
 Marko
3 years ago
Marko
3 years ago
committed by
 GitHub
GitHub
GitHub
No known key found for this signature in database
GPG Key ID: 4AEE18F83AFDEB23
15 changed files with 1200 additions and 70 deletions
Unified View
Diff Options
-
+4 -3docs/tendermint-core/README.md
-
+9 -1docs/tendermint-core/block-sync/README.md
-
BINdocs/tendermint-core/block-sync/img/bc-reactor-routines.png
-
BINdocs/tendermint-core/block-sync/img/bc-reactor.png
-
+47 -0docs/tendermint-core/block-sync/implementation.md
-
+278 -0docs/tendermint-core/block-sync/reactor.md
-
+41 -0docs/tendermint-core/consensus/README.md
-
+370 -0docs/tendermint-core/consensus/reactor.md
-
+13 -0docs/tendermint-core/evidence/README.md
-
+0 -48docs/tendermint-core/mempool.md
-
+71 -0docs/tendermint-core/mempool/README.md
-
+105 -0docs/tendermint-core/mempool/config.md
-
+177 -0docs/tendermint-core/pex/README.md
-
+0 -18docs/tendermint-core/state-sync.md
-
+85 -0docs/tendermint-core/state-sync/README.md
+ 4
- 3
docs/tendermint-core/README.md
View File
docs/tendermint-core/block-sync.md → docs/tendermint-core/block-sync/README.md
View File
BIN
docs/tendermint-core/block-sync/img/bc-reactor-routines.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 1602 | Height: 1132 | Size: 265 KiB |
BIN
docs/tendermint-core/block-sync/img/bc-reactor.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 1520 | Height: 1340 | Size: 43 KiB |
+ 47
- 0
docs/tendermint-core/block-sync/implementation.md
View File
| @ -0,0 +1,47 @@ | |||||
| --- | |||||
| order: 3 | |||||
| --- | |||||
| # Implementation | |||||
| ## Blocksync Reactor | |||||
| - coordinates the pool for syncing | |||||
| - coordinates the store for persistence | |||||
| - coordinates the playing of blocks towards the app using a sm.BlockExecutor | |||||
| - handles switching between fastsync and consensus | |||||
| - it is a p2p.BaseReactor | |||||
| - starts the pool.Start() and its poolRoutine() | |||||
| - registers all the concrete types and interfaces for serialisation | |||||
| ### poolRoutine | |||||
| - listens to these channels: | |||||
| - pool requests blocks from a specific peer by posting to requestsCh, block reactor then sends | |||||
| a &bcBlockRequestMessage for a specific height | |||||
| - pool signals timeout of a specific peer by posting to timeoutsCh | |||||
| - switchToConsensusTicker to periodically try and switch to consensus | |||||
| - trySyncTicker to periodically check if we have fallen behind and then catch-up sync | |||||
| - if there aren't any new blocks available on the pool it skips syncing | |||||
| - tries to sync the app by taking downloaded blocks from the pool, gives them to the app and stores | |||||
| them on disk | |||||
| - implements Receive which is called by the switch/peer | |||||
| - calls AddBlock on the pool when it receives a new block from a peer | |||||
| ## Block Pool | |||||
| - responsible for downloading blocks from peers | |||||
| - makeRequestersRoutine() | |||||
| - removes timeout peers | |||||
| - starts new requesters by calling makeNextRequester() | |||||
| - requestRoutine(): | |||||
| - picks a peer and sends the request, then blocks until: | |||||
| - pool is stopped by listening to pool.Quit | |||||
| - requester is stopped by listening to Quit | |||||
| - request is redone | |||||
| - we receive a block | |||||
| - gotBlockCh is strange | |||||
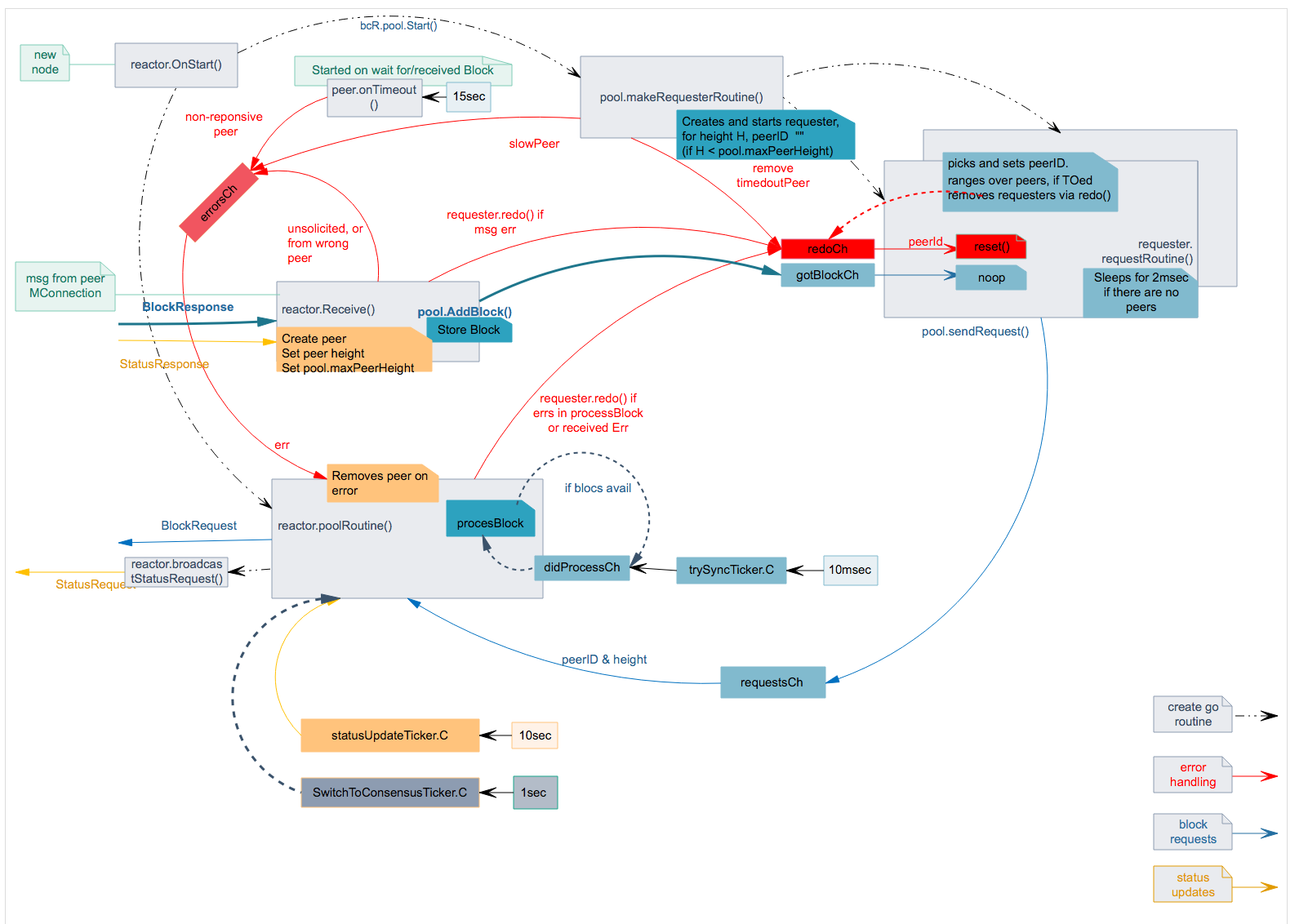
| ## Go Routines in Blocksync Reactor | |||||
|  | |||||
+ 278
- 0
