/3+ are locked and honest, so at most -2/3 are available to vote for | |||||
| anything other than `B`. | |||||
| ### Proof of Liveness | |||||
| If 1/3+ honest validators are locked on two different blocks from | |||||
| different rounds, a proposers' `PoLC-Round` will eventually cause nodes | |||||
| locked from the earlier round to unlock. Eventually, the designated | |||||
| proposer will be one that is aware of a PoLC at the later round. Also, | |||||
| `timeoutProposalR` increments with round `R`, while the size of a | |||||
| proposal are capped, so eventually the network is able to "fully gossip" | |||||
| the whole proposal (e.g. the block & PoLC). | |||||
| ### Proof of Fork Accountability | |||||
| Define the JSet (justification-vote-set) at height `H` of a validator | |||||
| `V1` to be all the votes signed by the validator at `H` along with | |||||
| justification PoLC prevotes for each lock change. For example, if `V1` | |||||
| signed the following precommits: `Precommit(B1 @ round 0)`, | |||||
| `Precommit(<nil> @ round 1)`, `Precommit(B2 @ round 4)` (note that no | |||||
| precommits were signed for rounds 2 and 3, and that's ok), | |||||
| `Precommit(B1 @ round 0)` must be justified by a PoLC at round 0, and | |||||
| `Precommit(B2 @ round 4)` must be justified by a PoLC at round 4; but | |||||
| the precommit for `<nil>` at round 1 is not a lock-change by definition | |||||
| so the JSet for `V1` need not include any prevotes at round 1, 2, or 3 | |||||
| (unless `V1` happened to have prevoted for those rounds). | |||||
| Further, define the JSet at height `H` of a set of validators `VSet` to | |||||
| be the union of the JSets for each validator in `VSet`. For a given | |||||
| commit by honest validators at round `R` for block `B` we can construct | |||||
| a JSet to justify the commit for `B` at `R`. We say that a JSet | |||||
| _justifies_ a commit at `(H,R)` if all the committers (validators in the | |||||
| commit-set) are each justified in the JSet with no duplicitous vote | |||||
| signatures (by the committers). | |||||
| - **Lemma**: When a fork is detected by the existence of two | |||||
| conflicting [commits](../blockchain/blockchain.md#commit), the | |||||
| union of the JSets for both commits (if they can be compiled) must | |||||
| include double-signing by at least 1/3+ of the validator set. | |||||
| **Proof**: The commit cannot be at the same round, because that | |||||
| would immediately imply double-signing by 1/3+. Take the union of | |||||
| the JSets of both commits. If there is no double-signing by at least | |||||
| 1/3+ of the validator set in the union, then no honest validator | |||||
| could have precommitted any different block after the first commit. | |||||
| Yet, +2/3 did. Reductio ad absurdum. | |||||
| As a corollary, when there is a fork, an external process can determine | |||||
| the blame by requiring each validator to justify all of its round votes. | |||||
| Either we will find 1/3+ who cannot justify at least one of their votes, | |||||
| and/or, we will find 1/3+ who had double-signed. | |||||
| ### Alternative algorithm | |||||
| Alternatively, we can take the JSet of a commit to be the "full commit". | |||||
| That is, if light clients and validators do not consider a block to be | |||||
| committed unless the JSet of the commit is also known, then we get the | |||||
| desirable property that if there ever is a fork (e.g. there are two | |||||
| conflicting "full commits"), then 1/3+ of the validators are immediately | |||||
| punishable for double-signing. | |||||
| There are many ways to ensure that the gossip network efficiently share | |||||
| the JSet of a commit. One solution is to add a new message type that | |||||
| tells peers that this node has (or does not have) a +2/3 majority for B | |||||
| (or) at (H,R), and a bitarray of which votes contributed towards that | |||||
| majority. Peers can react by responding with appropriate votes. | |||||
| We will implement such an algorithm for the next iteration of the | |||||
| Tendermint consensus protocol. | |||||
| Other potential improvements include adding more data in votes such as | |||||
| the last known PoLC round that caused a lock change, and the last voted | |||||
| round/step (or, we may require that validators not skip any votes). This | |||||
| may make JSet verification/gossip logic easier to implement. | |||||
| ### Censorship Attacks | |||||
| Due to the definition of a block | |||||
| [commit](../../tendermint-core/validators.md#commit-a-block), any 1/3+ coalition of | |||||
| validators can halt the blockchain by not broadcasting their votes. Such | |||||
| a coalition can also censor particular transactions by rejecting blocks | |||||
| that include these transactions, though this would result in a | |||||
| significant proportion of block proposals to be rejected, which would | |||||
| slow down the rate of block commits of the blockchain, reducing its | |||||
| utility and value. The malicious coalition might also broadcast votes in | |||||
| a trickle so as to grind blockchain block commits to a near halt, or | |||||
| engage in any combination of these attacks. | |||||
| If a global active adversary were also involved, it can partition the | |||||
| network in such a way that it may appear that the wrong subset of | |||||
| validators were responsible for the slowdown. This is not just a | |||||
| limitation of Tendermint, but rather a limitation of all consensus | |||||
| protocols whose network is potentially controlled by an active | |||||
| adversary. | |||||
| ### Overcoming Forks and Censorship Attacks | |||||
| For these types of attacks, a subset of the validators through external | |||||
| means should coordinate to sign a reorg-proposal that chooses a fork | |||||
| (and any evidence thereof) and the initial subset of validators with | |||||
| their signatures. Validators who sign such a reorg-proposal forego its | |||||
| collateral on all other forks. Clients should verify the signatures on | |||||
| the reorg-proposal, verify any evidence, and make a judgement or prompt | |||||
| the end-user for a decision. For example, a phone wallet app may prompt | |||||
| the user with a security warning, while a refrigerator may accept any | |||||
| reorg-proposal signed by +1/2 of the original validators. | |||||
| No non-synchronous Byzantine fault-tolerant algorithm can come to | |||||
| consensus when 1/3+ of validators are dishonest, yet a fork assumes that | |||||
| 1/3+ of validators have already been dishonest by double-signing or | |||||
| lock-changing without justification. So, signing the reorg-proposal is a | |||||
| coordination problem that cannot be solved by any non-synchronous | |||||
| protocol (i.e. automatically, and without making assumptions about the | |||||
| reliability of the underlying network). It must be provided by means | |||||
| external to the weakly-synchronous Tendermint consensus algorithm. For | |||||
| now, we leave the problem of reorg-proposal coordination to human | |||||
| coordination via internet media. Validators must take care to ensure | |||||
| that there are no significant network partitions, to avoid situations | |||||
| where two conflicting reorg-proposals are signed. | |||||
| Assuming that the external coordination medium and protocol is robust, | |||||
| it follows that forks are less of a concern than [censorship | |||||
| attacks](#censorship-attacks). | |||||
+ 0
- 42
docs/spec/consensus/creating-proposal.md
View File
| @ -1,42 +0,0 @@ | |||||
| # Creating a proposal | |||||
| A block consists of a header, transactions, votes (the commit), | |||||
| and a list of evidence of malfeasance (ie. signing conflicting votes). | |||||
| We include no more than 1/10th of the maximum block size | |||||
| (`ConsensusParams.Block.MaxBytes`) of evidence with each block. | |||||
| ## Reaping transactions from the mempool | |||||
| When we reap transactions from the mempool, we calculate maximum data | |||||
| size by subtracting maximum header size (`MaxHeaderBytes`), the maximum | |||||
| amino overhead for a block (`MaxAminoOverheadForBlock`), the size of | |||||
| the last commit (if present) and evidence (if present). While reaping | |||||
| we account for amino overhead for each transaction. | |||||
| ```go | |||||
| func MaxDataBytes(maxBytes int64, valsCount, evidenceCount int) int64 { | |||||
| return maxBytes - | |||||
| MaxAminoOverheadForBlock - | |||||
| MaxHeaderBytes - | |||||
| int64(valsCount)*MaxVoteBytes - | |||||
| int64(evidenceCount)*MaxEvidenceBytes | |||||
| } | |||||
| ``` | |||||
| ## Validating transactions in the mempool | |||||
| Before we accept a transaction in the mempool, we check if it's size is no more | |||||
| than {MaxDataSize}. {MaxDataSize} is calculated using the same formula as | |||||
| above, except because the evidence size is unknown at the moment, we subtract | |||||
| maximum evidence size (1/10th of the maximum block size). | |||||
| ```go | |||||
| func MaxDataBytesUnknownEvidence(maxBytes int64, valsCount int) int64 { | |||||
| return maxBytes - | |||||
| MaxAminoOverheadForBlock - | |||||
| MaxHeaderBytes - | |||||
| int64(valsCount)*MaxVoteBytes - | |||||
| MaxEvidenceBytesPerBlock(maxBytes) | |||||
| } | |||||
| ``` | |||||
+ 0
- 319
docs/spec/consensus/fork-accountability.md
View File
| @ -1,319 +0,0 @@ | |||||
| # Fork accountability -- Problem statement and attacks | |||||
| ## Problem Statement | |||||
| Tendermint consensus guarantees the following specifications for all heights: | |||||
| * agreement -- no two correct full nodes decide differently. | |||||
| * validity -- the decided block satisfies the predefined predicate *valid()*. | |||||
| * termination -- all correct full nodes eventually decide, | |||||
| if the | |||||
| faulty validators have at most 1/3 of voting power in the current validator set. In the case where this assumption | |||||
| does not hold, each of the specification may be violated. | |||||
| The agreement property says that for a given height, any two correct validators that decide on a block for that height decide on the same block. That the block was indeed generated by the blockchain, can be verified starting from a trusted (genesis) block, and checking that all subsequent blocks are properly signed. | |||||
| However, faulty nodes may forge blocks and try to convince users (lite clients) that the blocks had been correctly generated. In addition, Tendermint agreement might be violated in the case where more than 1/3 of the voting power belongs to faulty validators: Two correct validators decide on different blocks. The latter case motivates the term "fork": as Tendermint consensus also agrees on the next validator set, correct validators may have decided on disjoint next validator sets, and the chain branches into two or more partitions (possibly having faulty validators in common) and each branch continues to generate blocks independently of the other. | |||||
| We say that a fork is a case in which there are two commits for different blocks at the same height of the blockchain. The proplem is to ensure that in those cases we are able to detect faulty validators (and not mistakenly accuse correct validators), and incentivize therefore validators to behave according to the protocol specification. | |||||
| **Conceptual Limit.** In order to prove misbehavior of a node, we have to show that the behavior deviates from correct behavior with respect to a given algorithm. Thus, an algorithm that detects misbehavior of nodes executing some algorithm *A* must be defined with respect to algorithm *A*. In our case, *A* is Tendermint consensus (+ other protocols in the infrastructure; e.g.,full nodes and the Lite Client). If the consensus algorithm is changed/updated/optimized in the future, we have to check whether changes to the accountability algorithm are also required. All the discussions in this document are thus inherently specific to Tendermint consensus and the Lite Client specification. | |||||
| **Q:** Should we distinguish agreement for validators and full nodes for agreement? The case where all correct validators agree on a block, but a correct full node decides on a different block seems to be slightly less severe that the case where two correct validators decide on different blocks. Still, if a contaminated full node becomes validator that may be problematic later on. Also it is not clear how gossiping is impaired if a contaminated full node is on a different branch. | |||||
| *Remark.* In the case more than 1/3 of the voting power belongs to faulty validators, also validity and termination can be broken. Termination can be broken if faulty processes just do not send the messages that are needed to make progress. Due to asynchrony, this is not punishable, because faulty validators can always claim they never received the messages that would have forced them to send messages. | |||||
| ## The Misbehavior of Faulty Validators | |||||
| Forks are the result of faulty validators deviating from the protocol. In principle several such deviations can be detected without a fork actually occurring: | |||||
| 1. double proposal: A faulty proposer proposes two different values (blocks) for the same height and the same round in Tendermint consensus. | |||||
| 2. double signing: Tendermint consensus forces correct validators to prevote and precommit for at most one value per round. In case a faulty validator sends multiple prevote and/or precommit messages for different values for the same height/round, this is a misbehavior. | |||||
| 3. lunatic validator: Tendermint consensus forces correct validators to prevote and precommit only for values *v* that satisfy *valid(v)*. If faulty validators prevote and precommit for *v* although *valid(v)=false* this is misbehavior. | |||||
| *Remark.* In isolation, Point 3 is an attack on validity (rather than agreement). However, the prevotes and precommits can then also be used to forge blocks. | |||||
| 1. amnesia: Tendermint consensus has a locking mechanism. If a validator has some value v locked, then it can only prevote/precommit for v or nil. Sending prevote/precomit message for a different value v' (that is not nil) while holding lock on value v is misbehavior. | |||||
| 2. spurious messages: In Tendermint consensus most of the message send instructions are guarded by threshold guards, e.g., one needs to receive *2f + 1* prevote messages to send precommit. Faulty validators may send precommit without having received the prevote messages. | |||||
| Independently of a fork happening, punishing this behavior might be important to prevent forks altogether. This should keep attackers from misbehaving: if at most 1/3 of the voting power is faulty, this misbehavior is detectable but will not lead to a safety violation. Thus, unless they have more than 1/3 (or in some cases more than 2/3) of the voting power attackers have the incentive to not misbehave. If attackers control too much voting power, we have to deal with forks, as discussed in this document. | |||||
| ## Two types of forks | |||||
| * Fork-Full. Two correct validators decide on different blocks for the same height. Since also the next validator sets are decided upon, the correct validators may be partitioned to participate in two distinct branches of the forked chain. | |||||
| As in this case we have two different blocks (both having the same right/no right to exist), a central system invariant (one block per height decided by correct validators) is violated. As full nodes are contaminated in this case, the contamination can spread also to lite clients. However, even without breaking this system invariant, lite clients can be subject to a fork: | |||||
| * Fork-Lite. All correct validators decide on the same block for height *h*, but faulty processes (validators or not), forge a different block for that height, in order to fool users (who use the lite client). | |||||
| # Attack scenarios | |||||
| ## On-chain attacks | |||||
| ### Equivocation (one round) | |||||
| There are several scenarios in which forks might happen. The first is double signing within a round. | |||||
| * F1. Equivocation: faulty validators sign multiple vote messages (prevote and/or precommit) for different values *during the same round r* at a given height h. | |||||
| ### Flip-flopping | |||||
| Tendermint consensus implements a locking mechanism: If a correct validator *p* receives proposal for value v and *2f + 1* prevotes for a value *id(v)* in round *r*, it locks *v* and remembers *r*. In this case, *p* also sends a precommit message for *id(v)*, which later may serve as proof that *p* locked *v*. | |||||
| In subsequent rounds, *p* only sends prevote messages for a value it had previously locked. However, it is possible to change the locked value if in a future round *r' > r*, if the process receives proposal and *2f + 1* prevotes for a different value *v'*. In this case, *p* could send a prevote/precommit for *id(v')*. This algorithmic feature can be exploited in two ways: | |||||
| * F2. Faulty Flip-flopping (Amnesia): faulty validators precommit some value *id(v)* in round *r* (value *v* is locked in round *r*) and then prevote for different value *id(v')* in higher round *r' > r* without previously correctly unlocking value *v*. In this case faulty processes "forget" that they have locked value *v* and prevote some other value in the following rounds. | |||||
| Some correct validators might have decided on *v* in *r*, and other correct validators decide on *v'* in *r'*. Here we can have branching on the main chain (Fork-Full). | |||||
| * F3. Correct Flip-flopping (Back to the past): There are some precommit messages signed by (correct) validators for value *id(v)* in round *r*. Still, *v* is not decided upon, and all processes move on to the next round. Then correct validators (correctly) lock and decide a different value *v'* in some round *r' > r*. And the correct validators continue; there is no branching on the main chain. | |||||
| However, faulty validators may use the correct precommit messages from round *r* together with a posteriori generated faulty precommit messages for round *r* to forge a block for a value that was not decided on the main chain (Fork-Lite). | |||||
| ## Off-chain attacks | |||||
| F1-F3 may contaminate the state of full nodes (and even validators). Contaminated (but otherwise correct) full nodes may thus communicate faulty blocks to lite clients. | |||||
| Similarly, without actually interfering with the main chain, we can have the following: | |||||
| * F4. Phantom validators: faulty validators vote (sign prevote and precommit messages) in heights in which they are not part of the validator sets (at the main chain). | |||||
| * F5. Lunatic validator: faulty validator that sign vote messages to support (arbitrary) application state that is different from the application state that resulted from valid state transitions. | |||||
| ## Types of victims | |||||
| We consider three types of potential attack victims: | |||||
| - FN: full node | |||||
| - LCS: lite client with sequential header verification | |||||
| - LCB: lite client with bisection based header verification | |||||
| F1 and F2 can be used by faulty validators to actually create multiple branches on the blockchain. That means that correctly operating full nodes decide on different blocks for the same height. Until a fork is detected locally by a full node (by receiving evidence from others or by some other local check that fails), the full node can spread corrupted blocks to lite clients. | |||||
| *Remark.* If full nodes take a branch different from the one taken by the validators, it may be that the liveness of the gossip protocol may be affected. We should eventually look at this more closely. However, as it does not influence safety it is not a primary concern. | |||||
| F3 is similar to F1, except that no two correct validators decide on different blocks. It may still be the case that full nodes become affected. | |||||
| In addition, without creating a fork on the main chain, lite clients can be contaminated by more than a third of validators that are faulty and sign a forged header | |||||