docs/tendermint-core/block-sync/reactor.md
View File
| @ -0,0 +1,278 @@ | |||||
| --- | |||||
| order: 2 | |||||
| --- | |||||
| # Reactor | |||||
| The Blocksync Reactor's high level responsibility is to enable peers who are | |||||
| far behind the current state of the consensus to quickly catch up by downloading | |||||
| many blocks in parallel, verifying their commits, and executing them against the | |||||
| ABCI application. | |||||
| Tendermint full nodes run the Blocksync Reactor as a service to provide blocks | |||||
| to new nodes. New nodes run the Blocksync Reactor in "fast_sync" mode, | |||||
| where they actively make requests for more blocks until they sync up. | |||||
| Once caught up, "fast_sync" mode is disabled and the node switches to | |||||
| using (and turns on) the Consensus Reactor. | |||||
| ## Architecture and algorithm | |||||
| The Blocksync reactor is organised as a set of concurrent tasks: | |||||
| - Receive routine of Blocksync Reactor | |||||
| - Task for creating Requesters | |||||
| - Set of Requesters tasks and - Controller task. | |||||
|  | |||||
| ### Data structures | |||||
| These are the core data structures necessarily to provide the Blocksync Reactor logic. | |||||
| Requester data structure is used to track assignment of request for `block` at position `height` to a peer with id equals to `peerID`. | |||||
| ```go | |||||
| type Requester { | |||||
| mtx Mutex | |||||
| block Block | |||||
| height int64 | |||||
| peerID p2p.ID | |||||
| redoChannel chan p2p.ID //redo may send multi-time; peerId is used to identify repeat | |||||
| } | |||||
| ``` | |||||
| Pool is a core data structure that stores last executed block (`height`), assignment of requests to peers (`requesters`), current height for each peer and number of pending requests for each peer (`peers`), maximum peer height, etc. | |||||
| ```go | |||||
| type Pool { | |||||
| mtx Mutex | |||||
| requesters map[int64]*Requester | |||||
| height int64 | |||||
| peers map[p2p.ID]*Peer | |||||
| maxPeerHeight int64 | |||||
| numPending int32 | |||||
| store BlockStore | |||||
| requestsChannel chan<- BlockRequest | |||||
| errorsChannel chan<- peerError | |||||
| } | |||||
| ``` | |||||
| Peer data structure stores for each peer current `height` and number of pending requests sent to the peer (`numPending`), etc. | |||||
| ```go | |||||
| type Peer struct { | |||||
| id p2p.ID | |||||
| height int64 | |||||
| numPending int32 | |||||
| timeout *time.Timer | |||||
| didTimeout bool | |||||
| } | |||||
| ``` | |||||
| BlockRequest is internal data structure used to denote current mapping of request for a block at some `height` to a peer (`PeerID`). | |||||
| ```go | |||||
| type BlockRequest { | |||||
| Height int64 | |||||
| PeerID p2p.ID | |||||
| } | |||||
| ``` | |||||
| ### Receive routine of Blocksync Reactor | |||||
| It is executed upon message reception on the BlocksyncChannel inside p2p receive routine. There is a separate p2p receive routine (and therefore receive routine of the Blocksync Reactor) executed for each peer. Note that try to send will not block (returns immediately) if outgoing buffer is full. | |||||
| ```go | |||||
| handleMsg(pool, m): | |||||
| upon receiving bcBlockRequestMessage m from peer p: | |||||
| block = load block for height m.Height from pool.store | |||||
| if block != nil then | |||||
| try to send BlockResponseMessage(block) to p | |||||
| else | |||||
| try to send bcNoBlockResponseMessage(m.Height) to p | |||||
| upon receiving bcBlockResponseMessage m from peer p: | |||||
| pool.mtx.Lock() | |||||
| requester = pool.requesters[m.Height] | |||||
| if requester == nil then | |||||
| error("peer sent us a block we didn't expect") | |||||
| continue | |||||
| if requester.block == nil and requester.peerID == p then | |||||
| requester.block = m | |||||
| pool.numPending -= 1 // atomic decrement | |||||
| peer = pool.peers[p] | |||||
| if peer != nil then | |||||
| peer.numPending-- | |||||
| if peer.numPending == 0 then | |||||
| peer.timeout.Stop() | |||||
| // NOTE: we don't send Quit signal to the corresponding requester task! | |||||
| else | |||||
| trigger peer timeout to expire after peerTimeout | |||||
| pool.mtx.Unlock() | |||||
| upon receiving bcStatusRequestMessage m from peer p: | |||||
| try to send bcStatusResponseMessage(pool.store.Height) | |||||
| upon receiving bcStatusResponseMessage m from peer p: | |||||
| pool.mtx.Lock() | |||||
| peer = pool.peers[p] | |||||
| if peer != nil then | |||||
| peer.height = m.height | |||||
| else | |||||
| peer = create new Peer data structure with id = p and height = m.Height | |||||
| pool.peers[p] = peer | |||||
| if m.Height > pool.maxPeerHeight then | |||||
| pool.maxPeerHeight = m.Height | |||||
| pool.mtx.Unlock() | |||||
| onTimeout(p): | |||||
| send error message to pool error channel | |||||
| peer = pool.peers[p] | |||||
| peer.didTimeout = true | |||||
| ``` | |||||
| ### Requester tasks | |||||
| Requester task is responsible for fetching a single block at position `height`. | |||||
| ```go | |||||
| fetchBlock(height, pool): | |||||
| while true do { | |||||
| peerID = nil | |||||
| block = nil | |||||
| peer = pickAvailablePeer(height) | |||||
| peerID = peer.id | |||||
| enqueue BlockRequest(height, peerID) to pool.requestsChannel | |||||
| redo = false | |||||
| while !redo do | |||||
| select { | |||||
| upon receiving Quit message do | |||||
| return | |||||
| upon receiving redo message with id on redoChannel do | |||||
| if peerID == id { | |||||
| mtx.Lock() | |||||
| pool.numPending++ | |||||
| redo = true | |||||
| mtx.UnLock() | |||||
| } | |||||
| } | |||||
| } | |||||
| pickAvailablePeer(height): | |||||
| selectedPeer = nil | |||||
| while selectedPeer = nil do | |||||
| pool.mtx.Lock() | |||||
| for each peer in pool.peers do | |||||
| if !peer.didTimeout and peer.numPending < maxPendingRequestsPerPeer and peer.height >= height then | |||||
| peer.numPending++ | |||||
| selectedPeer = peer | |||||
| break | |||||
| pool.mtx.Unlock() | |||||
| if selectedPeer = nil then | |||||
| sleep requestIntervalMS | |||||
| return selectedPeer | |||||
| ``` | |||||
| sleep for requestIntervalMS | |||||
| ### Task for creating Requesters | |||||
| This task is responsible for continuously creating and starting Requester tasks. | |||||
| ```go | |||||
| createRequesters(pool): | |||||
| while true do | |||||
| if !pool.isRunning then break | |||||
| if pool.numPending < maxPendingRequests or size(pool.requesters) < maxTotalRequesters then | |||||
| pool.mtx.Lock() | |||||
| nextHeight = pool.height + size(pool.requesters) | |||||
| requester = create new requester for height nextHeight | |||||
| pool.requesters[nextHeight] = requester | |||||
| pool.numPending += 1 // atomic increment | |||||
| start requester task | |||||
| pool.mtx.Unlock() | |||||
| else | |||||
| sleep requestIntervalMS | |||||
| pool.mtx.Lock() | |||||
| for each peer in pool.peers do | |||||