| F4 cannot fool correct full nodes as they know the current validator set. Similarly, LCS know who the validators are. Hence, F4 is an attack against LCB that do not necessarily know the complete prefix of headers (Fork-Lite), as they trust a header that is signed by at least one correct validator (trusting period method). | |||||
| The following table gives an overview of how the different attacks may affect different nodes. F1-F3 are *on-chain* attacks so they can corrupt the state of full nodes. Then if a lite client (LCS or LCB) contacts a full node to obtain headers (or blocks), the corrupted state may propagate to the lite client. | |||||
| F4 and F5 are *off-chain*, that is, these attacks cannot be used to corrupt the state of full nodes (which have sufficient knowledge on the state of the chain to not be fooled). | |||||
| | Attack | FN | LCS | LCB | | |||||
| |:------:|:------:|:------:|:------:| | |||||
| | F1 | direct | FN | FN | | |||||
| | F2 | direct | FN | FN | | |||||
| | F3 | direct | FN | FN | | |||||
| | F4 | | | direct | | |||||
| | F5 | | | direct | | |||||
| **Q:** Lite clients are more vulnerable than full nodes, because the former do only verify headers but do not execute transactions. What kind of certainty is gained by a full node that executes a transaction? | |||||
| As a full node verifies all transactions, it can only be | |||||
| contaminated by an attack if the blockchain itself violates its invariant (one block per height), that is, in case of a fork that leads to branching. | |||||
| ## Detailed Attack Scenarios | |||||
| ### Equivocation based attacks | |||||
| In case of equivocation based attacks, faulty validators sign multiple votes (prevote and/or precommit) in the same | |||||
| round of some height. This attack can be executed on both full nodes and lite clients. It requires more than 1/3 of voting power to be executed. | |||||
| #### Scenario 1: Equivocation on the main chain | |||||
| Validators: | |||||
| * CA - a set of correct validators with less than 1/3 of the voting power | |||||
| * CB - a set of correct validators with less than 1/3 of the voting power | |||||
| * CA and CB are disjoint | |||||
| * F - a set of faulty validators with more than 1/3 voting power | |||||
| Observe that this setting violates the Tendermint failure model. | |||||
| Execution: | |||||
| * A faulty proposer proposes block A to CA | |||||
| * A faulty proposer proposes block B to CB | |||||
| * Validators from the set CA and CB prevote for A and B, respectively. | |||||
| * Faulty validators from the set F prevote both for A and B. | |||||
| * The faulty prevote messages | |||||
| - for A arrive at CA long before the B messages | |||||
| - for B arrive at CB long before the A messages | |||||
| * Therefore correct validators from set CA and CB will observe | |||||
| more than 2/3 of prevotes for A and B and precommit for A and B, respectively. | |||||
| * Faulty validators from the set F precommit both values A and B. | |||||
| * Thus, we have more than 2/3 commits for both A and B. | |||||
| Consequences: | |||||
| * Creating evidence of misbehavior is simple in this case as we have multiple messages signed by the same faulty processes for different values in the same round. | |||||
| * We have to ensure that these different messages reach a correct process (full node, monitor?), which can submit evidence. | |||||
| * This is an attack on the full node level (Fork-Full). | |||||
| * It extends also to the lite clients, | |||||
| * For both we need a detection and recovery mechanism. | |||||
| #### Scenario 2: Equivocation to a lite client (LCS) | |||||
| Validators: | |||||
| * a set F of faulty validators with more than 2/3 of the voting power. | |||||
| Execution: | |||||
| * for the main chain F behaves nicely | |||||
| * F coordinates to sign a block B that is different from the one on the main chain. | |||||
| * the lite clients obtains B and trusts at as it is signed by more than 2/3 of the voting power. | |||||
| Consequences: | |||||
| Once equivocation is used to attack lite client it opens space | |||||
| for different kind of attacks as application state can be diverged in any direction. For example, it can modify validator set such that it contains only validators that do not have any stake bonded. Note that after a lite client is fooled by a fork, that means that an attacker can change application state and validator set arbitrarily. | |||||
| In order to detect such (equivocation-based attack), the lite client would need to cross check its state with some correct validator (or to obtain a hash of the state from the main chain using out of band channels). | |||||
| *Remark.* The lite client would be able to create evidence of misbehavior, but this would require to pull potentially a lot of data from correct full nodes. Maybe we need to figure out different architecture where a lite client that is attacked will push all its data for the current unbonding period to a correct node that will inspect this data and submit corresponding evidence. There are also architectures that assumes a special role (sometimes called fisherman) whose goal is to collect as much as possible useful data from the network, to do analysis and create evidence transactions. That functionality is outside the scope of this document. | |||||
| *Remark.* The difference between LCS and LCB might only be in the amount of voting power needed to convince lite client about arbitrary state. In case of LCB where security threshold is at minimum, an attacker can arbitrarily modify application state with more than 1/3 of voting power, while in case of LCS it requires more than 2/3 of the voting power. | |||||
| ### Flip-flopping: Amnesia based attacks | |||||
| In case of amnesia, faulty validators lock some value *v* in some round *r*, and then vote for different value *v'* in higher rounds without correctly unlocking value *v*. This attack can be used both on full nodes and lite clients. | |||||
| #### Scenario 3: At most 2/3 of faults | |||||
| Validators: | |||||
| * a set F of faulty validators with more than 1/3 but at most 2/3 of the voting power | |||||
| * a set C of correct validators | |||||
| Execution: | |||||
| * Faulty validators commit (without exposing it on the main chain) a block A in round *r* by collecting more than 2/3 of the | |||||
| voting power (containing correct and faulty validators). | |||||
| * All validators (correct and faulty) reach a round *r' > r*. | |||||
| * Some correct validators in C do not lock any value before round *r'*. | |||||
| * The faulty validators in F deviate from Tendermint consensus by ignoring that they locked A in *r*, and propose a different block B in *r'*. | |||||
| * As the validators in C that have not locked any value find B acceptable, they accept the proposal for B and commit a block B. | |||||
| *Remark.* In this case, the more than 1/3 of faulty validators do not need to commit an equivocation (F1) as they only vote once per round in the execution. | |||||
| Detecting faulty validators in the case of such an attack can be done by the fork accountability mechanism described in: https://docs.google.com/document/d/11ZhMsCj3y7zIZz4udO9l25xqb0kl7gmWqNpGVRzOeyY/edit?usp=sharing. | |||||
| If a lite client is attacked using this attack with more than 1/3 of voting power (and less than 2/3), the attacker cannot change the application state arbitrarily. Rather, the attacker is limited to a state a correct validator finds acceptable: In the execution above, correct validators still find the value acceptable, however, the block the lite client trusts deviates from the one on the main chain. | |||||
| #### Scenario 4: More than 2/3 of faults | |||||
| In case there is an attack with more than 2/3 of the voting power, an attacker can arbitrarily change application state. | |||||
| Validators: | |||||
| * a set F1 of faulty validators with more than 1/3 of the voting power | |||||
| * a set F2 of faulty validators with at most 1/3 of the voting power | |||||
| Execution | |||||
| * Similar to Scenario 3 (however, messages by correct validators are not needed) | |||||
| * The faulty validators in F1 lock value A in round *r* | |||||
| * They sign a different value in follow-up rounds | |||||
| * F2 does not lock A in round *r* | |||||
| Consequences: | |||||
| * The validators in F1 will be detectable by the the fork accountability mechanisms. | |||||
| * The validators in F2 cannot be detected using this mechanism. | |||||
| Only in case they signed something which conflicts with the application this can be used against them. Otherwise they do not do anything incorrect. | |||||
| * This case is not covered by the report https://docs.google.com/document/d/11ZhMsCj3y7zIZz4udO9l25xqb0kl7gmWqNpGVRzOeyY/edit?usp=sharing as it only assumes at most 2/3 of faulty validators. | |||||
| **Q:** do we need to define a special kind of attack for the case where a validator sign arbitrarily state? It seems that detecting such attack requires a different mechanism that would require as an evidence a sequence of blocks that led to that state. This might be very tricky to implement. | |||||
| ### Back to the past | |||||
| In this kind of attack, faulty validators take advantage of the fact that they did not sign messages in some of the past rounds. Due to the asynchronous network in which Tendermint operates, we cannot easily differentiate between such an attack and delayed message. This kind of attack can be used at both full nodes and lite clients. | |||||
| #### Scenario 5: | |||||
| Validators: | |||||
| * C1 - a set of correct validators with 1/3 of the voting power | |||||
| * C2 - a set of correct validators with 1/3 of the voting power | |||||
| * C1 and C2 are disjoint | |||||
| * F - a set of faulty validators with 1/3 voting power | |||||
| * one additional faulty process *q* | |||||
| * F and *q* violate the Tendermint failure model. | |||||
| Execution: | |||||
| * in a round *r* of height *h* we have C1 precommitting a value A, | |||||
| * C2 precommits nil, | |||||
| * F does not send any message | |||||
| * *q* precommits nil. | |||||
| * In some round *r' > r*, F and *q* and C2 commit some other value B different from A. | |||||
| * F and *fp* "go back to the past" and sign precommit message for value A in round *r*. | |||||
| * Together with precomit messages of C1 this is sufficient for a commit for value A. | |||||
| Consequences: | |||||
| * Only a single faulty validator that previously precommited nil did equivocation, while the other 1/3 of faulty validators actually executed an attack that has exactly the same sequence of messages as part of amnesia attack. Detecting this kind of attack boil down to mechanisms for equivocation and amnesia. | |||||
| **Q:** should we keep this as a separate kind of attack? It seems that equivocation, amnesia and phantom validators are the only kind of attack we need to support and this gives us security also in other cases. This would not be surprising as equivocation and amnesia are attacks that followed from the protocol and phantom attack is not really an attack to Tendermint but more to the Proof of Stake module. | |||||
| ### Phantom validators | |||||
| In case of phantom validators, processes that are not part of the current validator set but are still bonded (as attack happen during their unbonding period) can be part of the attack by signing vote messages. This attack can be executed against both full nodes and lite clients. | |||||
| #### Scenario 6: | |||||
| Validators: | |||||
| * F -- a set of faulty validators that are not part of the validator set on the main chain at height *h + k* | |||||
| Execution: | |||||
| * There is a fork, and there exist two different headers for height *h + k*, with different validator sets: | |||||
| - VS2 on the main chain | |||||
| - forged header VS2', signed by F (and others) | |||||
| * a lite client has a trust in a header for height *h* (and the corresponding validator set VS1). | |||||
| * As part of bisection header verification, it verifies the header at height *h + k* with new validator set VS2'. | |||||
| Consequences: | |||||
| * To detect this, a node needs to see both, the forged header and the canonical header from the chain. | |||||
| * If this is the case, detecting these kind of attacks is easy as it just requires verifying if processes are signing messages in heights in which they are not part of the validator set. | |||||
| **Remark.** We can have phantom-validator-based attacks as a follow up of equivocation or amnesia based attack where forked state contains validators that are not part of the validator set at the main chain. In this case, they keep signing messages contributed to a forked chain (the wrong branch) although they are not part of the validator set on the main chain. This attack can also be used to attack full node during a period of time it is eclipsed. | |||||
| ### Lunatic validator | |||||
| Lunatic validator agrees to sign commit messages for arbitrary application state. It is used to attack lite clients. | |||||
| Note that detecting this behavior require application knowledge. Detecting this behavior can probably be done by | |||||
| referring to the block before the one in which height happen. | |||||
| **Q:** can we say that in this case a validator declines to check if a proposed value is valid before voting for it? | |||||
+ 0
- 329
docs/spec/consensus/light-client.md
View File
| @ -1,329 +0,0 @@ | |||||
| # Lite client | |||||
| A lite client is a process that connects to Tendermint full nodes and then tries to verify application data using the Merkle proofs. | |||||
| ## Context of this document | |||||
| In order to make sure that full nodes have the incentive to follow the protocol, we have to address the following three Issues | |||||
| 1) The lite client needs a method to verify headers it obtains from full nodes according to trust assumptions -- this document. | |||||
| 2) The lite client must be able to connect to one correct full node to detect and report on failures in the trust assumptions (i.e., conflicting headers) -- a future document. | |||||
| 3) In the event the trust assumption fails (i.e., a lite client is fooled by a conflicting header), the Tendermint fork accountability protocol must account for the evidence -- see #3840 | |||||
| ## Problem statement | |||||
| We assume that the lite client knows a (base) header *inithead* it trusts (by social consensus or because the lite client has decided to trust the header before). The goal is to check whether another header *newhead* can be trusted based on the data in *inithead*. | |||||
| The correctness of the protocol is based on the assumption that *inithead* was generated by an instance of Tendermint consensus. The term "trusting" above indicates that the correctness on the protocol depends on this assumption. It is in the responsibility of the user that runs the lite client to make sure that the risk of trusting a corrupted/forged *inithead* is negligible. | |||||
| ## Definitions | |||||
| ### Data structures | |||||
| In the following, only the details of the data structures needed for this specification are given. | |||||
| * header fields | |||||
| - *height* | |||||
| - *bfttime*: the chain time when the header (block) was generated | |||||
| - *V*: validator set containing validators for this block. | |||||
| - *NextV*: validator set for next block. | |||||
| - *commit*: evidence that block with height *height* - 1 was committed by a set of validators (canonical commit). We will use ```signers(commit)``` to refer to the set of validators that committed the block. | |||||
| * signed header fields: contains a header and a *commit* for the current header; a "seen commit". In the Tendermint consensus the "canonical commit" is stored in header *height* + 1. | |||||
| * For each header *h* it has locally stored, the lite client stores whether | |||||
| it trusts *h*. We write *trust(h) = true*, if this is the case. | |||||
| * Validator fields. We will write a validator as a tuple *(v,p)* such that | |||||
| + *v* is the identifier (we assume identifiers are unique in each validator set) | |||||
| + *p* is its voting power | |||||
| ### Functions | |||||
| For the purpose of this lite client specification, we assume that the Tendermint Full Node exposes the following function over Tendermint RPC: | |||||
| ```go | |||||
| func Commit(height int64) (SignedHeader, error) | |||||
| // returns signed header: header (with the fields from | |||||
| // above) with Commit that include signatures of | |||||
| // validators that signed the header | |||||
| type SignedHeader struct { | |||||
| Header Header | |||||
| Commit Commit | |||||
| } | |||||
| ``` | |||||
| ### Definitions | |||||
| * *tp*: trusting period | |||||
| * for realtime *t*, the predicate *correct(v,t)* is true if the validator *v* | |||||
| follows the protocol until time *t* (we will see about recovery later). | |||||
| ### Tendermint Failure Model | |||||
| If a block *h* is generated at time *bfttime* (and this time is stored in the block), then a set of validators that hold more than 2/3 of the voting power in h.Header.NextV is correct until time h.Header.bfttime + tp. | |||||
| Formally, | |||||
| \[ | |||||
| \sum_{(v,p) \in h.Header.NextV \wedge correct(v,h.Header.bfttime + tp)} p > | |||||
| 2/3 \sum_{(v,p) \in h.Header.NextV} p | |||||
| \] | |||||
| *Assumption*: "correct" is defined w.r.t. realtime (some Newtonian global notion of time, i.e., wall time), while *bfttime* corresponds to the reading of the local clock of a validator (how this time is computed may change when the Tendermint consensus is modified). In this note, we assume that all clocks are synchronized to realtime. We can make this more precise eventually (incorporating clock drift, accuracy, precision, etc.). Right now, we consider this assumption sufficient, as clock synchronization (under NTP) is in the order of milliseconds and *tp* is in the order of weeks. | |||||
| *Remark*: This failure model might change to a hybrid version that takes heights into account in the future. | |||||
| The specification in this document considers an implementation of the lite client under this assumption. Issues like *counter-factual signing* and *fork accountability* and *evidence submission* are mechanisms that justify this assumption by incentivizing validators to follow the protocol. | |||||
| If they don't, and we have more that 1/3 faults, safety may be violated. Our approach then is to *detect* these cases (after the fact), and take suitable repair actions (automatic and social). This is discussed in an upcoming document on "Fork accountability". (These safety violations include the lite client wrongly trusting a header, a fork in the blockchain, etc.) | |||||
| ## Lite Client Trusting Spec | |||||
| The lite client communicates with a full node and learns new headers. The goal is to locally decide whether to trust a header. Our implementation needs to ensure the following two properties: | |||||
| - Lite Client Completeness: If header *h* was correctly generated by an instance of Tendermint consensus (and its age is less than the trusting period), then the lite client should eventually set *trust(h)* to true. | |||||
| - Lite Client Accuracy: If header *h* was *not generated* by an instance of Tendermint consensus, then the lite client should never set *trust(h)* to true. | |||||
| *Remark*: If in the course of the computation, the lite client obtains certainty that some headers were forged by adversaries (that is were not generated by an instance of Tendermint consensus), it may submit (a subset of) the headers it has seen as evidence of misbehavior. | |||||
| *Remark*: In Completeness we use "eventually", while in practice *trust(h)* should be set to true before *h.Header.bfttime + tp*. If not, the block cannot be trusted because it is too old. | |||||
| *Remark*: If a header *h* is marked with *trust(h)*, but it is too old (its bfttime is more than *tp* ago), then the lite client should set *trust(h)* to false again. | |||||
| *Assumption*: Initially, the lite client has a header *inithead* that it trusts correctly, that is, *inithead* was correctly generated by the Tendermint consensus. | |||||
| To reason about the correctness, we may prove the following invariant. | |||||
| *Verification Condition: Lite Client Invariant.* | |||||
| For each lite client *l* and each header *h*: | |||||
| if *l* has set *trust(h) = true*, | |||||
| then validators that are correct until time *h.Header.bfttime + tp* have more than two thirds of the voting power in *h.Header.NextV*. | |||||
| Formally, | |||||
| \[ | |||||
| \sum_{(v,p) \in h.Header.NextV \wedge correct(v,h.Header.bfttime + tp)} p > | |||||
| 2/3 \sum_{(v,p) \in h.Header.NextV} p | |||||
| \] | |||||
| *Remark.* To prove the invariant, we will have to prove that the lite client only trusts headers that were correctly generated by Tendermint consensus, then the formula above follows from the Tendermint failure model. | |||||
| ## High Level Solution | |||||
| Upon initialization, the lite client is given a header *inithead* it trusts (by | |||||
| social consensus). It is assumed that *inithead* satisfies the lite client invariant. (If *inithead* has been correctly generated by Tendermint consensus, the invariant follows from the Tendermint Failure Model.) | |||||
| When a lite clients sees a signed new header *snh*, it has to decide whether to trust the new | |||||
| header. Trust can be obtained by (possibly) the combination of three methods. | |||||
| 1. **Uninterrupted sequence of proof.** If a block is appended to the chain, where the last block | |||||
| is trusted (and properly committed by the old validator set in the next block), | |||||
| and the new block contains a new validator set, the new block is trusted if the lite client knows all headers in the prefix. | |||||
| Intuitively, a trusted validator set is assumed to only chose a new validator set that will obey the Tendermint Failure Model. | |||||
| 2. **Trusting period.** Based on a trusted block *h*, and the lite client | |||||
| invariant, which ensures the fault assumption during the trusting period, we can check whether at least one validator, that has been continuously correct from *h.Header.bfttime* until now, has signed *snh*. | |||||
| If this is the case, similarly to above, the chosen validator set in *snh* does not violate the Tendermint Failure Model. | |||||
| 3. **Bisection.** If a check according to the trusting period fails, the lite client can try to obtain a header *hp* whose height lies between *h* and *snh* in order to check whether *h* can be used to get trust for *hp*, and *hp* can be used to get trust for *snh*. If this is the case we can trust *snh*; if not, we may continue recursively. | |||||
| ## How to use it | |||||
| We consider the following use case: | |||||
| the lite client wants to verify a header for some given height *k*. Thus: | |||||
| - it requests the signed header for height *k* from a full node | |||||
| - it tries to verify this header with the methods described here. | |||||
| This can be used in several settings: | |||||
| - someone tells the lite client that application data that is relevant for it can be read in the block of height *k*. | |||||
| - the lite clients wants the latest state. It asks a full node for the current height, and uses the response for *k*. | |||||
| ## Details | |||||
| *Assumptions* | |||||
| 1. *tp < unbonding period*. | |||||
| 2. *snh.Header.bfttime < now* | |||||
| 3. *snh.Header.bfttime < h.Header.bfttime+tp* | |||||
| 4. *trust(h)=true* | |||||
| **Observation 1.** If *h.Header.bfttime + tp > now*, we trust the old | |||||
| validator set *h.Header.NextV*. | |||||
| When we say we trust *h.Header.NextV* we do *not* trust that each individual validator in *h.Header.NextV* is correct, but we only trust the fact that at most 1/3 of them are faulty (more precisely, the faulty ones have at most 1/3 of the total voting power). | |||||
| ### Functions | |||||
| The function *Bisection* checks whether to trust header *h2* based on the trusted header *h1*. It does so by calling | |||||
| the function *CheckSupport* in the process of | |||||
| bisection/recursion. *CheckSupport* implements the trusted period method and, for two adjacent headers (in term of heights), it checks uninterrupted sequence of proof. | |||||
| *Assumption*: In the following, we assume that *h2.Header.height > h1.Header.height*. We will quickly discuss the other case in the next section. | |||||
| We consider the following set-up: | |||||
| - the lite client communicates with one full node | |||||
| - the lite client locally stores all the signed headers it obtained (trusted or not). In the pseudo code below we write *Store(header)* for this. | |||||
| - If *Bisection* returns *false*, then the lite client has seen a forged header. | |||||
| * However, it does not know which header(s) is/are the problematic one(s). | |||||
| * In this case, the lite client can submit (some of) the headers it has seen as evidence. As the lite client communicates with one full node only when executing Bisection, there are two cases | |||||
| - the full node is faulty | |||||
| - the full node is correct and there was a fork in Tendermint consensus. Header *h1* is from a different branch than the one taken by the full node. This case is not focus of this document, but will be treated in the document on fork accountability. | |||||
| - the lite client must retry to retrieve correct headers from another full node | |||||
| * it picks a new full node | |||||
| * it restarts *Bisection* | |||||
| * there might be optimizations; a lite client may not need to call *Commit(k)*, for a height *k* for which it already has a signed header it trusts. | |||||
| * how to make sure that a lite client can communicate with a correct full node will be the focus of a separate document (recall Issue 3 from "Context of this document"). | |||||
| **Auxiliary Functions.** We will use the function ```votingpower_in(V1,V2)``` to compute the voting power the validators in set V1 have according to their voting power in set V2; | |||||
| we will write ```totalVotingPower(V)``` for ```votingpower_in(V,V)```, which returns the total voting power in V. | |||||
| We further use the function ```signers(Commit)``` that returns the set of validators that signed the Commit. | |||||
| **CheckSupport.** The following function checks whether we can trust the header h2 based on header h1 following the trusting period method. | |||||
| ```go | |||||
| func CheckSupport(h1,h2,trustlevel) bool { | |||||
| if h1.Header.bfttime + tp < now { // Observation 1 | |||||
| return false // old header was once trusted but it is expired | |||||
| } | |||||
| vp_all := totalVotingPower(h1.Header.NextV) | |||||
| // total sum of voting power of validators in h2 | |||||
| if h2.Header.height == h1.Header.height + 1 { | |||||
| // specific check for adjacent headers; everything must be | |||||
| // properly signed. | |||||
| // also check that h2.Header.V == h1.Header.NextV | |||||
| // Plus the following check that 2/3 of the voting power | |||||
| // in h1 signed h2 | |||||
| return (votingpower_in(signers(h2.Commit),h1.Header.NextV) > | |||||
| 2/3 * vp_all) | |||||
| // signing validators are more than two third in h1. | |||||
| } | |||||
| return (votingpower_in(signers(h2.Commit),h1.Header.NextV) > | |||||
| max(1/3,trustlevel) * vp_all) | |||||
| // get validators in h1 that signed h2 | |||||
| // sum of voting powers in h1 of | |||||
| // validators that signed h2 | |||||
| // is more than a third in h1 | |||||
| } | |||||
| ``` | |||||
| *Remark*: Basic header verification must be done for *h2*. Similar checks are done in: | |||||
| https://github.com/tendermint/tendermint/blob/master/types/validator_set.go#L591-L633 | |||||
| *Remark*: There are some sanity checks which are not in the code: | |||||
| *h2.Header.height > h1.Header.height* and *h2.Header.bfttime > h1.Header.bfttime* and *h2.Header.bfttime < now*. | |||||
| *Remark*: ```return (votingpower_in(signers(h2.Commit),h1.Header.NextV) > max(1/3,trustlevel) * vp_all)``` may return false even if *h2* was properly generated by Tendermint consensus in the case of big changes in the validator sets. However, the check ```return (votingpower_in(signers(h2.Commit),h1.Header.NextV) > | |||||
| 2/3 * vp_all)``` must return true if *h1* and *h2* were generated by Tendermint consensus. | |||||
| *Remark*: The 1/3 check differs from a previously proposed method that was based on intersecting validator sets and checking that the new validator set contains "enough" correct validators. We found that the old check is not suited for realistic changes in the validator sets. The new method is not only based on cardinalities, but also exploits that we can trust what is signed by a correct validator (i.e., signed by more than 1/3 of the voting power). | |||||
| *Correctness arguments* | |||||
| Towards Lite Client Accuracy: | |||||
| - Assume by contradiction that *h2* was not generated correctly and the lite client sets trust to true because *CheckSupport* returns true. | |||||
| - h1 is trusted and sufficiently new | |||||
| - by Tendermint Fault Model, less than 1/3 of voting power held by faulty validators => at least one correct validator *v* has signed *h2*. | |||||
| - as *v* is correct up to now, it followed the Tendermint consensus protocol at least up to signing *h2* => *h2* was correctly generated, we arrive at the required contradiction. | |||||
| Towards Lite Client Completeness: | |||||
| - The check is successful if sufficiently many validators of *h1* are still validators in *h2* and signed *h2*. | |||||
| - If *h2.Header.height = h1.Header.height + 1*, and both headers were generated correctly, the test passes | |||||
| *Verification Condition:* We may need a Tendermint invariant stating that if *h2.Header.height = h1.Header.height + 1* then *signers(h2.Commit) \subseteq h1.Header.NextV*. | |||||
| *Remark*: The variable *trustlevel* can be used if the user believes that relying on one correct validator is not sufficient. However, in case of (frequent) changes in the validator set, the higher the *trustlevel* is chosen, the more unlikely it becomes that CheckSupport returns true for non-adjacent headers. | |||||
| **Bisection.** The following function uses CheckSupport in a recursion to find intermediate headers that allow to establish a sequence of trust. | |||||
| ```go | |||||
| func Bisection(h1,h2,trustlevel) bool{ | |||||
| if CheckSupport(h1,h2,trustlevel) { | |||||
| return true | |||||
| } | |||||
| if h2.Header.height == h1.Header.height + 1 { | |||||
| // we have adjacent headers that are not matching (failed | |||||
| // the CheckSupport) | |||||
| // we could submit evidence here | |||||
| return false | |||||
| } | |||||
| pivot := (h1.Header.height + h2.Header.height) / 2 | |||||
| hp := Commit(pivot) | |||||
| // ask a full node for header of height pivot | |||||
| Store(hp) | |||||
| // store header hp locally | |||||
| if Bisection(h1,hp,trustlevel) { | |||||
| // only check right branch if hp is trusted | |||||
| // (otherwise a lot of unnecessary computation may be done) | |||||
| return Bisection(hp,h2,trustlevel) | |||||
| } | |||||
| else { | |||||
| return false | |||||
| } | |||||
| } | |||||
| ``` | |||||
| *Correctness arguments (sketch)* | |||||
| Lite Client Accuracy: | |||||
| - Assume by contradiction that *h2* was not generated correctly and the lite client sets trust to true because Bisection returns true. | |||||
| - Bisection returns true only if all calls to CheckSupport in the recursion return true. | |||||
| - Thus we have a sequence of headers that all satisfied the CheckSupport | |||||
| - again a contradiction | |||||
| Lite Client Completeness: | |||||
| This is only ensured if upon *Commit(pivot)* the lite client is always provided with a correctly generated header. | |||||
| *Stalling* | |||||
| With Bisection, a faulty full node could stall a lite client by creating a long sequence of headers that are queried one-by-one by the lite client and look OK, before the lite client eventually detects a problem. There are several ways to address this: | |||||
| * Each call to ```Commit``` could be issued to a different full node | |||||
| * Instead of querying header by header, the lite client tells a full node which header it trusts, and the height of the header it needs. The full node responds with the header along with a proof consisting of intermediate headers that the light client can use to verify. Roughly, Bisection would then be executed at the full node. | |||||
| * We may set a timeout how long bisection may take. | |||||
| ### The case *h2.Header.height < h1.Header.height* | |||||
| In the use case where someone tells the lite client that application data that is relevant for it can be read in the block of height *k* and the lite client trusts a more recent header, we can use the hashes to verify headers "down the chain." That is, we iterate down the heights and check the hashes in each step. | |||||
| *Remark.* For the case were the lite client trusts two headers *i* and *j* with *i < k < j*, we should discuss/experiment whether the forward or the backward method is more effective. | |||||
| ```go | |||||
| func Backwards(h1,h2) bool { | |||||
| assert (h2.Header.height < h1.Header.height) | |||||
| old := h1 | |||||
| for i := h1.Header.height - 1; i > h2.Header.height; i-- { | |||||
| new := Commit(i) | |||||
| Store(new) | |||||
| if (hash(new) != old.Header.hash) { | |||||
| return false | |||||
| } | |||||
| old := new | |||||
| } | |||||
| return (hash(h2) == old.Header.hash) | |||||
| } | |||||
| ``` | |||||
+ 0
- 5
docs/spec/consensus/readme.md
View File
| @ -1,5 +0,0 @@ | |||||
| --- | |||||
| cards: true | |||||
| --- | |||||
| # Consensus | |||||
+ 0
- 205
docs/spec/consensus/signing.md
View File
| @ -1,205 +0,0 @@ | |||||
| # Validator Signing | |||||
| Here we specify the rules for validating a proposal and vote before signing. | |||||
| First we include some general notes on validating data structures common to both types. | |||||
| We then provide specific validation rules for each. Finally, we include validation rules to prevent double-sigining. | |||||
| ## SignedMsgType | |||||
| The `SignedMsgType` is a single byte that refers to the type of the message | |||||
| being signed. It is defined in Go as follows: | |||||
| ``` | |||||
| // SignedMsgType is a type of signed message in the consensus. | |||||
| type SignedMsgType byte | |||||
| const ( | |||||
| // Votes | |||||
| PrevoteType SignedMsgType = 0x01 | |||||
| PrecommitType SignedMsgType = 0x02 | |||||
| // Proposals | |||||
| ProposalType SignedMsgType = 0x20 | |||||
| ) | |||||
| ``` | |||||
| All signed messages must correspond to one of these types. | |||||
| ## Timestamp | |||||
| Timestamp validation is subtle and there are currently no bounds placed on the | |||||
| timestamp included in a proposal or vote. It is expected that validators will honestly | |||||
| report their local clock time. The median of all timestamps | |||||
| included in a commit is used as the timestamp for the next block height. | |||||
| Timestamps are expected to be strictly monotonic for a given validator, though | |||||
| this is not currently enforced. | |||||
| ## ChainID | |||||
| ChainID is an unstructured string with a max length of 50-bytes. | |||||
| In the future, the ChainID may become structured, and may take on longer lengths. | |||||
| For now, it is recommended that signers be configured for a particular ChainID, | |||||
| and to only sign votes and proposals corresponding to that ChainID. | |||||
| ## BlockID | |||||
| BlockID is the structure used to represent the block: | |||||
| ``` | |||||
| type BlockID struct { | |||||
| Hash []byte | |||||
| PartsHeader PartSetHeader | |||||
| } | |||||
| type PartSetHeader struct { | |||||
| Hash []byte | |||||
| Total int | |||||
| } | |||||
| ``` | |||||
| To be included in a valid vote or proposal, BlockID must either represent a `nil` block, or a complete one. | |||||
| We introduce two methods, `BlockID.IsZero()` and `BlockID.IsComplete()` for these cases, respectively. | |||||
| `BlockID.IsZero()` returns true for BlockID `b` if each of the following | |||||
| are true: | |||||
| ``` | |||||
| b.Hash == nil | |||||
| b.PartsHeader.Total == 0 | |||||
| b.PartsHeader.Hash == nil | |||||
| ``` | |||||
| `BlockID.IsComplete()` returns true for BlockID `b` if each of the following | |||||
| are true: | |||||
| ``` | |||||
| len(b.Hash) == 32 | |||||
| b.PartsHeader.Total > 0 | |||||
| len(b.PartsHeader.Hash) == 32 | |||||
| ``` | |||||
| ## Proposals | |||||
| The structure of a proposal for signing looks like: | |||||
| ``` | |||||
| type CanonicalProposal struct { | |||||
| Type SignedMsgType // type alias for byte | |||||
| Height int64 `binary:"fixed64"` | |||||
| Round int64 `binary:"fixed64"` | |||||
| POLRound int64 `binary:"fixed64"` | |||||
| BlockID BlockID | |||||
| Timestamp time.Time | |||||
| ChainID string | |||||
| } | |||||
| ``` | |||||
| A proposal is valid if each of the following lines evaluates to true for proposal `p`: | |||||
| ``` | |||||
| p.Type == 0x20 | |||||
| p.Height > 0 | |||||
| p.Round >= 0 | |||||
| p.POLRound >= -1 | |||||
| p.BlockID.IsComplete() | |||||
| ``` | |||||
| In other words, a proposal is valid for signing if it contains the type of a Proposal | |||||
| (0x20), has a positive, non-zero height, a | |||||
| non-negative round, a POLRound not less than -1, and a complete BlockID. | |||||
| ## Votes | |||||
| The structure of a vote for signing looks like: | |||||
| ``` | |||||
| type CanonicalVote struct { | |||||
| Type SignedMsgType // type alias for byte | |||||
| Height int64 `binary:"fixed64"` | |||||
| Round int64 `binary:"fixed64"` | |||||
| BlockID BlockID | |||||
| Timestamp time.Time | |||||
| ChainID string | |||||
| } | |||||
| ``` | |||||
| A vote is valid if each of the following lines evaluates to true for vote `v`: | |||||
| ``` | |||||
| v.Type == 0x1 || v.Type == 0x2 | |||||
| v.Height > 0 | |||||
| v.Round >= 0 | |||||
| v.BlockID.IsZero() || v.BlockID.IsComplete() | |||||
| ``` | |||||
| In other words, a vote is valid for signing if it contains the type of a Prevote | |||||
| or Precommit (0x1 or 0x2, respectively), has a positive, non-zero height, a | |||||
| non-negative round, and an empty or valid BlockID. | |||||
| ## Invalid Votes and Proposals | |||||
| Votes and proposals which do not satisfy the above rules are considered invalid. | |||||
| Peers gossipping invalid votes and proposals may be disconnected from other peers on the network. | |||||
| Note, however, that there is not currently any explicit mechanism to punish validators signing votes or proposals that fail | |||||
| these basic validation rules. | |||||
| ## Double Signing | |||||
| Signers must be careful not to sign conflicting messages, also known as "double signing" or "equivocating". | |||||
| Tendermint has mechanisms to publish evidence of validators that signed conflicting votes, so they can be punished | |||||
| by the application. Note Tendermint does not currently handle evidence of conflciting proposals, though it may in the future. | |||||
| ### State | |||||
| To prevent such double signing, signers must track the height, round, and type of the last message signed. | |||||
| Assume the signer keeps the following state, `s`: | |||||
| ``` | |||||
| type LastSigned struct { | |||||
| Height int64 | |||||
| Round int64 | |||||
| Type SignedMsgType // byte | |||||
| } | |||||
| ``` | |||||
| After signing a vote or proposal `m`, the signer sets: | |||||
| ``` | |||||
| s.Height = m.Height | |||||
| s.Round = m.Round | |||||
| s.Type = m.Type | |||||
| ``` | |||||
| ### Proposals | |||||
| A signer should only sign a proposal `p` if any of the following lines are true: | |||||
| ``` | |||||
| p.Height > s.Height | |||||
| p.Height == s.Height && p.Round > s.Round | |||||
| ``` | |||||
| In other words, a proposal should only be signed if it's at a higher height, or a higher round for the same height. | |||||
| Once a proposal or vote has been signed for a given height and round, a proposal should never be signed for the same height and round. | |||||
| ### Votes | |||||
| A signer should only sign a vote `v` if any of the following lines are true: | |||||
| ``` | |||||
| v.Height > s.Height | |||||
| v.Height == s.Height && v.Round > s.Round | |||||
| v.Height == s.Height && v.Round == s.Round && v.Step == 0x1 && s.Step == 0x20 | |||||
| v.Height == s.Height && v.Round == s.Round && v.Step == 0x2 && s.Step != 0x2 | |||||
| ``` | |||||
| In other words, a vote should only be signed if it's: | |||||
| - at a higher height | |||||
| - at a higher round for the same height | |||||