| if !peer.didTimeout && peer.numPending > 0 && peer.curRate < minRecvRate then | |||||
| send error on pool error channel | |||||
| peer.didTimeout = true | |||||
| if peer.didTimeout then | |||||
| for each requester in pool.requesters do | |||||
| if requester.getPeerID() == peer then | |||||
| enqueue msg on requestor's redoChannel | |||||
| delete(pool.peers, peerID) | |||||
| pool.mtx.Unlock() | |||||
| ``` | |||||
| ### Main blocksync reactor controller task | |||||
| ```go | |||||
| main(pool): | |||||
| create trySyncTicker with interval trySyncIntervalMS | |||||
| create statusUpdateTicker with interval statusUpdateIntervalSeconds | |||||
| create switchToConsensusTicker with interval switchToConsensusIntervalSeconds | |||||
| while true do | |||||
| select { | |||||
| upon receiving BlockRequest(Height, Peer) on pool.requestsChannel: | |||||
| try to send bcBlockRequestMessage(Height) to Peer | |||||
| upon receiving error(peer) on errorsChannel: | |||||
| stop peer for error | |||||
| upon receiving message on statusUpdateTickerChannel: | |||||
| broadcast bcStatusRequestMessage(bcR.store.Height) // message sent in a separate routine | |||||
| upon receiving message on switchToConsensusTickerChannel: | |||||
| pool.mtx.Lock() | |||||
| receivedBlockOrTimedOut = pool.height > 0 || (time.Now() - pool.startTime) > 5 Seconds | |||||
| ourChainIsLongestAmongPeers = pool.maxPeerHeight == 0 || pool.height >= pool.maxPeerHeight | |||||
| haveSomePeers = size of pool.peers > 0 | |||||
| pool.mtx.Unlock() | |||||
| if haveSomePeers && receivedBlockOrTimedOut && ourChainIsLongestAmongPeers then | |||||
| switch to consensus mode | |||||
| upon receiving message on trySyncTickerChannel: | |||||
| for i = 0; i < 10; i++ do | |||||
| pool.mtx.Lock() | |||||
| firstBlock = pool.requesters[pool.height].block | |||||
| secondBlock = pool.requesters[pool.height].block | |||||
| if firstBlock == nil or secondBlock == nil then continue | |||||
| pool.mtx.Unlock() | |||||
| verify firstBlock using LastCommit from secondBlock | |||||
| if verification failed | |||||
| pool.mtx.Lock() | |||||
| peerID = pool.requesters[pool.height].peerID | |||||
| redoRequestsForPeer(peerId) | |||||
| delete(pool.peers, peerID) | |||||
| stop peer peerID for error | |||||
| pool.mtx.Unlock() | |||||
| else | |||||
| delete(pool.requesters, pool.height) | |||||
| save firstBlock to store | |||||
| pool.height++ | |||||
| execute firstBlock | |||||
| } | |||||
| redoRequestsForPeer(pool, peerId): | |||||
| for each requester in pool.requesters do | |||||
| if requester.getPeerID() == peerID | |||||
| enqueue msg on redoChannel for requester | |||||
| ``` | |||||
| ## Channels | |||||
| Defines `maxMsgSize` for the maximum size of incoming messages, | |||||
| `SendQueueCapacity` and `RecvBufferCapacity` for maximum sending and | |||||
| receiving buffers respectively. These are supposed to prevent amplification | |||||
| attacks by setting up the upper limit on how much data we can receive & send to | |||||
| a peer. | |||||
| Sending incorrectly encoded data will result in stopping the peer. | |||||
+ 41
- 0
docs/tendermint-core/consensus/README.md
View File
| @ -0,0 +1,41 @@ | |||||
| --- | |||||
| order: 1 | |||||
| parent: | |||||
| title: Consensus | |||||
| order: 6 | |||||
| --- | |||||
| Tendermint Consensus is a distributed protocol executed by validator processes to agree on | |||||
| the next block to be added to the Tendermint blockchain. The protocol proceeds in rounds, where | |||||