| - a prevote for the same height and round where we haven't signed a prevote or precommit (but have signed a proposal) | |||||
| - a precommit for the same height and round where we haven't signed a precommit (but have signed a proposal and/or a prevote) | |||||
| This means that once a validator signs a prevote for a given height and round, the only other message it can sign for that height and round is a precommit. | |||||
| And once a validator signs a precommit for a given height and round, it must not sign any other message for that same height and round. | |||||
+ 0
- 32
docs/spec/consensus/wal.md
View File
| @ -1,32 +0,0 @@ | |||||
| # WAL | |||||
| Consensus module writes every message to the WAL (write-ahead log). | |||||
| It also issues fsync syscall through | |||||
| [File#Sync](https://golang.org/pkg/os/#File.Sync) for messages signed by this | |||||
| node (to prevent double signing). | |||||
| Under the hood, it uses | |||||
| [autofile.Group](https://godoc.org/github.com/tendermint/tmlibs/autofile#Group), | |||||
| which rotates files when those get too big (> 10MB). | |||||
| The total maximum size is 1GB. We only need the latest block and the block before it, | |||||
| but if the former is dragging on across many rounds, we want all those rounds. | |||||
| ## Replay | |||||
| Consensus module will replay all the messages of the last height written to WAL | |||||
| before a crash (if such occurs). | |||||
| The private validator may try to sign messages during replay because it runs | |||||
| somewhat autonomously and does not know about replay process. | |||||
| For example, if we got all the way to precommit in the WAL and then crash, | |||||
| after we replay the proposal message, the private validator will try to sign a | |||||
| prevote. But it will fail. That's ok because we’ll see the prevote later in the | |||||
| WAL. Then it will go to precommit, and that time it will work because the | |||||
| private validator contains the `LastSignBytes` and then we’ll replay the | |||||
| precommit from the WAL. | |||||
| Make sure to read about [WAL corruption](../../tendermint-core/running-in-production.md#wal-corruption) | |||||
| and recovery strategies. | |||||
+ 0
- 38
docs/spec/p2p/config.md
View File
| @ -1,38 +0,0 @@ | |||||
| # P2P Config | |||||
| Here we describe configuration options around the Peer Exchange. | |||||
| These can be set using flags or via the `$TMHOME/config/config.toml` file. | |||||
| ## Seed Mode | |||||
| `--p2p.seed_mode` | |||||
| The node operates in seed mode. In seed mode, a node continuously crawls the network for peers, | |||||
| and upon incoming connection shares some peers and disconnects. | |||||
| ## Seeds | |||||
| `--p2p.seeds “id100000000000000000000000000000000@1.2.3.4:26656,id200000000000000000000000000000000@2.3.4.5:4444”` | |||||
| Dials these seeds when we need more peers. They should return a list of peers and then disconnect. | |||||
| If we already have enough peers in the address book, we may never need to dial them. | |||||
| ## Persistent Peers | |||||
| `--p2p.persistent_peers “id100000000000000000000000000000000@1.2.3.4:26656,id200000000000000000000000000000000@2.3.4.5:26656”` | |||||
| Dial these peers and auto-redial them if the connection fails. | |||||
| These are intended to be trusted persistent peers that can help | |||||
| anchor us in the p2p network. The auto-redial uses exponential | |||||
| backoff and will give up after a day of trying to connect. | |||||
| **Note:** If `seeds` and `persistent_peers` intersect, | |||||
| the user will be warned that seeds may auto-close connections | |||||
| and that the node may not be able to keep the connection persistent. | |||||
| ## Private Peers | |||||
| `--p2p.private_peer_ids “id100000000000000000000000000000000,id200000000000000000000000000000000”` | |||||
| These are IDs of the peers that we do not add to the address book or gossip to | |||||
| other peers. They stay private to us. | |||||
+ 0
- 111
docs/spec/p2p/connection.md
View File
| @ -1,111 +0,0 @@ | |||||
| # P2P Multiplex Connection | |||||
| ## MConnection | |||||
| `MConnection` is a multiplex connection that supports multiple independent streams | |||||
| with distinct quality of service guarantees atop a single TCP connection. | |||||
| Each stream is known as a `Channel` and each `Channel` has a globally unique _byte id_. | |||||
| Each `Channel` also has a relative priority that determines the quality of service | |||||
| of the `Channel` compared to other `Channel`s. | |||||
| The _byte id_ and the relative priorities of each `Channel` are configured upon | |||||
| initialization of the connection. | |||||
| The `MConnection` supports three packet types: | |||||
| - Ping | |||||
| - Pong | |||||
| - Msg | |||||
| ### Ping and Pong | |||||
| The ping and pong messages consist of writing a single byte to the connection; 0x1 and 0x2, respectively. | |||||
| When we haven't received any messages on an `MConnection` in time `pingTimeout`, we send a ping message. | |||||
| When a ping is received on the `MConnection`, a pong is sent in response only if there are no other messages | |||||
| to send and the peer has not sent us too many pings (TODO). | |||||
| If a pong or message is not received in sufficient time after a ping, the peer is disconnected from. | |||||
| ### Msg | |||||
| Messages in channels are chopped into smaller `msgPacket`s for multiplexing. | |||||
| ``` | |||||
| type msgPacket struct { | |||||
| ChannelID byte | |||||
| EOF byte // 1 means message ends here. | |||||
| Bytes []byte | |||||
| } | |||||
| ``` | |||||
| The `msgPacket` is serialized using [go-amino](https://github.com/tendermint/go-amino) and prefixed with 0x3. | |||||
| The received `Bytes` of a sequential set of packets are appended together | |||||
| until a packet with `EOF=1` is received, then the complete serialized message | |||||
| is returned for processing by the `onReceive` function of the corresponding channel. | |||||
| ### Multiplexing | |||||
| Messages are sent from a single `sendRoutine`, which loops over a select statement and results in the sending | |||||
| of a ping, a pong, or a batch of data messages. The batch of data messages may include messages from multiple channels. | |||||
| Message bytes are queued for sending in their respective channel, with each channel holding one unsent message at a time. | |||||
| Messages are chosen for a batch one at a time from the channel with the lowest ratio of recently sent bytes to channel priority. | |||||
| ## Sending Messages | |||||
| There are two methods for sending messages: | |||||
| ```go | |||||
| func (m MConnection) Send(chID byte, msg interface{}) bool {} | |||||
| func (m MConnection) TrySend(chID byte, msg interface{}) bool {} | |||||
| ``` | |||||
| `Send(chID, msg)` is a blocking call that waits until `msg` is successfully queued | |||||
| for the channel with the given id byte `chID`. The message `msg` is serialized | |||||
| using the `tendermint/go-amino` submodule's `WriteBinary()` reflection routine. | |||||
| `TrySend(chID, msg)` is a nonblocking call that queues the message msg in the channel | |||||
| with the given id byte chID if the queue is not full; otherwise it returns false immediately. | |||||
| `Send()` and `TrySend()` are also exposed for each `Peer`. | |||||
| ## Peer | |||||
| Each peer has one `MConnection` instance, and includes other information such as whether the connection | |||||
| was outbound, whether the connection should be recreated if it closes, various identity information about the node, | |||||
| and other higher level thread-safe data used by the reactors. | |||||
| ## Switch/Reactor | |||||
| The `Switch` handles peer connections and exposes an API to receive incoming messages | |||||
| on `Reactors`. Each `Reactor` is responsible for handling incoming messages of one | |||||
| or more `Channels`. So while sending outgoing messages is typically performed on the peer, | |||||
| incoming messages are received on the reactor. | |||||
| ```go | |||||
| // Declare a MyReactor reactor that handles messages on MyChannelID. | |||||
| type MyReactor struct{} | |||||
| func (reactor MyReactor) GetChannels() []*ChannelDescriptor { | |||||
| return []*ChannelDescriptor{ChannelDescriptor{ID:MyChannelID, Priority: 1}} | |||||
| } | |||||
| func (reactor MyReactor) Receive(chID byte, peer *Peer, msgBytes []byte) { | |||||
| r, n, err := bytes.NewBuffer(msgBytes), new(int64), new(error) | |||||
| msgString := ReadString(r, n, err) | |||||
| fmt.Println(msgString) | |||||
| } | |||||
| // Other Reactor methods omitted for brevity | |||||
| ... | |||||
| switch := NewSwitch([]Reactor{MyReactor{}}) | |||||
| ... | |||||
| // Send a random message to all outbound connections | |||||
| for _, peer := range switch.Peers().List() { | |||||
| if peer.IsOutbound() { | |||||
| peer.Send(MyChannelID, "Here's a random message") | |||||
| } | |||||
| } | |||||
| ``` | |||||
+ 0
- 66
docs/spec/p2p/node.md
View File
| @ -1,66 +0,0 @@ | |||||
| # Peer Discovery | |||||
| A Tendermint P2P network has different kinds of nodes with different requirements for connectivity to one another. | |||||
| This document describes what kind of nodes Tendermint should enable and how they should work. | |||||
| ## Seeds | |||||
| Seeds are the first point of contact for a new node. | |||||
| They return a list of known active peers and then disconnect. | |||||
| Seeds should operate full nodes with the PEX reactor in a "crawler" mode | |||||
| that continuously explores to validate the availability of peers. | |||||
| Seeds should only respond with some top percentile of the best peers it knows about. | |||||
| See [the peer-exchange docs](https://github.com/tendermint/tendermint/blob/master/docs/spec/reactors/pex/pex.md)for details on peer quality. | |||||
| ## New Full Node | |||||
| A new node needs a few things to connect to the network: | |||||
| - a list of seeds, which can be provided to Tendermint via config file or flags, | |||||
| or hardcoded into the software by in-process apps | |||||
| - a `ChainID`, also called `Network` at the p2p layer | |||||
| - a recent block height, H, and hash, HASH for the blockchain. | |||||
| The values `H` and `HASH` must be received and corroborated by means external to Tendermint, and specific to the user - ie. via the user's trusted social consensus. | |||||
| This requirement to validate `H` and `HASH` out-of-band and via social consensus | |||||
| is the essential difference in security models between Proof-of-Work and Proof-of-Stake blockchains. | |||||
| With the above, the node then queries some seeds for peers for its chain, | |||||
| dials those peers, and runs the Tendermint protocols with those it successfully connects to. | |||||
| When the peer catches up to height H, it ensures the block hash matches HASH. | |||||
| If not, Tendermint will exit, and the user must try again - either they are connected | |||||
| to bad peers or their social consensus is invalid. | |||||
| ## Restarted Full Node | |||||
| A node checks its address book on startup and attempts to connect to peers from there. | |||||
| If it can't connect to any peers after some time, it falls back to the seeds to find more. | |||||
| Restarted full nodes can run the `blockchain` or `consensus` reactor protocols to sync up | |||||
| to the latest state of the blockchain from wherever they were last. | |||||
| In a Proof-of-Stake context, if they are sufficiently far behind (greater than the length | |||||
| of the unbonding period), they will need to validate a recent `H` and `HASH` out-of-band again | |||||
| so they know they have synced the correct chain. | |||||
| ## Validator Node | |||||
| A validator node is a node that interfaces with a validator signing key. | |||||
| These nodes require the highest security, and should not accept incoming connections. | |||||
| They should maintain outgoing connections to a controlled set of "Sentry Nodes" that serve | |||||
| as their proxy shield to the rest of the network. | |||||
| Validators that know and trust each other can accept incoming connections from one another and maintain direct private connectivity via VPN. | |||||
| ## Sentry Node | |||||
| Sentry nodes are guardians of a validator node and provide it access to the rest of the network. | |||||
| They should be well connected to other full nodes on the network. | |||||
| Sentry nodes may be dynamic, but should maintain persistent connections to some evolving random subset of each other. | |||||
| They should always expect to have direct incoming connections from the validator node and its backup(s). | |||||
| They do not report the validator node's address in the PEX and | |||||
| they may be more strict about the quality of peers they keep. | |||||
| Sentry nodes belonging to validators that trust each other may wish to maintain persistent connections via VPN with one another, but only report each other sparingly in the PEX. | |||||
+ 0
- 119
docs/spec/p2p/peer.md
View File
| @ -1,119 +0,0 @@ | |||||
| # Peers | |||||
| This document explains how Tendermint Peers are identified and how they connect to one another. | |||||
| For details on peer discovery, see the [peer exchange (PEX) reactor doc](https://github.com/tendermint/tendermint/blob/master/docs/spec/reactors/pex/pex.md). | |||||
| ## Peer Identity | |||||
| Tendermint peers are expected to maintain long-term persistent identities in the form of a public key. | |||||
| Each peer has an ID defined as `peer.ID == peer.PubKey.Address()`, where `Address` uses the scheme defined in `crypto` package. | |||||
| A single peer ID can have multiple IP addresses associated with it, but a node | |||||
| will only ever connect to one at a time. | |||||
| When attempting to connect to a peer, we use the PeerURL: `<ID>@<IP>:<PORT>`. | |||||
| We will attempt to connect to the peer at IP:PORT, and verify, | |||||
| via authenticated encryption, that it is in possession of the private key | |||||
| corresponding to `<ID>`. This prevents man-in-the-middle attacks on the peer layer. | |||||
| ## Connections | |||||
| All p2p connections use TCP. | |||||
| Upon establishing a successful TCP connection with a peer, | |||||
| two handhsakes are performed: one for authenticated encryption, and one for Tendermint versioning. | |||||
| Both handshakes have configurable timeouts (they should complete quickly). | |||||
| ### Authenticated Encryption Handshake | |||||
| Tendermint implements the Station-to-Station protocol | |||||
| using X25519 keys for Diffie-Helman key-exchange and chacha20poly1305 for encryption. | |||||
| It goes as follows: | |||||
| - generate an ephemeral X25519 keypair | |||||
| - send the ephemeral public key to the peer | |||||
| - wait to receive the peer's ephemeral public key | |||||
| - compute the Diffie-Hellman shared secret using the peers ephemeral public key and our ephemeral private key | |||||
| - generate two keys to use for encryption (sending and receiving) and a challenge for authentication as follows: | |||||
| - create a hkdf-sha256 instance with the key being the diffie hellman shared secret, and info parameter as | |||||
| `TENDERMINT_SECRET_CONNECTION_KEY_AND_CHALLENGE_GEN` | |||||
| - get 96 bytes of output from hkdf-sha256 | |||||
| - if we had the smaller ephemeral pubkey, use the first 32 bytes for the key for receiving, the second 32 bytes for sending; else the opposite | |||||
| - use the last 32 bytes of output for the challenge | |||||
| - use a separate nonce for receiving and sending. Both nonces start at 0, and should support the full 96 bit nonce range | |||||
| - all communications from now on are encrypted in 1024 byte frames, | |||||
| using the respective secret and nonce. Each nonce is incremented by one after each use. | |||||
| - we now have an encrypted channel, but still need to authenticate | |||||
| - sign the common challenge obtained from the hkdf with our persistent private key | |||||
| - send the amino encoded persistent pubkey and signature to the peer | |||||
| - wait to receive the persistent public key and signature from the peer | |||||
| - verify the signature on the challenge using the peer's persistent public key | |||||
| If this is an outgoing connection (we dialed the peer) and we used a peer ID, | |||||
| then finally verify that the peer's persistent public key corresponds to the peer ID we dialed, | |||||
| ie. `peer.PubKey.Address() == <ID>`. | |||||
| The connection has now been authenticated. All traffic is encrypted. | |||||
| Note: only the dialer can authenticate the identity of the peer, | |||||
| but this is what we care about since when we join the network we wish to | |||||
| ensure we have reached the intended peer (and are not being MITMd). | |||||
| ### Peer Filter | |||||
| Before continuing, we check if the new peer has the same ID as ourselves or | |||||
| an existing peer. If so, we disconnect. | |||||
| We also check the peer's address and public key against | |||||
| an optional whitelist which can be managed through the ABCI app - | |||||
| if the whitelist is enabled and the peer does not qualify, the connection is | |||||
| terminated. | |||||
| ### Tendermint Version Handshake | |||||
| The Tendermint Version Handshake allows the peers to exchange their NodeInfo: | |||||
| ```golang | |||||
| type NodeInfo struct { | |||||
| Version p2p.Version | |||||
| ID p2p.ID | |||||
| ListenAddr string | |||||
| Network string | |||||
| SoftwareVersion string | |||||
| Channels []int8 | |||||
| Moniker string | |||||
| Other NodeInfoOther | |||||
| } | |||||
| type Version struct { | |||||
| P2P uint64 | |||||
| Block uint64 | |||||
| App uint64 | |||||
| } | |||||
| type NodeInfoOther struct { | |||||
| TxIndex string | |||||
| RPCAddress string | |||||
| } | |||||
| ``` | |||||
| The connection is disconnected if: | |||||
| - `peer.NodeInfo.ID` is not equal `peerConn.ID` | |||||
| - `peer.NodeInfo.Version.Block` does not match ours | |||||
| - `peer.NodeInfo.Network` is not the same as ours | |||||
| - `peer.Channels` does not intersect with our known Channels. | |||||
| - `peer.NodeInfo.ListenAddr` is malformed or is a DNS host that cannot be | |||||
| resolved | |||||
| At this point, if we have not disconnected, the peer is valid. | |||||
| It is added to the switch and hence all reactors via the `AddPeer` method. | |||||
| Note that each reactor may handle multiple channels. | |||||
| ## Connection Activity | |||||
| Once a peer is added, incoming messages for a given reactor are handled through | |||||
| that reactor's `Receive` method, and output messages are sent directly by the Reactors | |||||
| on each peer. A typical reactor maintains per-peer go-routine(s) that handle this. | |||||
+ 0
- 5
docs/spec/p2p/readme.md
View File
| @ -1,5 +0,0 @@ | |||||
| --- | |||||
| cards: true | |||||
| --- | |||||
| # P2P | |||||
BIN
docs/spec/reactors/block_sync/bcv1/img/bc-reactor-new-datastructs.png
View File
{kind=link}
| Before | After |
|---|---|
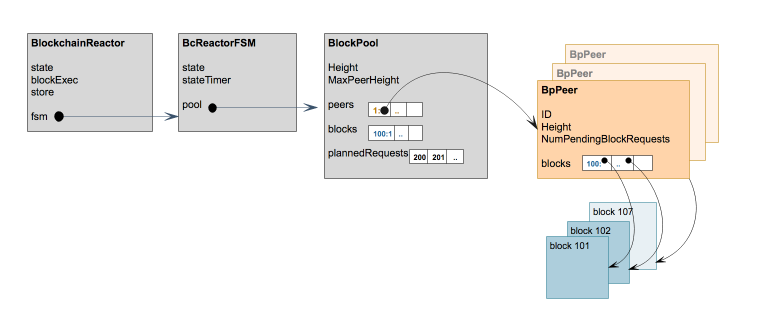
|
|
| Width: 768 | Height: 335 | Size: 43 KiB |
BIN
docs/spec/reactors/block_sync/bcv1/img/bc-reactor-new-fsm.png
View File
{kind=link}
| Before | After |
|---|---|
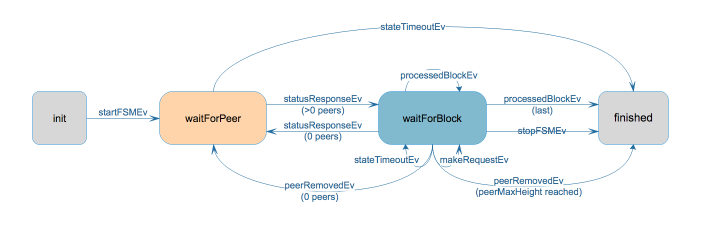
|
|
| Width: 705 | Height: 228 | Size: 41 KiB |
BIN
docs/spec/reactors/block_sync/bcv1/img/bc-reactor-new-goroutines.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 1027 | Height: 675 | Size: 138 KiB |
+ 0
- 237
docs/spec/reactors/block_sync/bcv1/impl-v1.md
View File
| @ -1,237 +0,0 @@ | |||||
| # Blockchain Reactor v1 | |||||
| ### Data Structures | |||||
| The data structures used are illustrated below. | |||||
|  | |||||
| #### BlockchainReactor | |||||
| - is a `p2p.BaseReactor`. | |||||
| - has a `store.BlockStore` for persistence. | |||||
| - executes blocks using an `sm.BlockExecutor`. | |||||
| - starts the FSM and the `poolRoutine()`. | |||||
| - relays the fast-sync responses and switch messages to the FSM. | |||||
| - handles errors from the FSM and when necessarily reports them to the switch. | |||||
| - implements the blockchain reactor interface used by the FSM to send requests, errors to the switch and state timer resets. | |||||
| - registers all the concrete types and interfaces for serialisation. | |||||
| ```go | |||||
| type BlockchainReactor struct { | |||||
| p2p.BaseReactor | |||||
| initialState sm.State // immutable | |||||
| state sm.State | |||||
| blockExec *sm.BlockExecutor | |||||
| store *store.BlockStore | |||||
| fastSync bool | |||||
| fsm *BcReactorFSM | |||||
| blocksSynced int | |||||
| // Receive goroutine forwards messages to this channel to be processed in the context of the poolRoutine. | |||||
| messagesForFSMCh chan bcReactorMessage | |||||
| // Switch goroutine may send RemovePeer to the blockchain reactor. This is an error message that is relayed | |||||
| // to this channel to be processed in the context of the poolRoutine. | |||||
| errorsForFSMCh chan bcReactorMessage | |||||
| // This channel is used by the FSM and indirectly the block pool to report errors to the blockchain reactor and | |||||
| // the switch. | |||||
| eventsFromFSMCh chan bcFsmMessage | |||||
| } | |||||
| ``` | |||||
| #### BcReactorFSM | |||||
| - implements a simple finite state machine. | |||||
| - has a state and a state timer. | |||||
| - has a `BlockPool` to keep track of block requests sent to peers and blocks received from peers. | |||||
| - uses an interface to send status requests, block requests and reporting errors. The interface is implemented by the `BlockchainReactor` and tests. | |||||
| ```go | |||||
| type BcReactorFSM struct { | |||||
| logger log.Logger | |||||
| mtx sync.Mutex | |||||
| startTime time.Time | |||||
| state *bcReactorFSMState | |||||
| stateTimer *time.Timer | |||||
| pool *BlockPool | |||||
| // interface used to call the Blockchain reactor to send StatusRequest, BlockRequest, reporting errors, etc. | |||||
| toBcR bcReactor | |||||
| } | |||||
| ``` | |||||
| #### BlockPool | |||||
| - maintains a peer set, implemented as a map of peer ID to `BpPeer`. | |||||
| - maintains a set of requests made to peers, implemented as a map of block request heights to peer IDs. | |||||
| - maintains a list of future block requests needed to advance the fast-sync. This is a list of block heights. | |||||
| - keeps track of the maximum height of the peers in the set. | |||||
| - uses an interface to send requests and report errors to the reactor (via FSM). | |||||
| ```go | |||||
| type BlockPool struct { | |||||
| logger log.Logger | |||||
| // Set of peers that have sent status responses, with height bigger than pool.Height | |||||
| peers map[p2p.ID]*BpPeer | |||||
| // Set of block heights and the corresponding peers from where a block response is expected or has been received. | |||||
| blocks map[int64]p2p.ID | |||||
| plannedRequests map[int64]struct{} // list of blocks to be assigned peers for blockRequest | |||||
| nextRequestHeight int64 // next height to be added to plannedRequests | |||||
| Height int64 // height of next block to execute | |||||
| MaxPeerHeight int64 // maximum height of all peers | |||||
| toBcR bcReactor | |||||
| } | |||||
| ``` | |||||
| Some reasons for the `BlockPool` data structure content: | |||||
| 1. If a peer is removed by the switch fast access is required to the peer and the block requests made to that peer in order to redo them. | |||||
| 2. When block verification fails fast access is required from the block height to the peer and the block requests made to that peer in order to redo them. | |||||
| 3. The `BlockchainReactor` main routine decides when the block pool is running low and asks the `BlockPool` (via FSM) to make more requests. The `BlockPool` creates a list of requests and triggers the sending of the block requests (via the interface). The reason it maintains a list of requests is the redo operations that may occur during error handling. These are redone when the `BlockchainReactor` requires more blocks. | |||||
| #### BpPeer | |||||
| - keeps track of a single peer, with height bigger than the initial height. | |||||
| - maintains the block requests made to the peer and the blocks received from the peer until they are executed. | |||||
| - monitors the peer speed when there are pending requests. | |||||
| - it has an active timer when pending requests are present and reports error on timeout. | |||||
| ```go | |||||
| type BpPeer struct { | |||||
| logger log.Logger | |||||
| ID p2p.ID | |||||
| Height int64 // the peer reported height | |||||
| NumPendingBlockRequests int // number of requests still waiting for block responses | |||||
| blocks map[int64]*types.Block // blocks received or expected to be received from this peer | |||||
| blockResponseTimer *time.Timer | |||||
| recvMonitor *flow.Monitor | |||||
| params *BpPeerParams // parameters for timer and monitor | |||||
| onErr func(err error, peerID p2p.ID) // function to call on error | |||||
| } | |||||
| ``` | |||||
| ### Concurrency Model | |||||
| The diagram below shows the goroutines (depicted by the gray blocks), timers (shown on the left with their values) and channels (colored rectangles). The FSM box shows some of the functionality and it is not a separate goroutine. | |||||
| The interface used by the FSM is shown in light red with the `IF` block. This is used to: | |||||
| - send block requests | |||||
| - report peer errors to the switch - this results in the reactor calling `switch.StopPeerForError()` and, if triggered by the peer timeout routine, a `removePeerEv` is sent to the FSM and action is taken from the context of the `poolRoutine()` | |||||
| - ask the reactor to reset the state timers. The timers are owned by the FSM while the timeout routine is defined by the reactor. This was done in order to avoid running timers in tests and will change in the next revision. | |||||
| There are two main goroutines implemented by the blockchain reactor. All I/O operations are performed from the `poolRoutine()` context while the CPU intensive operations related to the block execution are performed from the context of the `executeBlocksRoutine()`. All goroutines are detailed in the next sections. | |||||
|  | |||||
| #### Receive() | |||||
| Fast-sync messages from peers are received by this goroutine. It performs basic validation and: | |||||
| - in helper mode (i.e. for request message) it replies immediately. This is different than the proposal in adr-040 that specifies having the FSM handling these. | |||||
| - forwards response messages to the `poolRoutine()`. | |||||
| #### poolRoutine() | |||||
| (named kept as in the previous reactor). | |||||
| It starts the `executeBlocksRoutine()` and the FSM. It then waits in a loop for events. These are received from the following channels: | |||||
| - `sendBlockRequestTicker.C` - every 10msec the reactor asks FSM to make more block requests up to a maximum. Note: currently this value is constant but could be changed based on low/ high watermark thresholds for the number of blocks received and waiting to be processed, the number of blockResponse messages waiting in messagesForFSMCh, etc. | |||||
| - `statusUpdateTicker.C` - every 10 seconds the reactor broadcasts status requests to peers. While adr-040 specifies this to run within the FSM, at this point this functionality is kept in the reactor. | |||||
| - `messagesForFSMCh` - the `Receive()` goroutine sends status and block response messages to this channel and the reactor calls FSM to handle them. | |||||
| - `errorsForFSMCh` - this channel receives the following events: | |||||
| - peer remove - when the switch removes a peer | |||||
| - sate timeout event - when FSM state timers trigger | |||||
| The reactor forwards this messages to the FSM. | |||||
| - `eventsFromFSMCh` - there are two type of events sent over this channel: | |||||
| - `syncFinishedEv` - triggered when FSM enters `finished` state and calls the switchToConsensus() interface function. | |||||
| - `peerErrorEv`- peer timer expiry goroutine sends this event over the channel for processing from poolRoutine() context. | |||||
| #### executeBlocksRoutine() | |||||
| Started by the `poolRoutine()`, it retrieves blocks from the pool and executes them: | |||||
| - `processReceivedBlockTicker.C` - a ticker event is received over the channel every 10msec and its handling results in a signal being sent to the doProcessBlockCh channel. | |||||
| - doProcessBlockCh - events are received on this channel as described as above and upon processing blocks are retrieved from the pool and executed. | |||||
| ### FSM | |||||
|  | |||||
| #### States | |||||
| ##### init (aka unknown) | |||||
| The FSM is created in `unknown` state. When started, by the reactor (`startFSMEv`), it broadcasts Status requests and transitions to `waitForPeer` state. | |||||
| ##### waitForPeer | |||||
| In this state, the FSM waits for a Status responses from a "tall" peer. A timer is running in this state to allow the FSM to finish if there are no useful peers. | |||||
| If the timer expires, it moves to `finished` state and calls the reactor to switch to consensus. | |||||
| If a Status response is received from a peer within the timeout, the FSM transitions to `waitForBlock` state. | |||||
| ##### waitForBlock | |||||
| In this state the FSM makes Block requests (triggered by a ticker in reactor) and waits for Block responses. There is a timer running in this state to detect if a peer is not sending the block at current processing height. If the timer expires, the FSM removes the peer where the request was sent and all requests made to that peer are redone. | |||||
| As blocks are received they are stored by the pool. Block execution is independently performed by the reactor and the result reported to the FSM: | |||||
| - if there are no errors, the FSM increases the pool height and resets the state timer. | |||||
| - if there are errors, the peers that delivered the two blocks (at height and height+1) are removed and the requests redone. | |||||
| In this state the FSM may receive peer remove events in any of the following scenarios: | |||||
| - the switch is removing a peer | |||||
| - a peer is penalized because it has not responded to some block requests for a long time | |||||
| - a peer is penalized for being slow | |||||
| When processing of the last block (the one with height equal to the highest peer height minus one) is successful, the FSM transitions to `finished` state. | |||||
| If after a peer update or removal the pool height is same as maxPeerHeight, the FSM transitions to `finished` state. | |||||
| ##### finished | |||||
| When entering this state, the FSM calls the reactor to switch to consensus and performs cleanup. | |||||
| #### Events | |||||
| The following events are handled by the FSM: | |||||
| ```go | |||||
| const ( | |||||
| startFSMEv = iota + 1 | |||||
| statusResponseEv | |||||
| blockResponseEv | |||||
| processedBlockEv | |||||
| makeRequestsEv | |||||
| stopFSMEv | |||||
| peerRemoveEv = iota + 256 | |||||
| stateTimeoutEv | |||||
| ) | |||||
| ``` | |||||
| ### Examples of Scenarios and Termination Handling | |||||
| A few scenarios are covered in this section together with the current/ proposed handling. | |||||
| In general, the scenarios involving faulty peers are made worse by the fact that they may quickly be re-added. | |||||
| #### 1. No Tall Peers | |||||
| S: In this scenario a node is started and while there are status responses received, none of the peers are at a height higher than this node. | |||||
| H: The FSM times out in `waitForPeer` state, moves to `finished` state where it calls the reactor to switch to consensus. | |||||
| #### 2. Typical Fast Sync | |||||
| S: A node fast syncs blocks from honest peers and eventually downloads and executes the penultimate block. | |||||
| H: The FSM in `waitForBlock` state will receive the processedBlockEv from the reactor and detect that the termination height is achieved. | |||||
| #### 3. Peer Claims Big Height but no Blocks | |||||
| S: In this scenario a faulty peer claims a big height (for which there are no blocks). | |||||
| H: The requests for the non-existing block will timeout, the peer removed and the pool's `MaxPeerHeight` updated. FSM checks if the termination height is achieved when peers are removed. | |||||
| #### 4. Highest Peer Removed or Updated to Short | |||||
| S: The fast sync node is caught up with all peers except one tall peer. The tall peer is removed or it sends status response with low height. | |||||
| H: FSM checks termination condition on peer removal and updates. | |||||
| #### 5. Block At Current Height Delayed | |||||
| S: A peer can block the progress of fast sync by delaying indefinitely the block response for the current processing height (h1). | |||||
| H: Currently, given h1 < h2, there is no enforcement at peer level that the response for h1 should be received before h2. So a peer will timeout only after delivering all blocks except h1. However the `waitForBlock` state timer fires if the block for current processing height is not received within a timeout. The peer is removed and the requests to that peer (including the one for current height) redone. | |||||
BIN
docs/spec/reactors/block_sync/img/bc-reactor-routines.png
View File
{kind=link}
| Before | After |
|---|---|
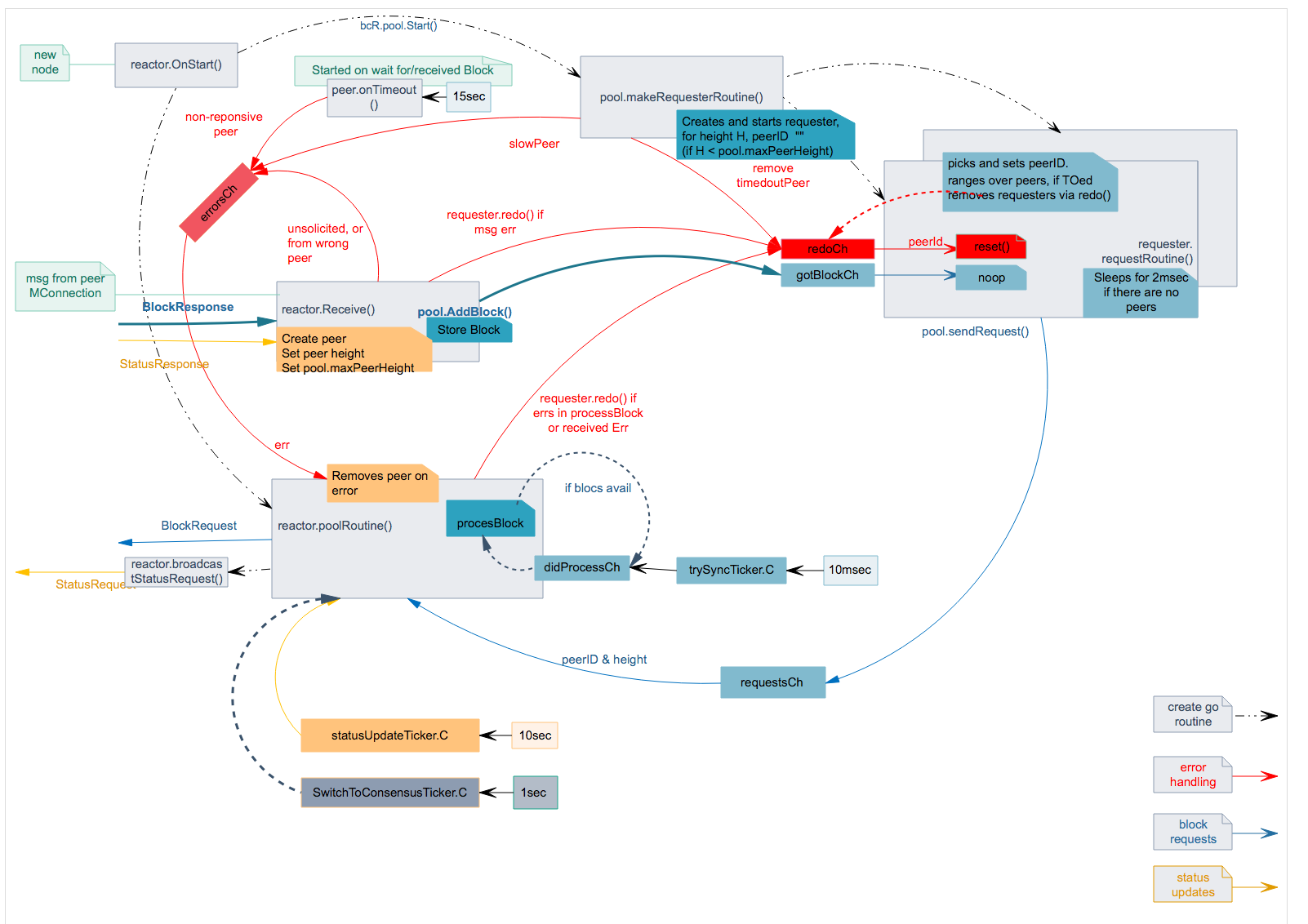
|
|
| Width: 1602 | Height: 1132 | Size: 265 KiB |
BIN
docs/spec/reactors/block_sync/img/bc-reactor.png
View File
{kind=link}
| Before | After |
|---|---|
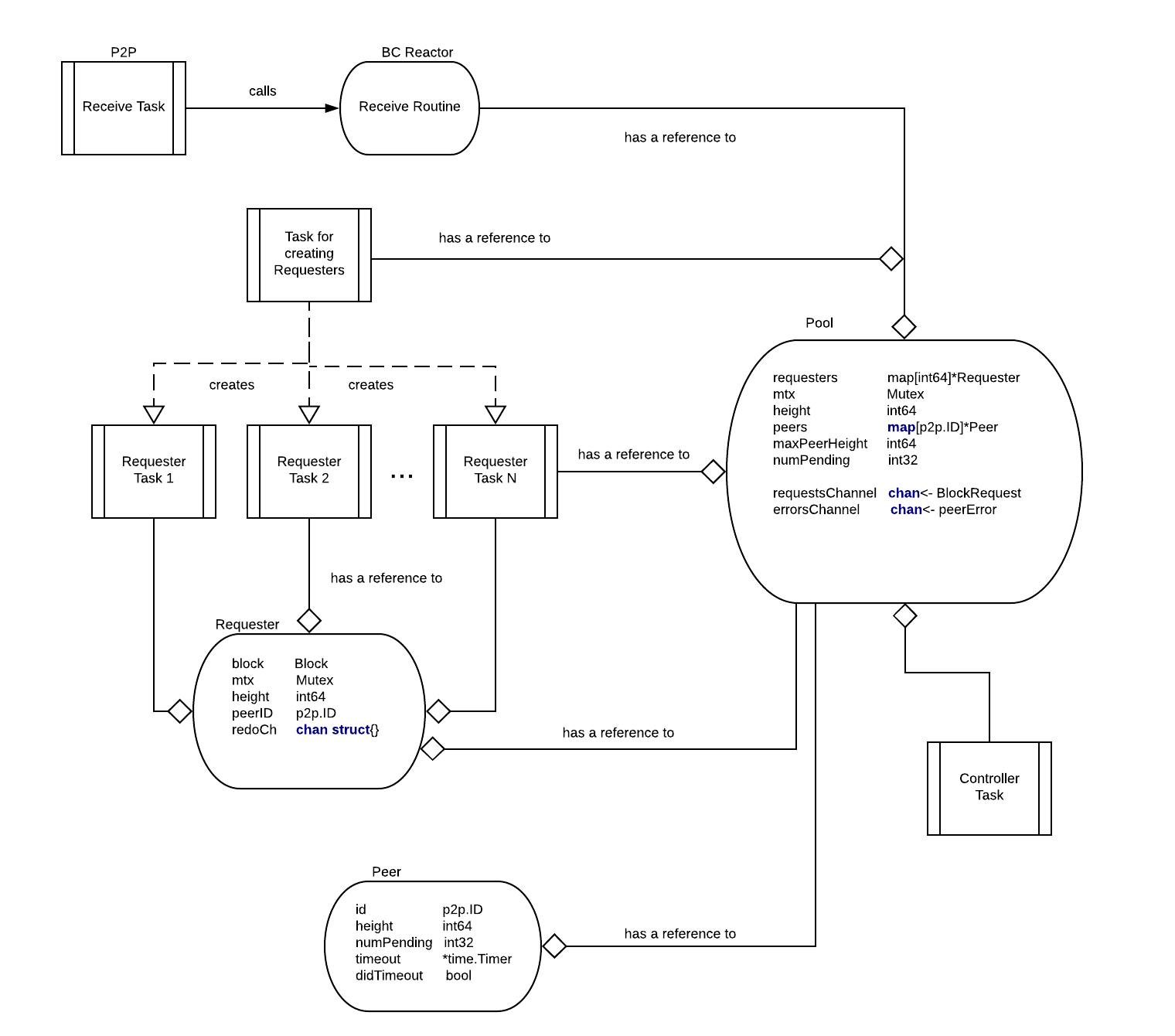
|
|
| Width: 1520 | Height: 1340 | Size: 43 KiB |
+ 0
- 44
docs/spec/reactors/block_sync/impl.md
View File
| @ -1,44 +0,0 @@ | |||||
| ## Blockchain Reactor v0 Modules | |||||
| ### Blockchain Reactor | |||||
| - coordinates the pool for syncing | |||||
| - coordinates the store for persistence | |||||
| - coordinates the playing of blocks towards the app using a sm.BlockExecutor | |||||
| - handles switching between fastsync and consensus | |||||
| - it is a p2p.BaseReactor | |||||
| - starts the pool.Start() and its poolRoutine() | |||||
| - registers all the concrete types and interfaces for serialisation | |||||
| #### poolRoutine | |||||
| - listens to these channels: | |||||
| - pool requests blocks from a specific peer by posting to requestsCh, block reactor then sends | |||||
| a &bcBlockRequestMessage for a specific height | |||||
| - pool signals timeout of a specific peer by posting to timeoutsCh | |||||
| - switchToConsensusTicker to periodically try and switch to consensus | |||||
| - trySyncTicker to periodically check if we have fallen behind and then catch-up sync | |||||
| - if there aren't any new blocks available on the pool it skips syncing | |||||
| - tries to sync the app by taking downloaded blocks from the pool, gives them to the app and stores | |||||
| them on disk | |||||
| - implements Receive which is called by the switch/peer | |||||
| - calls AddBlock on the pool when it receives a new block from a peer | |||||
| ### Block Pool | |||||
| - responsible for downloading blocks from peers | |||||
| - makeRequestersRoutine() | |||||
| - removes timeout peers | |||||
| - starts new requesters by calling makeNextRequester() | |||||
| - requestRoutine(): | |||||
| - picks a peer and sends the request, then blocks until: | |||||
| - pool is stopped by listening to pool.Quit | |||||
| - requester is stopped by listening to Quit | |||||
| - request is redone | |||||
| - we receive a block | |||||
| - gotBlockCh is strange | |||||
| ### Go Routines in Blockchain Reactor | |||||
|  | |||||
+ 0
- 308
docs/spec/reactors/block_sync/reactor.md
View File
| @ -1,308 +0,0 @@ | |||||
| # Blockchain Reactor | |||||
| The Blockchain Reactor's high level responsibility is to enable peers who are | |||||
| far behind the current state of the consensus to quickly catch up by downloading | |||||
| many blocks in parallel, verifying their commits, and executing them against the | |||||
| ABCI application. | |||||
| Tendermint full nodes run the Blockchain Reactor as a service to provide blocks | |||||
| to new nodes. New nodes run the Blockchain Reactor in "fast_sync" mode, | |||||
| where they actively make requests for more blocks until they sync up. | |||||
| Once caught up, "fast_sync" mode is disabled and the node switches to | |||||
| using (and turns on) the Consensus Reactor. | |||||
| ## Message Types | |||||
| ```go | |||||
| const ( | |||||
| msgTypeBlockRequest = byte(0x10) | |||||
| msgTypeBlockResponse = byte(0x11) | |||||
| msgTypeNoBlockResponse = byte(0x12) | |||||
| msgTypeStatusResponse = byte(0x20) | |||||
| msgTypeStatusRequest = byte(0x21) | |||||
| ) | |||||
| ``` | |||||
| ```go | |||||
| type bcBlockRequestMessage struct { | |||||
| Height int64 | |||||
| } | |||||
| type bcNoBlockResponseMessage struct { | |||||
| Height int64 | |||||
| } | |||||
| type bcBlockResponseMessage struct { | |||||
| Block Block | |||||
| } | |||||
| type bcStatusRequestMessage struct { | |||||
| Height int64 | |||||
| type bcStatusResponseMessage struct { | |||||
| Height int64 | |||||
| } | |||||
| ``` | |||||
| ## Architecture and algorithm | |||||
| The Blockchain reactor is organised as a set of concurrent tasks: | |||||
| - Receive routine of Blockchain Reactor | |||||
| - Task for creating Requesters | |||||
| - Set of Requesters tasks and - Controller task. | |||||
|  | |||||
| ### Data structures | |||||
| These are the core data structures necessarily to provide the Blockchain Reactor logic. | |||||
| Requester data structure is used to track assignment of request for `block` at position `height` to a peer with id equals to `peerID`. | |||||
| ```go | |||||
| type Requester { | |||||
| mtx Mutex | |||||
| block Block | |||||
| height int64 | |||||
| peerID p2p.ID | |||||
| redoChannel chan p2p.ID //redo may send multi-time; peerId is used to identify repeat | |||||
| } | |||||
| ``` | |||||
| Pool is a core data structure that stores last executed block (`height`), assignment of requests to peers (`requesters`), current height for each peer and number of pending requests for each peer (`peers`), maximum peer height, etc. | |||||
| ```go | |||||
| type Pool { | |||||
| mtx Mutex | |||||
| requesters map[int64]*Requester | |||||
| height int64 | |||||
| peers map[p2p.ID]*Peer | |||||
| maxPeerHeight int64 | |||||
| numPending int32 | |||||
| store BlockStore | |||||
| requestsChannel chan<- BlockRequest | |||||
| errorsChannel chan<- peerError | |||||
| } | |||||
| ``` | |||||
| Peer data structure stores for each peer current `height` and number of pending requests sent to the peer (`numPending`), etc. | |||||
| ```go | |||||
| type Peer struct { | |||||
| id p2p.ID | |||||
| height int64 | |||||
| numPending int32 | |||||
| timeout *time.Timer | |||||
| didTimeout bool | |||||
| } | |||||
| ``` | |||||
| BlockRequest is internal data structure used to denote current mapping of request for a block at some `height` to a peer (`PeerID`). | |||||
| ```go | |||||
| type BlockRequest { | |||||
| Height int64 | |||||
| PeerID p2p.ID | |||||
| } | |||||
| ``` | |||||
| ### Receive routine of Blockchain Reactor | |||||
| It is executed upon message reception on the BlockchainChannel inside p2p receive routine. There is a separate p2p receive routine (and therefore receive routine of the Blockchain Reactor) executed for each peer. Note that try to send will not block (returns immediately) if outgoing buffer is full. | |||||
| ```go | |||||
| handleMsg(pool, m): | |||||
| upon receiving bcBlockRequestMessage m from peer p: | |||||
| block = load block for height m.Height from pool.store | |||||
| if block != nil then | |||||
| try to send BlockResponseMessage(block) to p | |||||
| else | |||||
| try to send bcNoBlockResponseMessage(m.Height) to p | |||||
| upon receiving bcBlockResponseMessage m from peer p: | |||||
| pool.mtx.Lock() | |||||
| requester = pool.requesters[m.Height] | |||||
| if requester == nil then | |||||
| error("peer sent us a block we didn't expect") | |||||
| continue | |||||
| if requester.block == nil and requester.peerID == p then | |||||
| requester.block = m | |||||
| pool.numPending -= 1 // atomic decrement | |||||
| peer = pool.peers[p] | |||||
| if peer != nil then | |||||
| peer.numPending-- | |||||
| if peer.numPending == 0 then | |||||
| peer.timeout.Stop() | |||||
| // NOTE: we don't send Quit signal to the corresponding requester task! | |||||
| else | |||||
| trigger peer timeout to expire after peerTimeout | |||||
| pool.mtx.Unlock() | |||||
| upon receiving bcStatusRequestMessage m from peer p: | |||||
| try to send bcStatusResponseMessage(pool.store.Height) | |||||
| upon receiving bcStatusResponseMessage m from peer p: | |||||
| pool.mtx.Lock() | |||||
| peer = pool.peers[p] | |||||