| each round is a try to reach agreement on the next block. A round starts by having a dedicated | |||||
| process (called proposer) suggesting to other processes what should be the next block with | |||||
| the `ProposalMessage`. | |||||
| The processes respond by voting for a block with `VoteMessage` (there are two kinds of vote | |||||
| messages, prevote and precommit votes). Note that a proposal message is just a suggestion what the | |||||
| next block should be; a validator might vote with a `VoteMessage` for a different block. If in some | |||||
| round, enough number of processes vote for the same block, then this block is committed and later | |||||
| added to the blockchain. `ProposalMessage` and `VoteMessage` are signed by the private key of the | |||||
| validator. The internals of the protocol and how it ensures safety and liveness properties are | |||||
| explained in a forthcoming document. | |||||
| For efficiency reasons, validators in Tendermint consensus protocol do not agree directly on the | |||||
| block as the block size is big, i.e., they don't embed the block inside `Proposal` and | |||||
| `VoteMessage`. Instead, they reach agreement on the `BlockID` (see `BlockID` definition in | |||||
| [Blockchain](https://github.com/tendermint/spec/blob/master/spec/core/data_structures.md#blockid) section) | |||||
| that uniquely identifies each block. The block itself is | |||||
| disseminated to validator processes using peer-to-peer gossiping protocol. It starts by having a | |||||
| proposer first splitting a block into a number of block parts, that are then gossiped between | |||||
| processes using `BlockPartMessage`. | |||||
| Validators in Tendermint communicate by peer-to-peer gossiping protocol. Each validator is connected | |||||
| only to a subset of processes called peers. By the gossiping protocol, a validator send to its peers | |||||
| all needed information (`ProposalMessage`, `VoteMessage` and `BlockPartMessage`) so they can | |||||
| reach agreement on some block, and also obtain the content of the chosen block (block parts). As | |||||
| part of the gossiping protocol, processes also send auxiliary messages that inform peers about the | |||||
| executed steps of the core consensus algorithm (`NewRoundStepMessage` and `NewValidBlockMessage`), and | |||||
| also messages that inform peers what votes the process has seen (`HasVoteMessage`, | |||||
| `VoteSetMaj23Message` and `VoteSetBitsMessage`). These messages are then used in the gossiping | |||||
| protocol to determine what messages a process should send to its peers. | |||||
| We now describe the content of each message exchanged during Tendermint consensus protocol. | |||||
+ 370
- 0
docs/tendermint-core/consensus/reactor.md
View File
| @ -0,0 +1,370 @@ | |||||
| --- | |||||
| order: 2 | |||||
| --- | |||||
| # Reactor | |||||
| Consensus Reactor defines a reactor for the consensus service. It contains the ConsensusState service that | |||||
| manages the state of the Tendermint consensus internal state machine. | |||||
| When Consensus Reactor is started, it starts Broadcast Routine which starts ConsensusState service. | |||||
| Furthermore, for each peer that is added to the Consensus Reactor, it creates (and manages) the known peer state | |||||
| (that is used extensively in gossip routines) and starts the following three routines for the peer p: | |||||
| Gossip Data Routine, Gossip Votes Routine and QueryMaj23Routine. Finally, Consensus Reactor is responsible | |||||