| if peer != nil then | |||||
| peer.height = m.height | |||||
| else | |||||
| peer = create new Peer data structure with id = p and height = m.Height | |||||
| pool.peers[p] = peer | |||||
| if m.Height > pool.maxPeerHeight then | |||||
| pool.maxPeerHeight = m.Height | |||||
| pool.mtx.Unlock() | |||||
| onTimeout(p): | |||||
| send error message to pool error channel | |||||
| peer = pool.peers[p] | |||||
| peer.didTimeout = true | |||||
| ``` | |||||
| ### Requester tasks | |||||
| Requester task is responsible for fetching a single block at position `height`. | |||||
| ```go | |||||
| fetchBlock(height, pool): | |||||
| while true do { | |||||
| peerID = nil | |||||
| block = nil | |||||
| peer = pickAvailablePeer(height) | |||||
| peerID = peer.id | |||||
| enqueue BlockRequest(height, peerID) to pool.requestsChannel | |||||
| redo = false | |||||
| while !redo do | |||||
| select { | |||||
| upon receiving Quit message do | |||||
| return | |||||
| upon receiving redo message with id on redoChannel do | |||||
| if peerID == id { | |||||
| mtx.Lock() | |||||
| pool.numPending++ | |||||
| redo = true | |||||
| mtx.UnLock() | |||||
| } | |||||
| } | |||||
| } | |||||
| pickAvailablePeer(height): | |||||
| selectedPeer = nil | |||||
| while selectedPeer = nil do | |||||
| pool.mtx.Lock() | |||||
| for each peer in pool.peers do | |||||
| if !peer.didTimeout and peer.numPending < maxPendingRequestsPerPeer and peer.height >= height then | |||||
| peer.numPending++ | |||||
| selectedPeer = peer | |||||
| break | |||||
| pool.mtx.Unlock() | |||||
| if selectedPeer = nil then | |||||
| sleep requestIntervalMS | |||||
| return selectedPeer | |||||
| ``` | |||||
| sleep for requestIntervalMS | |||||
| ### Task for creating Requesters | |||||
| This task is responsible for continuously creating and starting Requester tasks. | |||||
| ```go | |||||
| createRequesters(pool): | |||||
| while true do | |||||
| if !pool.isRunning then break | |||||
| if pool.numPending < maxPendingRequests or size(pool.requesters) < maxTotalRequesters then | |||||
| pool.mtx.Lock() | |||||
| nextHeight = pool.height + size(pool.requesters) | |||||
| requester = create new requester for height nextHeight | |||||
| pool.requesters[nextHeight] = requester | |||||
| pool.numPending += 1 // atomic increment | |||||
| start requester task | |||||
| pool.mtx.Unlock() | |||||
| else | |||||
| sleep requestIntervalMS | |||||
| pool.mtx.Lock() | |||||
| for each peer in pool.peers do | |||||
| if !peer.didTimeout && peer.numPending > 0 && peer.curRate < minRecvRate then | |||||
| send error on pool error channel | |||||
| peer.didTimeout = true | |||||
| if peer.didTimeout then | |||||
| for each requester in pool.requesters do | |||||
| if requester.getPeerID() == peer then | |||||
| enqueue msg on requestor's redoChannel | |||||
| delete(pool.peers, peerID) | |||||
| pool.mtx.Unlock() | |||||
| ``` | |||||
| ### Main blockchain reactor controller task | |||||
| ```go | |||||
| main(pool): | |||||
| create trySyncTicker with interval trySyncIntervalMS | |||||
| create statusUpdateTicker with interval statusUpdateIntervalSeconds | |||||
| create switchToConsensusTicker with interval switchToConsensusIntervalSeconds | |||||
| while true do | |||||
| select { | |||||
| upon receiving BlockRequest(Height, Peer) on pool.requestsChannel: | |||||
| try to send bcBlockRequestMessage(Height) to Peer | |||||
| upon receiving error(peer) on errorsChannel: | |||||
| stop peer for error | |||||
| upon receiving message on statusUpdateTickerChannel: | |||||
| broadcast bcStatusRequestMessage(bcR.store.Height) // message sent in a separate routine | |||||
| upon receiving message on switchToConsensusTickerChannel: | |||||
| pool.mtx.Lock() | |||||
| receivedBlockOrTimedOut = pool.height > 0 || (time.Now() - pool.startTime) > 5 Seconds | |||||
| ourChainIsLongestAmongPeers = pool.maxPeerHeight == 0 || pool.height >= pool.maxPeerHeight | |||||
| haveSomePeers = size of pool.peers > 0 | |||||
| pool.mtx.Unlock() | |||||
| if haveSomePeers && receivedBlockOrTimedOut && ourChainIsLongestAmongPeers then | |||||
| switch to consensus mode | |||||
| upon receiving message on trySyncTickerChannel: | |||||
| for i = 0; i < 10; i++ do | |||||
| pool.mtx.Lock() | |||||
| firstBlock = pool.requesters[pool.height].block | |||||
| secondBlock = pool.requesters[pool.height].block | |||||
| if firstBlock == nil or secondBlock == nil then continue | |||||
| pool.mtx.Unlock() | |||||
| verify firstBlock using LastCommit from secondBlock | |||||
| if verification failed | |||||
| pool.mtx.Lock() | |||||
| peerID = pool.requesters[pool.height].peerID | |||||
| redoRequestsForPeer(peerId) | |||||
| delete(pool.peers, peerID) | |||||
| stop peer peerID for error | |||||
| pool.mtx.Unlock() | |||||
| else | |||||
| delete(pool.requesters, pool.height) | |||||
| save firstBlock to store | |||||
| pool.height++ | |||||
| execute firstBlock | |||||
| } | |||||
| redoRequestsForPeer(pool, peerId): | |||||
| for each requester in pool.requesters do | |||||
| if requester.getPeerID() == peerID | |||||
| enqueue msg on redoChannel for requester | |||||
| ``` | |||||
| ## Channels | |||||
| Defines `maxMsgSize` for the maximum size of incoming messages, | |||||
| `SendQueueCapacity` and `RecvBufferCapacity` for maximum sending and | |||||
| receiving buffers respectively. These are supposed to prevent amplification | |||||
| attacks by setting up the upper limit on how much data we can receive & send to | |||||
| a peer. | |||||
| Sending incorrectly encoded data will result in stopping the peer. | |||||
+ 0
- 364
docs/spec/reactors/consensus/consensus-reactor.md
View File
| @ -1,364 +0,0 @@ | |||||
| # Consensus Reactor | |||||
| Consensus Reactor defines a reactor for the consensus service. It contains the ConsensusState service that | |||||
| manages the state of the Tendermint consensus internal state machine. | |||||
| When Consensus Reactor is started, it starts Broadcast Routine which starts ConsensusState service. | |||||
| Furthermore, for each peer that is added to the Consensus Reactor, it creates (and manages) the known peer state | |||||
| (that is used extensively in gossip routines) and starts the following three routines for the peer p: | |||||
| Gossip Data Routine, Gossip Votes Routine and QueryMaj23Routine. Finally, Consensus Reactor is responsible | |||||
| for decoding messages received from a peer and for adequate processing of the message depending on its type and content. | |||||
| The processing normally consists of updating the known peer state and for some messages | |||||
| (`ProposalMessage`, `BlockPartMessage` and `VoteMessage`) also forwarding message to ConsensusState module | |||||
| for further processing. In the following text we specify the core functionality of those separate unit of executions | |||||
| that are part of the Consensus Reactor. | |||||
| ## ConsensusState service | |||||
| Consensus State handles execution of the Tendermint BFT consensus algorithm. It processes votes and proposals, | |||||
| and upon reaching agreement, commits blocks to the chain and executes them against the application. | |||||
| The internal state machine receives input from peers, the internal validator and from a timer. | |||||
| Inside Consensus State we have the following units of execution: Timeout Ticker and Receive Routine. | |||||
| Timeout Ticker is a timer that schedules timeouts conditional on the height/round/step that are processed | |||||
| by the Receive Routine. | |||||
| ### Receive Routine of the ConsensusState service | |||||
| Receive Routine of the ConsensusState handles messages which may cause internal consensus state transitions. | |||||
| It is the only routine that updates RoundState that contains internal consensus state. | |||||
| Updates (state transitions) happen on timeouts, complete proposals, and 2/3 majorities. | |||||
| It receives messages from peers, internal validators and from Timeout Ticker | |||||
| and invokes the corresponding handlers, potentially updating the RoundState. | |||||
| The details of the protocol (together with formal proofs of correctness) implemented by the Receive Routine are | |||||
| discussed in separate document. For understanding of this document | |||||
| it is sufficient to understand that the Receive Routine manages and updates RoundState data structure that is | |||||
| then extensively used by the gossip routines to determine what information should be sent to peer processes. | |||||
| ## Round State | |||||
| RoundState defines the internal consensus state. It contains height, round, round step, a current validator set, | |||||
| a proposal and proposal block for the current round, locked round and block (if some block is being locked), set of | |||||
| received votes and last commit and last validators set. | |||||
| ```golang | |||||
| type RoundState struct { | |||||
| Height int64 | |||||
| Round int | |||||
| Step RoundStepType | |||||
| Validators ValidatorSet | |||||
| Proposal Proposal | |||||
| ProposalBlock Block | |||||
| ProposalBlockParts PartSet | |||||
| LockedRound int | |||||
| LockedBlock Block | |||||
| LockedBlockParts PartSet | |||||
| Votes HeightVoteSet | |||||
| LastCommit VoteSet | |||||
| LastValidators ValidatorSet | |||||
| } | |||||
| ``` | |||||
| Internally, consensus will run as a state machine with the following states: | |||||
| - RoundStepNewHeight | |||||
| - RoundStepNewRound | |||||
| - RoundStepPropose | |||||
| - RoundStepProposeWait | |||||
| - RoundStepPrevote | |||||
| - RoundStepPrevoteWait | |||||
| - RoundStepPrecommit | |||||
| - RoundStepPrecommitWait | |||||
| - RoundStepCommit | |||||
| ## Peer Round State | |||||
| Peer round state contains the known state of a peer. It is being updated by the Receive routine of | |||||
| Consensus Reactor and by the gossip routines upon sending a message to the peer. | |||||
| ```golang | |||||
| type PeerRoundState struct { | |||||
| Height int64 // Height peer is at | |||||
| Round int // Round peer is at, -1 if unknown. | |||||
| Step RoundStepType // Step peer is at | |||||
| Proposal bool // True if peer has proposal for this round | |||||
| ProposalBlockPartsHeader PartSetHeader | |||||
| ProposalBlockParts BitArray | |||||
| ProposalPOLRound int // Proposal's POL round. -1 if none. | |||||
| ProposalPOL BitArray // nil until ProposalPOLMessage received. | |||||
| Prevotes BitArray // All votes peer has for this round | |||||
| Precommits BitArray // All precommits peer has for this round | |||||
| LastCommitRound int // Round of commit for last height. -1 if none. | |||||
| LastCommit BitArray // All commit precommits of commit for last height. | |||||
| CatchupCommitRound int // Round that we have commit for. Not necessarily unique. -1 if none. | |||||
| CatchupCommit BitArray // All commit precommits peer has for this height & CatchupCommitRound | |||||
| } | |||||
| ``` | |||||
| ## Receive method of Consensus reactor | |||||
| The entry point of the Consensus reactor is a receive method. When a message is | |||||
| received from a peer p, normally the peer round state is updated | |||||
| correspondingly, and some messages are passed for further processing, for | |||||
| example to ConsensusState service. We now specify the processing of messages in | |||||
| the receive method of Consensus reactor for each message type. In the following | |||||
| message handler, `rs` and `prs` denote `RoundState` and `PeerRoundState`, | |||||
| respectively. | |||||
| ### NewRoundStepMessage handler | |||||
| ``` | |||||
| handleMessage(msg): | |||||
| if msg is from smaller height/round/step then return | |||||
| // Just remember these values. | |||||
| prsHeight = prs.Height | |||||
| prsRound = prs.Round | |||||
| prsCatchupCommitRound = prs.CatchupCommitRound | |||||
| prsCatchupCommit = prs.CatchupCommit | |||||
| Update prs with values from msg | |||||
| if prs.Height or prs.Round has been updated then | |||||
| reset Proposal related fields of the peer state | |||||
| if prs.Round has been updated and msg.Round == prsCatchupCommitRound then | |||||
| prs.Precommits = psCatchupCommit | |||||
| if prs.Height has been updated then | |||||
| if prsHeight+1 == msg.Height && prsRound == msg.LastCommitRound then | |||||
| prs.LastCommitRound = msg.LastCommitRound | |||||
| prs.LastCommit = prs.Precommits | |||||
| } else { | |||||
| prs.LastCommitRound = msg.LastCommitRound | |||||
| prs.LastCommit = nil | |||||
| } | |||||
| Reset prs.CatchupCommitRound and prs.CatchupCommit | |||||
| ``` | |||||
| ### NewValidBlockMessage handler | |||||
| ``` | |||||
| handleMessage(msg): | |||||
| if prs.Height != msg.Height then return | |||||
| if prs.Round != msg.Round && !msg.IsCommit then return | |||||
| prs.ProposalBlockPartsHeader = msg.BlockPartsHeader | |||||
| prs.ProposalBlockParts = msg.BlockParts | |||||
| ``` | |||||
| The number of block parts is limited to 1601 (`types.MaxBlockPartsCount`) to | |||||
| protect the node against DOS attacks. | |||||
| ### HasVoteMessage handler | |||||
| ``` | |||||
| handleMessage(msg): | |||||
| if prs.Height == msg.Height then | |||||
| prs.setHasVote(msg.Height, msg.Round, msg.Type, msg.Index) | |||||
| ``` | |||||
| ### VoteSetMaj23Message handler | |||||
| ``` | |||||
| handleMessage(msg): | |||||
| if prs.Height == msg.Height then | |||||
| Record in rs that a peer claim to have ⅔ majority for msg.BlockID | |||||
| Send VoteSetBitsMessage showing votes node has for that BlockId | |||||
| ``` | |||||
| ### ProposalMessage handler | |||||
| ``` | |||||
| handleMessage(msg): | |||||
| if prs.Height != msg.Height || prs.Round != msg.Round || prs.Proposal then return | |||||
| prs.Proposal = true | |||||
| if prs.ProposalBlockParts == empty set then // otherwise it is set in NewValidBlockMessage handler | |||||
| prs.ProposalBlockPartsHeader = msg.BlockPartsHeader | |||||
| prs.ProposalPOLRound = msg.POLRound | |||||
| prs.ProposalPOL = nil | |||||
| Send msg through internal peerMsgQueue to ConsensusState service | |||||
| ``` | |||||
| ### ProposalPOLMessage handler | |||||
| ``` | |||||
| handleMessage(msg): | |||||
| if prs.Height != msg.Height or prs.ProposalPOLRound != msg.ProposalPOLRound then return | |||||
| prs.ProposalPOL = msg.ProposalPOL | |||||
| ``` | |||||
| The number of votes is limited to 10000 (`types.MaxVotesCount`) to protect the | |||||
| node against DOS attacks. | |||||
| ### BlockPartMessage handler | |||||
| ``` | |||||
| handleMessage(msg): | |||||
| if prs.Height != msg.Height || prs.Round != msg.Round then return | |||||
| Record in prs that peer has block part msg.Part.Index | |||||
| Send msg trough internal peerMsgQueue to ConsensusState service | |||||
| ``` | |||||
| ### VoteMessage handler | |||||
| ``` | |||||
| handleMessage(msg): | |||||
| Record in prs that a peer knows vote with index msg.vote.ValidatorIndex for particular height and round | |||||
| Send msg trough internal peerMsgQueue to ConsensusState service | |||||
| ``` | |||||
| ### VoteSetBitsMessage handler | |||||
| ``` | |||||
| handleMessage(msg): | |||||
| Update prs for the bit-array of votes peer claims to have for the msg.BlockID | |||||
| ``` | |||||
| The number of votes is limited to 10000 (`types.MaxVotesCount`) to protect the | |||||
| node against DOS attacks. | |||||
| ## Gossip Data Routine | |||||
| It is used to send the following messages to the peer: `BlockPartMessage`, `ProposalMessage` and | |||||
| `ProposalPOLMessage` on the DataChannel. The gossip data routine is based on the local RoundState (`rs`) | |||||
| and the known PeerRoundState (`prs`). The routine repeats forever the logic shown below: | |||||
| ``` | |||||
| 1a) if rs.ProposalBlockPartsHeader == prs.ProposalBlockPartsHeader and the peer does not have all the proposal parts then | |||||
| Part = pick a random proposal block part the peer does not have | |||||
| Send BlockPartMessage(rs.Height, rs.Round, Part) to the peer on the DataChannel | |||||
| if send returns true, record that the peer knows the corresponding block Part | |||||
| Continue | |||||
| 1b) if (0 < prs.Height) and (prs.Height < rs.Height) then | |||||
| help peer catch up using gossipDataForCatchup function | |||||
| Continue | |||||
| 1c) if (rs.Height != prs.Height) or (rs.Round != prs.Round) then | |||||
| Sleep PeerGossipSleepDuration | |||||
| Continue | |||||
| // at this point rs.Height == prs.Height and rs.Round == prs.Round | |||||
| 1d) if (rs.Proposal != nil and !prs.Proposal) then | |||||
| Send ProposalMessage(rs.Proposal) to the peer | |||||
| if send returns true, record that the peer knows Proposal | |||||
| if 0 <= rs.Proposal.POLRound then | |||||
| polRound = rs.Proposal.POLRound | |||||
| prevotesBitArray = rs.Votes.Prevotes(polRound).BitArray() | |||||
| Send ProposalPOLMessage(rs.Height, polRound, prevotesBitArray) | |||||
| Continue | |||||
| 2) Sleep PeerGossipSleepDuration | |||||
| ``` | |||||
| ### Gossip Data For Catchup | |||||
| This function is responsible for helping peer catch up if it is at the smaller height (prs.Height < rs.Height). | |||||
| The function executes the following logic: | |||||
| if peer does not have all block parts for prs.ProposalBlockPart then | |||||
| blockMeta = Load Block Metadata for height prs.Height from blockStore | |||||
| if (!blockMeta.BlockID.PartsHeader == prs.ProposalBlockPartsHeader) then | |||||
| Sleep PeerGossipSleepDuration | |||||
| return | |||||
| Part = pick a random proposal block part the peer does not have | |||||
| Send BlockPartMessage(prs.Height, prs.Round, Part) to the peer on the DataChannel | |||||
| if send returns true, record that the peer knows the corresponding block Part | |||||
| return | |||||
| else Sleep PeerGossipSleepDuration | |||||
| ## Gossip Votes Routine | |||||
| It is used to send the following message: `VoteMessage` on the VoteChannel. | |||||
| The gossip votes routine is based on the local RoundState (`rs`) | |||||
| and the known PeerRoundState (`prs`). The routine repeats forever the logic shown below: | |||||
| ``` | |||||
| 1a) if rs.Height == prs.Height then | |||||
| if prs.Step == RoundStepNewHeight then | |||||
| vote = random vote from rs.LastCommit the peer does not have | |||||
| Send VoteMessage(vote) to the peer | |||||
| if send returns true, continue | |||||
| if prs.Step <= RoundStepPrevote and prs.Round != -1 and prs.Round <= rs.Round then | |||||
| Prevotes = rs.Votes.Prevotes(prs.Round) | |||||
| vote = random vote from Prevotes the peer does not have | |||||
| Send VoteMessage(vote) to the peer | |||||
| if send returns true, continue | |||||
| if prs.Step <= RoundStepPrecommit and prs.Round != -1 and prs.Round <= rs.Round then | |||||
| Precommits = rs.Votes.Precommits(prs.Round) | |||||
| vote = random vote from Precommits the peer does not have | |||||
| Send VoteMessage(vote) to the peer | |||||
| if send returns true, continue | |||||
| if prs.ProposalPOLRound != -1 then | |||||
| PolPrevotes = rs.Votes.Prevotes(prs.ProposalPOLRound) | |||||
| vote = random vote from PolPrevotes the peer does not have | |||||
| Send VoteMessage(vote) to the peer | |||||
| if send returns true, continue | |||||
| 1b) if prs.Height != 0 and rs.Height == prs.Height+1 then | |||||
| vote = random vote from rs.LastCommit peer does not have | |||||
| Send VoteMessage(vote) to the peer | |||||
| if send returns true, continue | |||||
| 1c) if prs.Height != 0 and rs.Height >= prs.Height+2 then | |||||
| Commit = get commit from BlockStore for prs.Height | |||||
| vote = random vote from Commit the peer does not have | |||||
| Send VoteMessage(vote) to the peer | |||||
| if send returns true, continue | |||||
| 2) Sleep PeerGossipSleepDuration | |||||
| ``` | |||||
| ## QueryMaj23Routine | |||||
| It is used to send the following message: `VoteSetMaj23Message`. `VoteSetMaj23Message` is sent to indicate that a given | |||||
| BlockID has seen +2/3 votes. This routine is based on the local RoundState (`rs`) and the known PeerRoundState | |||||
| (`prs`). The routine repeats forever the logic shown below. | |||||
| ``` | |||||
| 1a) if rs.Height == prs.Height then | |||||
| Prevotes = rs.Votes.Prevotes(prs.Round) | |||||
| if there is a ⅔ majority for some blockId in Prevotes then | |||||
| m = VoteSetMaj23Message(prs.Height, prs.Round, Prevote, blockId) | |||||
| Send m to peer | |||||
| Sleep PeerQueryMaj23SleepDuration | |||||
| 1b) if rs.Height == prs.Height then | |||||
| Precommits = rs.Votes.Precommits(prs.Round) | |||||
| if there is a ⅔ majority for some blockId in Precommits then | |||||
| m = VoteSetMaj23Message(prs.Height,prs.Round,Precommit,blockId) | |||||
| Send m to peer | |||||
| Sleep PeerQueryMaj23SleepDuration | |||||
| 1c) if rs.Height == prs.Height and prs.ProposalPOLRound >= 0 then | |||||
| Prevotes = rs.Votes.Prevotes(prs.ProposalPOLRound) | |||||
| if there is a ⅔ majority for some blockId in Prevotes then | |||||
| m = VoteSetMaj23Message(prs.Height,prs.ProposalPOLRound,Prevotes,blockId) | |||||
| Send m to peer | |||||
| Sleep PeerQueryMaj23SleepDuration | |||||
| 1d) if prs.CatchupCommitRound != -1 and 0 < prs.Height and | |||||
| prs.Height <= blockStore.Height() then | |||||
| Commit = LoadCommit(prs.Height) | |||||
| m = VoteSetMaj23Message(prs.Height,Commit.Round,Precommit,Commit.blockId) | |||||
| Send m to peer | |||||
| Sleep PeerQueryMaj23SleepDuration | |||||
| 2) Sleep PeerQueryMaj23SleepDuration | |||||
| ``` | |||||
| ## Broadcast routine | |||||
| The Broadcast routine subscribes to an internal event bus to receive new round steps and votes messages, and broadcasts messages to peers upon receiving those | |||||
| events. | |||||
| It broadcasts `NewRoundStepMessage` or `CommitStepMessage` upon new round state event. Note that | |||||
| broadcasting these messages does not depend on the PeerRoundState; it is sent on the StateChannel. | |||||
| Upon receiving VoteMessage it broadcasts `HasVoteMessage` message to its peers on the StateChannel. | |||||
| ## Channels | |||||
| Defines 4 channels: state, data, vote and vote_set_bits. Each channel | |||||
| has `SendQueueCapacity` and `RecvBufferCapacity` and | |||||
| `RecvMessageCapacity` set to `maxMsgSize`. | |||||
| Sending incorrectly encoded data will result in stopping the peer. | |||||
+ 0
- 184
docs/spec/reactors/consensus/consensus.md
View File
| @ -1,184 +0,0 @@ | |||||
| # Tendermint Consensus Reactor | |||||
| Tendermint Consensus is a distributed protocol executed by validator processes to agree on | |||||
| the next block to be added to the Tendermint blockchain. The protocol proceeds in rounds, where | |||||
| each round is a try to reach agreement on the next block. A round starts by having a dedicated | |||||
| process (called proposer) suggesting to other processes what should be the next block with | |||||
| the `ProposalMessage`. | |||||
| The processes respond by voting for a block with `VoteMessage` (there are two kinds of vote | |||||
| messages, prevote and precommit votes). Note that a proposal message is just a suggestion what the | |||||
| next block should be; a validator might vote with a `VoteMessage` for a different block. If in some | |||||
| round, enough number of processes vote for the same block, then this block is committed and later | |||||
| added to the blockchain. `ProposalMessage` and `VoteMessage` are signed by the private key of the | |||||
| validator. The internals of the protocol and how it ensures safety and liveness properties are | |||||
| explained in a forthcoming document. | |||||
| For efficiency reasons, validators in Tendermint consensus protocol do not agree directly on the | |||||
| block as the block size is big, i.e., they don't embed the block inside `Proposal` and | |||||
| `VoteMessage`. Instead, they reach agreement on the `BlockID` (see `BlockID` definition in | |||||
| [Blockchain](https://github.com/tendermint/tendermint/blob/master/docs/spec/blockchain/blockchain.md#blockid) section) that uniquely identifies each block. The block itself is | |||||
| disseminated to validator processes using peer-to-peer gossiping protocol. It starts by having a | |||||
| proposer first splitting a block into a number of block parts, that are then gossiped between | |||||
| processes using `BlockPartMessage`. | |||||
| Validators in Tendermint communicate by peer-to-peer gossiping protocol. Each validator is connected | |||||
| only to a subset of processes called peers. By the gossiping protocol, a validator send to its peers | |||||
| all needed information (`ProposalMessage`, `VoteMessage` and `BlockPartMessage`) so they can | |||||
| reach agreement on some block, and also obtain the content of the chosen block (block parts). As | |||||
| part of the gossiping protocol, processes also send auxiliary messages that inform peers about the | |||||
| executed steps of the core consensus algorithm (`NewRoundStepMessage` and `NewValidBlockMessage`), and | |||||
| also messages that inform peers what votes the process has seen (`HasVoteMessage`, | |||||
| `VoteSetMaj23Message` and `VoteSetBitsMessage`). These messages are then used in the gossiping | |||||
| protocol to determine what messages a process should send to its peers. | |||||
| We now describe the content of each message exchanged during Tendermint consensus protocol. | |||||
| ## ProposalMessage | |||||
| ProposalMessage is sent when a new block is proposed. It is a suggestion of what the | |||||
| next block in the blockchain should be. | |||||
| ```go | |||||
| type ProposalMessage struct { | |||||
| Proposal Proposal | |||||
| } | |||||
| ``` | |||||
| ### Proposal | |||||
| Proposal contains height and round for which this proposal is made, BlockID as a unique identifier | |||||
| of proposed block, timestamp, and POLRound (a so-called Proof-of-Lock (POL) round) that is needed for | |||||
| termination of the consensus. If POLRound >= 0, then BlockID corresponds to the block that | |||||
| is locked in POLRound. The message is signed by the validator private key. | |||||
| ```go | |||||
| type Proposal struct { | |||||
| Height int64 | |||||
| Round int | |||||
| POLRound int | |||||
| BlockID BlockID | |||||
| Timestamp Time | |||||
| Signature Signature | |||||
| } | |||||
| ``` | |||||
| ## VoteMessage | |||||
| VoteMessage is sent to vote for some block (or to inform others that a process does not vote in the | |||||
| current round). Vote is defined in the [Blockchain](https://github.com/tendermint/tendermint/blob/master/docs/spec/blockchain/blockchain.md#blockid) section and contains validator's | |||||
| information (validator address and index), height and round for which the vote is sent, vote type, | |||||
| blockID if process vote for some block (`nil` otherwise) and a timestamp when the vote is sent. The | |||||
| message is signed by the validator private key. | |||||
| ```go | |||||
| type VoteMessage struct { | |||||
| Vote Vote | |||||
| } | |||||
| ``` | |||||
| ## BlockPartMessage | |||||
| BlockPartMessage is sent when gossipping a piece of the proposed block. It contains height, round | |||||
| and the block part. | |||||
| ```go | |||||
| type BlockPartMessage struct { | |||||
| Height int64 | |||||
| Round int | |||||
| Part Part | |||||
| } | |||||
| ``` | |||||
| ## NewRoundStepMessage | |||||
| NewRoundStepMessage is sent for every step transition during the core consensus algorithm execution. | |||||
| It is used in the gossip part of the Tendermint protocol to inform peers about a current | |||||
| height/round/step a process is in. | |||||
| ```go | |||||
| type NewRoundStepMessage struct { | |||||
| Height int64 | |||||
| Round int | |||||
| Step RoundStepType | |||||
| SecondsSinceStartTime int | |||||
| LastCommitRound int | |||||
| } | |||||
| ``` | |||||
| ## NewValidBlockMessage | |||||
| NewValidBlockMessage is sent when a validator observes a valid block B in some round r, | |||||
| i.e., there is a Proposal for block B and 2/3+ prevotes for the block B in the round r. | |||||
| It contains height and round in which valid block is observed, block parts header that describes | |||||
| the valid block and is used to obtain all | |||||
| block parts, and a bit array of the block parts a process currently has, so its peers can know what | |||||
| parts it is missing so they can send them. | |||||
| In case the block is also committed, then IsCommit flag is set to true. | |||||
| ```go | |||||
| type NewValidBlockMessage struct { | |||||
| Height int64 | |||||
| Round int | |||||
| BlockPartsHeader PartSetHeader | |||||
| BlockParts BitArray | |||||
| IsCommit bool | |||||
| } | |||||
| ``` | |||||
| ## ProposalPOLMessage | |||||
| ProposalPOLMessage is sent when a previous block is re-proposed. | |||||
| It is used to inform peers in what round the process learned for this block (ProposalPOLRound), | |||||
| and what prevotes for the re-proposed block the process has. | |||||
| ```go | |||||
| type ProposalPOLMessage struct { | |||||
| Height int64 | |||||
| ProposalPOLRound int | |||||
| ProposalPOL BitArray | |||||
| } | |||||
| ``` | |||||
| ## HasVoteMessage | |||||
| HasVoteMessage is sent to indicate that a particular vote has been received. It contains height, | |||||
| round, vote type and the index of the validator that is the originator of the corresponding vote. | |||||
| ```go | |||||
| type HasVoteMessage struct { | |||||
| Height int64 | |||||
| Round int | |||||
| Type byte | |||||
| Index int | |||||
| } | |||||
| ``` | |||||
| ## VoteSetMaj23Message | |||||
| VoteSetMaj23Message is sent to indicate that a process has seen +2/3 votes for some BlockID. | |||||
| It contains height, round, vote type and the BlockID. | |||||
| ```go | |||||
| type VoteSetMaj23Message struct { | |||||
| Height int64 | |||||
| Round int | |||||
| Type byte | |||||
| BlockID BlockID | |||||
| } | |||||
| ``` | |||||
| ## VoteSetBitsMessage | |||||
| VoteSetBitsMessage is sent to communicate the bit-array of votes a process has seen for a given | |||||
| BlockID. It contains height, round, vote type, BlockID and a bit array of | |||||
| the votes a process has. | |||||
| ```go | |||||
| type VoteSetBitsMessage struct { | |||||
| Height int64 | |||||
| Round int | |||||
| Type byte | |||||
| BlockID BlockID | |||||
| Votes BitArray | |||||
| } | |||||
| ``` | |||||
+ 0
- 291
docs/spec/reactors/consensus/proposer-selection.md
View File
| @ -1,291 +0,0 @@ | |||||
| # Proposer selection procedure in Tendermint | |||||
| This document specifies the Proposer Selection Procedure that is used in Tendermint to choose a round proposer. | |||||
| As Tendermint is “leader-based protocol”, the proposer selection is critical for its correct functioning. | |||||
| At a given block height, the proposer selection algorithm runs with the same validator set at each round . | |||||
| Between heights, an updated validator set may be specified by the application as part of the ABCIResponses' EndBlock. | |||||
| ## Requirements for Proposer Selection | |||||
| This sections covers the requirements with Rx being mandatory and Ox optional requirements. | |||||
| The following requirements must be met by the Proposer Selection procedure: | |||||
| #### R1: Determinism | |||||
| Given a validator set `V`, and two honest validators `p` and `q`, for each height `h` and each round `r` the following must hold: | |||||
| `proposer_p(h,r) = proposer_q(h,r)` | |||||
| where `proposer_p(h,r)` is the proposer returned by the Proposer Selection Procedure at process `p`, at height `h` and round `r`. | |||||
| #### R2: Fairness | |||||
| Given a validator set with total voting power P and a sequence S of elections. In any sub-sequence of S with length C*P, a validator v must be elected as proposer P/VP(v) times, i.e. with frequency: | |||||
| f(v) ~ VP(v) / P | |||||
| where C is a tolerance factor for validator set changes with following values: | |||||
| - C == 1 if there are no validator set changes | |||||
| - C ~ k when there are validator changes | |||||
| *[this needs more work]* | |||||
| ### Basic Algorithm | |||||
| At its core, the proposer selection procedure uses a weighted round-robin algorithm. | |||||
| A model that gives a good intuition on how/ why the selection algorithm works and it is fair is that of a priority queue. The validators move ahead in this queue according to their voting power (the higher the voting power the faster a validator moves towards the head of the queue). When the algorithm runs the following happens: | |||||
| - all validators move "ahead" according to their powers: for each validator, increase the priority by the voting power | |||||
| - first in the queue becomes the proposer: select the validator with highest priority | |||||
| - move the proposer back in the queue: decrease the proposer's priority by the total voting power | |||||
| Notation: | |||||
| - vset - the validator set | |||||
| - n - the number of validators | |||||
| - VP(i) - voting power of validator i | |||||
| - A(i) - accumulated priority for validator i | |||||
| - P - total voting power of set | |||||
| - avg - average of all validator priorities | |||||
| - prop - proposer | |||||
| Simple view at the Selection Algorithm: | |||||
| ``` | |||||
| def ProposerSelection (vset): | |||||
| // compute priorities and elect proposer | |||||
| for each validator i in vset: | |||||
| A(i) += VP(i) | |||||
| prop = max(A) | |||||
| A(prop) -= P | |||||
| ``` | |||||
| ### Stable Set | |||||
| Consider the validator set: | |||||
| Validator | p1| p2 | |||||
| ----------|---|--- | |||||
| VP | 1 | 3 | |||||
| Assuming no validator changes, the following table shows the proposer priority computation over a few runs. Four runs of the selection procedure are shown, starting with the 5th the same values are computed. | |||||
| Each row shows the priority queue and the process place in it. The proposer is the closest to the head, the rightmost validator. As priorities are updated, the validators move right in the queue. The proposer moves left as its priority is reduced after election. | |||||
| |Priority Run | -2| -1| 0 | 1| 2 | 3 | 4 | 5 | Alg step | |||||
| |--------------- |---|---|---- |---|---- |---|---|---|-------- | |||||
| | | | |p1,p2| | | | | |Initialized to 0 | |||||
| |run 1 | | | | p1| | p2| | |A(i)+=VP(i) | |||||
| | | | p2| | p1| | | | |A(p2)-= P | |||||
| |run 2 | | | | |p1,p2| | | |A(i)+=VP(i) | |||||
| | | p1| | | | p2| | | |A(p1)-= P | |||||
| |run 3 | | p1| | | | | | p2|A(i)+=VP(i) | |||||
| | | | p1| | p2| | | | |A(p2)-= P | |||||
| |run 4 | | | p1| | | | p2| |A(i)+=VP(i) | |||||
| | | | |p1,p2| | | | | |A(p2)-= P | |||||
| It can be shown that: | |||||
| - At the end of each run k+1 the sum of the priorities is the same as at end of run k. If a new set's priorities are initialized to 0 then the sum of priorities will be 0 at each run while there are no changes. | |||||
| - The max distance between priorites is (n-1) * P. *[formal proof not finished]* | |||||
| ### Validator Set Changes | |||||
| Between proposer selection runs the validator set may change. Some changes have implications on the proposer election. | |||||
| #### Voting Power Change | |||||
| Consider again the earlier example and assume that the voting power of p1 is changed to 4: | |||||
| Validator | p1| p2 | |||||
| ----------|---| --- | |||||
| VP | 4 | 3 | |||||
| Let's also assume that before this change the proposer priorites were as shown in first row (last run). As it can be seen, the selection could run again, without changes, as before. | |||||
| |Priority Run| -2 | -1 | 0 | 1 | 2 | Comment | |||||
| |--------------| ---|--- |------|--- |--- |-------- | |||||
| | last run | | p2 | | p1 | |__update VP(p1)__ | |||||
| | next run | | | | | p2 |A(i)+=VP(i) | |||||
| | | p1 | | | | p2 |A(p1)-= P | |||||
| However, when a validator changes power from a high to a low value, some other validator remain far back in the queue for a long time. This scenario is considered again in the Proposer Priority Range section. | |||||
| As before: | |||||
| - At the end of each run k+1 the sum of the priorities is the same as at run k. | |||||
| - The max distance between priorites is (n-1) * P. | |||||
| #### Validator Removal | |||||
| Consider a new example with set: | |||||
| Validator | p1 | p2 | p3 | | |||||
| --------- |--- |--- |--- | | |||||
| VP | 1 | 2 | 3 | | |||||
| Let's assume that after the last run the proposer priorities were as shown in first row with their sum being 0. After p2 is removed, at the end of next proposer selection run (penultimate row) the sum of priorities is -2 (minus the priority of the removed process). | |||||
| The procedure could continue without modifications. However, after a sufficiently large number of modifications in validator set, the priority values would migrate towards maximum or minimum allowed values causing truncations due to overflow detection. | |||||
| For this reason, the selection procedure adds another __new step__ that centers the current priority values such that the priority sum remains close to 0. | |||||
| |Priority Run |-3 | -2 | -1 | 0 | 1 | 2 | 4 |Comment | |||||
| |--------------- |--- | ---|--- |--- |--- |--- |---|-------- | |||||
| | last run |p3 | | | | p1 | p2 | |__remove p2__ | |||||
| | nextrun | | | | | | | | | |||||
| | __new step__ | | p3 | | | | p1 | |A(i) -= avg, avg = -1 | |||||
| | | | | | | p3 | p1 | |A(i)+=VP(i) | |||||
| | | | | p1 | | p3 | | |A(p1)-= P | |||||
| The modified selection algorithm is: | |||||
| def ProposerSelection (vset): | |||||
| // center priorities around zero | |||||
| avg = sum(A(i) for i in vset)/len(vset) | |||||
| for each validator i in vset: | |||||
| A(i) -= avg | |||||
| // compute priorities and elect proposer | |||||
| for each validator i in vset: | |||||
| A(i) += VP(i) | |||||
| prop = max(A) | |||||
| A(prop) -= P | |||||
| Observations: | |||||
| - The sum of priorities is now close to 0. Due to integer division the sum is an integer in (-n, n), where n is the number of validators. | |||||
| #### New Validator | |||||
| When a new validator is added, same problem as the one described for removal appears, the sum of priorities in the new set is not zero. This is fixed with the centering step introduced above. | |||||
| One other issue that needs to be addressed is the following. A validator V that has just been elected is moved to the end of the queue. If the validator set is large and/ or other validators have significantly higher power, V will have to wait many runs to be elected. If V removes and re-adds itself to the set, it would make a significant (albeit unfair) "jump" ahead in the queue. | |||||
| In order to prevent this, when a new validator is added, its initial priority is set to: | |||||
| A(V) = -1.125 * P | |||||
| where P is the total voting power of the set including V. | |||||
| Curent implementation uses the penalty factor of 1.125 because it provides a small punishment that is efficient to calculate. See [here](https://github.com/tendermint/tendermint/pull/2785#discussion_r235038971) for more details. | |||||
| If we consider the validator set where p3 has just been added: | |||||
| Validator | p1 | p2 | p3 | |||||
| ----------|--- |--- |--- | |||||
| VP | 1 | 3 | 8 | |||||
| then p3 will start with proposer priority: | |||||
| A(p3) = -1.125 * (1 + 3 + 8) ~ -13 | |||||
| Note that since current computation uses integer division there is penalty loss when sum of the voting power is less than 8. | |||||
| In the next run, p3 will still be ahead in the queue, elected as proposer and moved back in the queue. | |||||
| |Priority Run |-13 | -9 | -5 | -2 | -1 | 0 | 1 | 2 | 5 | 6 | 7 |Alg step | |||||
| |---------------|--- |--- |--- |----|--- |--- |---|---|---|---|---|-------- | |||||
| |last run | | | | p2 | | | | p1| | | |__add p3__ | |||||
| | | p3 | | | p2 | | | | p1| | | |A(p3) = -4 | |||||
| |next run | | p3 | | | | | | p2| | p1| |A(i) -= avg, avg = -4 | |||||
| | | | | | | p3 | | | | p2| | p1|A(i)+=VP(i) | |||||
| | | | | p1 | | p3 | | | | p2| | |A(p1)-=P | |||||
| ### Proposer Priority Range | |||||
| With the introduction of centering, some interesting cases occur. Low power validators that bind early in a set that includes high power validator(s) benefit from subsequent additions to the set. This is because these early validators run through more right shift operations during centering, operations that increase their priority. | |||||
| As an example, consider the set where p2 is added after p1, with priority -1.125 * 80k = -90k. After the selection procedure runs once: | |||||
| Validator | p1 | p2 | Comment | |||||
| ----------|-----|---- |--- | |||||
| VP | 80k | 10 | | |||||
| A | 0 |-90k | __added p2__ | |||||
| A |-45k | 45k | __run selection__ | |||||
| Then execute the following steps: | |||||
| 1. Add a new validator p3: | |||||