| for decoding messages received from a peer and for adequate processing of the message depending on its type and content. | |||||
| The processing normally consists of updating the known peer state and for some messages | |||||
| (`ProposalMessage`, `BlockPartMessage` and `VoteMessage`) also forwarding message to ConsensusState module | |||||
| for further processing. In the following text we specify the core functionality of those separate unit of executions | |||||
| that are part of the Consensus Reactor. | |||||
| ## ConsensusState service | |||||
| Consensus State handles execution of the Tendermint BFT consensus algorithm. It processes votes and proposals, | |||||
| and upon reaching agreement, commits blocks to the chain and executes them against the application. | |||||
| The internal state machine receives input from peers, the internal validator and from a timer. | |||||
| Inside Consensus State we have the following units of execution: Timeout Ticker and Receive Routine. | |||||
| Timeout Ticker is a timer that schedules timeouts conditional on the height/round/step that are processed | |||||
| by the Receive Routine. | |||||
| ### Receive Routine of the ConsensusState service | |||||
| Receive Routine of the ConsensusState handles messages which may cause internal consensus state transitions. | |||||
| It is the only routine that updates RoundState that contains internal consensus state. | |||||
| Updates (state transitions) happen on timeouts, complete proposals, and 2/3 majorities. | |||||
| It receives messages from peers, internal validators and from Timeout Ticker | |||||
| and invokes the corresponding handlers, potentially updating the RoundState. | |||||
| The details of the protocol (together with formal proofs of correctness) implemented by the Receive Routine are | |||||
| discussed in separate document. For understanding of this document | |||||
| it is sufficient to understand that the Receive Routine manages and updates RoundState data structure that is | |||||
| then extensively used by the gossip routines to determine what information should be sent to peer processes. | |||||
| ## Round State | |||||
| RoundState defines the internal consensus state. It contains height, round, round step, a current validator set, | |||||
| a proposal and proposal block for the current round, locked round and block (if some block is being locked), set of | |||||
| received votes and last commit and last validators set. | |||||
| ```go | |||||
| type RoundState struct { | |||||
| Height int64 | |||||
| Round int | |||||
| Step RoundStepType | |||||
| Validators ValidatorSet | |||||
| Proposal Proposal | |||||
| ProposalBlock Block | |||||
| ProposalBlockParts PartSet | |||||
| LockedRound int | |||||
| LockedBlock Block | |||||
| LockedBlockParts PartSet | |||||
| Votes HeightVoteSet | |||||
| LastCommit VoteSet | |||||
| LastValidators ValidatorSet | |||||
| } | |||||
| ``` | |||||
| Internally, consensus will run as a state machine with the following states: | |||||
| - RoundStepNewHeight | |||||
| - RoundStepNewRound | |||||
| - RoundStepPropose | |||||
| - RoundStepProposeWait | |||||
| - RoundStepPrevote | |||||
| - RoundStepPrevoteWait | |||||
| - RoundStepPrecommit | |||||
| - RoundStepPrecommitWait | |||||
| - RoundStepCommit | |||||
| ## Peer Round State | |||||
| Peer round state contains the known state of a peer. It is being updated by the Receive routine of | |||||
| Consensus Reactor and by the gossip routines upon sending a message to the peer. | |||||
| ```golang | |||||
| type PeerRoundState struct { | |||||
| Height int64 // Height peer is at | |||||
| Round int // Round peer is at, -1 if unknown. | |||||
| Step RoundStepType // Step peer is at | |||||
| Proposal bool // True if peer has proposal for this round | |||||
| ProposalBlockPartsHeader PartSetHeader | |||||
| ProposalBlockParts BitArray | |||||
| ProposalPOLRound int // Proposal's POL round. -1 if none. | |||||
| ProposalPOL BitArray // nil until ProposalPOLMessage received. | |||||
| Prevotes BitArray // All votes peer has for this round | |||||
| Precommits BitArray // All precommits peer has for this round | |||||
| LastCommitRound int // Round of commit for last height. -1 if none. | |||||
| LastCommit BitArray // All commit precommits of commit for last height. | |||||
| CatchupCommitRound int // Round that we have commit for. Not necessarily unique. -1 if none. | |||||
| CatchupCommit BitArray // All commit precommits peer has for this height & CatchupCommitRound | |||||
| } | |||||
| ``` | |||||
| ## Receive method of Consensus reactor | |||||
| The entry point of the Consensus reactor is a receive method. When a message is | |||||
| received from a peer p, normally the peer round state is updated | |||||
| correspondingly, and some messages are passed for further processing, for | |||||
| example to ConsensusState service. We now specify the processing of messages in | |||||
| the receive method of Consensus reactor for each message type. In the following | |||||
| message handler, `rs` and `prs` denote `RoundState` and `PeerRoundState`, | |||||
| respectively. | |||||
| ### NewRoundStepMessage handler | |||||
| ```go | |||||
| handleMessage(msg): | |||||
| if msg is from smaller height/round/step then return | |||||
| // Just remember these values. | |||||
| prsHeight = prs.Height | |||||
| prsRound = prs.Round | |||||
| prsCatchupCommitRound = prs.CatchupCommitRound | |||||
| prsCatchupCommit = prs.CatchupCommit | |||||
| Update prs with values from msg | |||||
| if prs.Height or prs.Round has been updated then | |||||
| reset Proposal related fields of the peer state | |||||
| if prs.Round has been updated and msg.Round == prsCatchupCommitRound then | |||||
| prs.Precommits = psCatchupCommit | |||||
| if prs.Height has been updated then | |||||
| if prsHeight+1 == msg.Height && prsRound == msg.LastCommitRound then | |||||
| prs.LastCommitRound = msg.LastCommitRound | |||||
| prs.LastCommit = prs.Precommits | |||||
| } else { | |||||
| prs.LastCommitRound = msg.LastCommitRound | |||||
| prs.LastCommit = nil | |||||
| } | |||||
| Reset prs.CatchupCommitRound and prs.CatchupCommit | |||||
| ``` | |||||
| ### NewValidBlockMessage handler | |||||
| ```go | |||||
| handleMessage(msg): | |||||
| if prs.Height != msg.Height then return | |||||
| if prs.Round != msg.Round && !msg.IsCommit then return | |||||
| prs.ProposalBlockPartsHeader = msg.BlockPartsHeader | |||||
| prs.ProposalBlockParts = msg.BlockParts | |||||
| ``` | |||||
| The number of block parts is limited to 1601 (`types.MaxBlockPartsCount`) to | |||||
| protect the node against DOS attacks. | |||||
| ### HasVoteMessage handler | |||||
| ```go | |||||
| handleMessage(msg): | |||||
| if prs.Height == msg.Height then | |||||
| prs.setHasVote(msg.Height, msg.Round, msg.Type, msg.Index) | |||||
| ``` | |||||
| ### VoteSetMaj23Message handler | |||||