| Validator | p1 | p2 | p3 | |||||
| ----------|-----|--- |---- | |||||
| VP | 80k | 10 | 10 | |||||
| 2. Run selection once. The notation '..p'/'p..' means very small deviations compared to column priority. | |||||
| |Priority Run | -90k..| -60k | -45k | -15k| 0 | 45k | 75k | 155k | Comment | |||||
| |--------------|------ |----- |------- |---- |---|---- |----- |------- |--------- | |||||
| | last run | p3 | | p2 | | | p1 | | | __added p3__ | |||||
| | next run | |||||
| | *right_shift*| | p3 | | p2 | | | p1 | | A(i) -= avg,avg=-30k | |||||
| | | | ..p3| | ..p2| | | | p1 | A(i)+=VP(i) | |||||
| | | | ..p3| | ..p2| | | p1.. | | A(p1)-=P, P=80k+20 | |||||
| 3. Remove p1 and run selection once: | |||||
| Validator | p3 | p2 | Comment | |||||
| ----------|----- |---- |-------- | |||||
| VP | 10 | 10 | | |||||
| A |-60k |-15k | | |||||
| A |-22.5k|22.5k| __run selection__ | |||||
| At this point, while the total voting power is 20, the distance between priorities is 45k. It will take 4500 runs for p3 to catch up with p2. | |||||
| In order to prevent these types of scenarios, the selection algorithm performs scaling of priorities such that the difference between min and max values is smaller than two times the total voting power. | |||||
| The modified selection algorithm is: | |||||
| def ProposerSelection (vset): | |||||
| // scale the priority values | |||||
| diff = max(A)-min(A) | |||||
| threshold = 2 * P | |||||
| if diff > threshold: | |||||
| scale = diff/threshold | |||||
| for each validator i in vset: | |||||
| A(i) = A(i)/scale | |||||
| // center priorities around zero | |||||
| avg = sum(A(i) for i in vset)/len(vset) | |||||
| for each validator i in vset: | |||||
| A(i) -= avg | |||||
| // compute priorities and elect proposer | |||||
| for each validator i in vset: | |||||
| A(i) += VP(i) | |||||
| prop = max(A) | |||||
| A(prop) -= P | |||||
| Observations: | |||||
| - With this modification, the maximum distance between priorites becomes 2 * P. | |||||
| Note also that even during steady state the priority range may increase beyond 2 * P. The scaling introduced here helps to keep the range bounded. | |||||
| ### Wrinkles | |||||
| #### Validator Power Overflow Conditions | |||||
| The validator voting power is a positive number stored as an int64. When a validator is added the `1.125 * P` computation must not overflow. As a consequence the code handling validator updates (add and update) checks for overflow conditions making sure the total voting power is never larger than the largest int64 `MAX`, with the property that `1.125 * MAX` is still in the bounds of int64. Fatal error is return when overflow condition is detected. | |||||
| #### Proposer Priority Overflow/ Underflow Handling | |||||
| The proposer priority is stored as an int64. The selection algorithm performs additions and subtractions to these values and in the case of overflows and underflows it limits the values to: | |||||
| MaxInt64 = 1 << 63 - 1 | |||||
| MinInt64 = -1 << 63 | |||||
| ### Requirement Fulfillment Claims | |||||
| __[R1]__ | |||||
| The proposer algorithm is deterministic giving consistent results across executions with same transactions and validator set modifications. | |||||
| [WIP - needs more detail] | |||||
| __[R2]__ | |||||
| Given a set of processes with the total voting power P, during a sequence of elections of length P, the number of times any process is selected as proposer is equal to its voting power. The sequence of the P proposers then repeats. If we consider the validator set: | |||||
| Validator | p1| p2 | |||||
| ----------|---|--- | |||||
| VP | 1 | 3 | |||||
| With no other changes to the validator set, the current implementation of proposer selection generates the sequence: | |||||
| `p2, p1, p2, p2, p2, p1, p2, p2,...` or [`p2, p1, p2, p2`]* | |||||
| A sequence that starts with any circular permutation of the [`p2, p1, p2, p2`] sub-sequence would also provide the same degree of fairness. In fact these circular permutations show in the sliding window (over the generated sequence) of size equal to the length of the sub-sequence. | |||||
| Assigning priorities to each validator based on the voting power and updating them at each run ensures the fairness of the proposer selection. In addition, every time a validator is elected as proposer its priority is decreased with the total voting power. | |||||
| Intuitively, a process v jumps ahead in the queue at most (max(A) - min(A))/VP(v) times until it reaches the head and is elected. The frequency is then: | |||||
| f(v) ~ VP(v)/(max(A)-min(A)) = 1/k * VP(v)/P | |||||
| For current implementation, this means v should be proposer at least VP(v) times out of k * P runs, with scaling factor k=2. | |||||
+ 0
- 10
docs/spec/reactors/evidence/reactor.md
View File
| @ -1,10 +0,0 @@ | |||||
| # Evidence Reactor | |||||
| ## Channels | |||||
| [#1503](https://github.com/tendermint/tendermint/issues/1503) | |||||
| Sending invalid evidence will result in stopping the peer. | |||||
| Sending incorrectly encoded data or data exceeding `maxMsgSize` will result | |||||
| in stopping the peer. | |||||
+ 0
- 8
docs/spec/reactors/mempool/concurrency.md
View File
| @ -1,8 +0,0 @@ | |||||
| # Mempool Concurrency | |||||
| Look at the concurrency model this uses... | |||||
| - Receiving CheckTx | |||||
| - Broadcasting new tx | |||||
| - Interfaces with consensus engine, reap/update while checking | |||||
| - Calling the ABCI app (ordering. callbacks. how proxy works alongside the blockchain proxy which actually writes blocks) | |||||
+ 0
- 54
docs/spec/reactors/mempool/config.md
View File
| @ -1,54 +0,0 @@ | |||||
| # Mempool Configuration | |||||
| Here we describe configuration options around mempool. | |||||
| For the purposes of this document, they are described | |||||
| as command-line flags, but they can also be passed in as | |||||
| environmental variables or in the config.toml file. The | |||||
| following are all equivalent: | |||||
| Flag: `--mempool.recheck=false` | |||||
| Environment: `TM_MEMPOOL_RECHECK=false` | |||||
| Config: | |||||
| ``` | |||||
| [mempool] | |||||
| recheck = false | |||||
| ``` | |||||
| ## Recheck | |||||
| `--mempool.recheck=false` (default: true) | |||||
| Recheck determines if the mempool rechecks all pending | |||||
| transactions after a block was committed. Once a block | |||||
| is committed, the mempool removes all valid transactions | |||||
| that were successfully included in the block. | |||||
| If `recheck` is true, then it will rerun CheckTx on | |||||
| all remaining transactions with the new block state. | |||||
| ## Broadcast | |||||
| `--mempool.broadcast=false` (default: true) | |||||
| Determines whether this node gossips any valid transactions | |||||
| that arrive in mempool. Default is to gossip anything that | |||||
| passes checktx. If this is disabled, transactions are not | |||||
| gossiped, but instead stored locally and added to the next | |||||
| block this node is the proposer. | |||||
| ## WalDir | |||||
| `--mempool.wal_dir=/tmp/gaia/mempool.wal` (default: $TM_HOME/data/mempool.wal) | |||||
| This defines the directory where mempool writes the write-ahead | |||||
| logs. These files can be used to reload unbroadcasted | |||||
| transactions if the node crashes. | |||||
| If the directory passed in is an absolute path, the wal file is | |||||
| created there. If the directory is a relative path, the path is | |||||
| appended to home directory of the tendermint process to | |||||
| generate an absolute path to the wal directory | |||||
| (default `$HOME/.tendermint` or set via `TM_HOME` or `--home`) | |||||
+ 0
- 43
docs/spec/reactors/mempool/functionality.md
View File
| @ -1,43 +0,0 @@ | |||||
| # Mempool Functionality | |||||
| The mempool maintains a list of potentially valid transactions, | |||||
| both to broadcast to other nodes, as well as to provide to the | |||||
| consensus reactor when it is selected as the block proposer. | |||||
| There are two sides to the mempool state: | |||||
| - External: get, check, and broadcast new transactions | |||||
| - Internal: return valid transaction, update list after block commit | |||||
| ## External functionality | |||||
| External functionality is exposed via network interfaces | |||||
| to potentially untrusted actors. | |||||
| - CheckTx - triggered via RPC or P2P | |||||
| - Broadcast - gossip messages after a successful check | |||||
| ## Internal functionality | |||||
| Internal functionality is exposed via method calls to other | |||||
| code compiled into the tendermint binary. | |||||
| - ReapMaxBytesMaxGas - get txs to propose in the next block. Guarantees that the | |||||
| size of the txs is less than MaxBytes, and gas is less than MaxGas | |||||
| - Update - remove tx that were included in last block | |||||
| - ABCI.CheckTx - call ABCI app to validate the tx | |||||
| What does it provide the consensus reactor? | |||||
| What guarantees does it need from the ABCI app? | |||||
| (talk about interleaving processes in concurrency) | |||||
| ## Optimizations | |||||
| The implementation within this library also implements a tx cache. | |||||
| This is so that signatures don't have to be reverified if the tx has | |||||
| already been seen before. | |||||
| However, we only store valid txs in the cache, not invalid ones. | |||||
| This is because invalid txs could become good later. | |||||
| Txs that are included in a block aren't removed from the cache, | |||||
| as they still may be getting received over the p2p network. | |||||
| These txs are stored in the cache by their hash, to mitigate memory concerns. | |||||
+ 0
- 61
docs/spec/reactors/mempool/messages.md
View File
| @ -1,61 +0,0 @@ | |||||
| # Mempool Messages | |||||
| ## P2P Messages | |||||
| There is currently only one message that Mempool broadcasts | |||||
| and receives over the p2p gossip network (via the reactor): | |||||
| `TxMessage` | |||||
| ```go | |||||
| // TxMessage is a MempoolMessage containing a transaction. | |||||
| type TxMessage struct { | |||||
| Tx types.Tx | |||||
| } | |||||
| ``` | |||||
| TxMessage is go-amino encoded and prepended with `0x1` as a | |||||
| "type byte". This is followed by a go-amino encoded byte-slice. | |||||
| Prefix of 40=0x28 byte tx is: `0x010128...` followed by | |||||
| the actual 40-byte tx. Prefix of 350=0x015e byte tx is: | |||||
| `0x0102015e...` followed by the actual 350 byte tx. | |||||
| (Please see the [go-amino repo](https://github.com/tendermint/go-amino#an-interface-example) for more information) | |||||
| ## RPC Messages | |||||
| Mempool exposes `CheckTx([]byte)` over the RPC interface. | |||||
| It can be posted via `broadcast_commit`, `broadcast_sync` or | |||||
| `broadcast_async`. They all parse a message with one argument, | |||||
| `"tx": "HEX_ENCODED_BINARY"` and differ in only how long they | |||||
| wait before returning (sync makes sure CheckTx passes, commit | |||||
| makes sure it was included in a signed block). | |||||
| Request (`POST http://gaia.zone:26657/`): | |||||
| ```json | |||||
| { | |||||
| "id": "", | |||||
| "jsonrpc": "2.0", | |||||
| "method": "broadcast_sync", | |||||
| "params": { | |||||
| "tx": "F012A4BC68..." | |||||
| } | |||||
| } | |||||
| ``` | |||||
| Response: | |||||
| ```json | |||||
| { | |||||
| "error": "", | |||||
| "result": { | |||||
| "hash": "E39AAB7A537ABAA237831742DCE1117F187C3C52", | |||||
| "log": "", | |||||
| "data": "", | |||||
| "code": 0 | |||||
| }, | |||||
| "id": "", | |||||
| "jsonrpc": "2.0" | |||||
| } | |||||
| ``` | |||||
+ 0
- 22
docs/spec/reactors/mempool/reactor.md
View File
| @ -1,22 +0,0 @@ | |||||
| # Mempool Reactor | |||||
| ## Channels | |||||
| See [this issue](https://github.com/tendermint/tendermint/issues/1503) | |||||
| Mempool maintains a cache of the last 10000 transactions to prevent | |||||
| replaying old transactions (plus transactions coming from other | |||||
| validators, who are continually exchanging transactions). Read [Replay | |||||
| Protection](../../../app-dev/app-development.md#replay-protection) | |||||
| for details. | |||||
| Sending incorrectly encoded data or data exceeding `maxMsgSize` will result | |||||
| in stopping the peer. | |||||
| The mempool will not send a tx back to any peer which it received it from. | |||||
| The reactor assigns an `uint16` number for each peer and maintains a map from | |||||
| p2p.ID to `uint16`. Each mempool transaction carries a list of all the senders | |||||
| (`[]uint16`). The list is updated every time mempool receives a transaction it | |||||
| is already seen. `uint16` assumes that a node will never have over 65535 active | |||||
| peers (0 is reserved for unknown source - e.g. RPC). | |||||
+ 0
- 132
docs/spec/reactors/pex/pex.md
View File
| @ -1,132 +0,0 @@ | |||||
| # Peer Strategy and Exchange | |||||
| Here we outline the design of the AddressBook | |||||
| and how it used by the Peer Exchange Reactor (PEX) to ensure we are connected | |||||
| to good peers and to gossip peers to others. | |||||
| ## Peer Types | |||||
| Certain peers are special in that they are specified by the user as `persistent`, | |||||
| which means we auto-redial them if the connection fails, or if we fail to dial | |||||
| them. | |||||
| Some peers can be marked as `private`, which means | |||||
| we will not put them in the address book or gossip them to others. | |||||
| All peers except private peers and peers coming from them are tracked using the | |||||
| address book. | |||||
| The rest of our peers are only distinguished by being either | |||||
| inbound (they dialed our public address) or outbound (we dialed them). | |||||
| ## Discovery | |||||
| Peer discovery begins with a list of seeds. | |||||
| When we don't have enough peers, we | |||||
| 1. ask existing peers | |||||
| 2. dial seeds if we're not dialing anyone currently | |||||
| On startup, we will also immediately dial the given list of `persistent_peers`, | |||||
| and will attempt to maintain persistent connections with them. If the | |||||
| connections die, or we fail to dial, we will redial every 5s for a few minutes, | |||||
| then switch to an exponential backoff schedule, and after about a day of | |||||
| trying, stop dialing the peer. | |||||
| As long as we have less than `MaxNumOutboundPeers`, we periodically request | |||||
| additional peers from each of our own and try seeds. | |||||
| ## Listening | |||||
| Peers listen on a configurable ListenAddr that they self-report in their | |||||
| NodeInfo during handshakes with other peers. Peers accept up to | |||||
| `MaxNumInboundPeers` incoming peers. | |||||
| ## Address Book | |||||
| Peers are tracked via their ID (their PubKey.Address()). | |||||
| Peers are added to the address book from the PEX when they first connect to us or | |||||
| when we hear about them from other peers. | |||||
| The address book is arranged in sets of buckets, and distinguishes between | |||||
| vetted (old) and unvetted (new) peers. It keeps different sets of buckets for vetted and | |||||
| unvetted peers. Buckets provide randomization over peer selection. Peers are put | |||||
| in buckets according to their IP groups. | |||||
| A vetted peer can only be in one bucket. An unvetted peer can be in multiple buckets, and | |||||
| each instance of the peer can have a different IP:PORT. | |||||
| If we're trying to add a new peer but there's no space in its bucket, we'll | |||||
| remove the worst peer from that bucket to make room. | |||||
| ## Vetting | |||||
| When a peer is first added, it is unvetted. | |||||
| Marking a peer as vetted is outside the scope of the `p2p` package. | |||||
| For Tendermint, a Peer becomes vetted once it has contributed sufficiently | |||||
| at the consensus layer; ie. once it has sent us valid and not-yet-known | |||||
| votes and/or block parts for `NumBlocksForVetted` blocks. | |||||
| Other users of the p2p package can determine their own conditions for when a peer is marked vetted. | |||||
| If a peer becomes vetted but there are already too many vetted peers, | |||||
| a randomly selected one of the vetted peers becomes unvetted. | |||||
| If a peer becomes unvetted (either a new peer, or one that was previously vetted), | |||||
| a randomly selected one of the unvetted peers is removed from the address book. | |||||
| More fine-grained tracking of peer behaviour can be done using | |||||
| a trust metric (see below), but it's best to start with something simple. | |||||
| ## Select Peers to Dial | |||||
| When we need more peers, we pick addresses randomly from the addrbook with some | |||||
| configurable bias for unvetted peers. The bias should be lower when we have | |||||
| fewer peers and can increase as we obtain more, ensuring that our first peers | |||||
| are more trustworthy, but always giving us the chance to discover new good | |||||
| peers. | |||||
| We track the last time we dialed a peer and the number of unsuccessful attempts | |||||
| we've made. If too many attempts are made, we mark the peer as bad. | |||||
| Connection attempts are made with exponential backoff (plus jitter). Because | |||||
| the selection process happens every `ensurePeersPeriod`, we might not end up | |||||
| dialing a peer for much longer than the backoff duration. | |||||
| If we fail to connect to the peer after 16 tries (with exponential backoff), we | |||||
| remove from address book completely. | |||||
| ## Select Peers to Exchange | |||||
| When we’re asked for peers, we select them as follows: | |||||
| - select at most `maxGetSelection` peers | |||||
| - try to select at least `minGetSelection` peers - if we have less than that, select them all. | |||||
| - select a random, unbiased `getSelectionPercent` of the peers | |||||
| Send the selected peers. Note we select peers for sending without bias for vetted/unvetted. | |||||
| ## Preventing Spam | |||||
| There are various cases where we decide a peer has misbehaved and we disconnect from them. | |||||
| When this happens, the peer is removed from the address book and black listed for | |||||
| some amount of time. We call this "Disconnect and Mark". | |||||
| Note that the bad behaviour may be detected outside the PEX reactor itself | |||||
| (for instance, in the mconnection, or another reactor), but it must be communicated to the PEX reactor | |||||
| so it can remove and mark the peer. | |||||
| In the PEX, if a peer sends us an unsolicited list of peers, | |||||
| or if the peer sends a request too soon after another one, | |||||
| we Disconnect and MarkBad. | |||||
| ## Trust Metric | |||||
| The quality of peers can be tracked in more fine-grained detail using a | |||||
| Proportional-Integral-Derivative (PID) controller that incorporates | |||||
| current, past, and rate-of-change data to inform peer quality. | |||||
| While a PID trust metric has been implemented, it remains for future work | |||||
| to use it in the PEX. | |||||
| See the [trustmetric](https://github.com/tendermint/tendermint/blob/master/docs/architecture/adr-006-trust-metric.md) | |||||
| and [trustmetric useage](https://github.com/tendermint/tendermint/blob/master/docs/architecture/adr-007-trust-metric-usage.md) | |||||
| architecture docs for more details. | |||||
+ 0
- 12
docs/spec/reactors/pex/reactor.md
View File
| @ -1,12 +0,0 @@ | |||||
| # PEX Reactor | |||||
| ## Channels | |||||
| Defines only `SendQueueCapacity`. [#1503](https://github.com/tendermint/tendermint/issues/1503) | |||||
| Implements rate-limiting by enforcing minimal time between two consecutive | |||||
| `pexRequestMessage` requests. If the peer sends us addresses we did not ask, | |||||
| it is stopped. | |||||
| Sending incorrectly encoded data or data exceeding `maxMsgSize` will result | |||||
| in stopping the peer. | |||||
+ 0
- 5
docs/spec/reactors/readme.md
View File
| @ -1,5 +0,0 @@ | |||||
| --- | |||||
| cards: true | |||||
| --- | |||||
| # Reactors | |||||
+ 0
- 16
docs/spec/scripts/crypto.go
View File
| @ -1,16 +0,0 @@ | |||||
| package main | |||||
| import ( | |||||
| "fmt" | |||||
| "os" | |||||
| amino "github.com/tendermint/go-amino" | |||||
| cryptoamino "github.com/tendermint/tendermint/crypto/encoding/amino" | |||||
| ) | |||||
| func main() { | |||||
| cdc := amino.NewCodec() | |||||
| cryptoamino.RegisterAmino(cdc) | |||||
| cdc.PrintTypes(os.Stdout) | |||||
| fmt.Println("") | |||||
| } | |||||