| ```go | |||||
| handleMessage(msg): | |||||
| if prs.Height == msg.Height then | |||||
| Record in rs that a peer claim to have ⅔ majority for msg.BlockID | |||||
| Send VoteSetBitsMessage showing votes node has for that BlockId | |||||
| ``` | |||||
| ### ProposalMessage handler | |||||
| ```go | |||||
| handleMessage(msg): | |||||
| if prs.Height != msg.Height || prs.Round != msg.Round || prs.Proposal then return | |||||
| prs.Proposal = true | |||||
| if prs.ProposalBlockParts == empty set then // otherwise it is set in NewValidBlockMessage handler | |||||
| prs.ProposalBlockPartsHeader = msg.BlockPartsHeader | |||||
| prs.ProposalPOLRound = msg.POLRound | |||||
| prs.ProposalPOL = nil | |||||
| Send msg through internal peerMsgQueue to ConsensusState service | |||||
| ``` | |||||
| ### ProposalPOLMessage handler | |||||
| ```go | |||||
| handleMessage(msg): | |||||
| if prs.Height != msg.Height or prs.ProposalPOLRound != msg.ProposalPOLRound then return | |||||
| prs.ProposalPOL = msg.ProposalPOL | |||||
| ``` | |||||
| The number of votes is limited to 10000 (`types.MaxVotesCount`) to protect the | |||||
| node against DOS attacks. | |||||
| ### BlockPartMessage handler | |||||
| ```go | |||||
| handleMessage(msg): | |||||
| if prs.Height != msg.Height || prs.Round != msg.Round then return | |||||
| Record in prs that peer has block part msg.Part.Index | |||||
| Send msg trough internal peerMsgQueue to ConsensusState service | |||||
| ``` | |||||
| ### VoteMessage handler | |||||
| ```go | |||||
| handleMessage(msg): | |||||
| Record in prs that a peer knows vote with index msg.vote.ValidatorIndex for particular height and round | |||||
| Send msg trough internal peerMsgQueue to ConsensusState service | |||||
| ``` | |||||
| ### VoteSetBitsMessage handler | |||||
| ```go | |||||
| handleMessage(msg): | |||||
| Update prs for the bit-array of votes peer claims to have for the msg.BlockID | |||||
| ``` | |||||
| The number of votes is limited to 10000 (`types.MaxVotesCount`) to protect the | |||||
| node against DOS attacks. | |||||
| ## Gossip Data Routine | |||||
| It is used to send the following messages to the peer: `BlockPartMessage`, `ProposalMessage` and | |||||
| `ProposalPOLMessage` on the DataChannel. The gossip data routine is based on the local RoundState (`rs`) | |||||
| and the known PeerRoundState (`prs`). The routine repeats forever the logic shown below: | |||||
| ```go | |||||
| 1a) if rs.ProposalBlockPartsHeader == prs.ProposalBlockPartsHeader and the peer does not have all the proposal parts then | |||||
| Part = pick a random proposal block part the peer does not have | |||||
| Send BlockPartMessage(rs.Height, rs.Round, Part) to the peer on the DataChannel | |||||
| if send returns true, record that the peer knows the corresponding block Part | |||||
| Continue | |||||
| 1b) if (0 < prs.Height) and (prs.Height < rs.Height) then | |||||
| help peer catch up using gossipDataForCatchup function | |||||
| Continue | |||||
| 1c) if (rs.Height != prs.Height) or (rs.Round != prs.Round) then | |||||
| Sleep PeerGossipSleepDuration | |||||
| Continue | |||||
| // at this point rs.Height == prs.Height and rs.Round == prs.Round | |||||
| 1d) if (rs.Proposal != nil and !prs.Proposal) then | |||||
| Send ProposalMessage(rs.Proposal) to the peer | |||||
| if send returns true, record that the peer knows Proposal | |||||
| if 0 <= rs.Proposal.POLRound then | |||||
| polRound = rs.Proposal.POLRound | |||||
| prevotesBitArray = rs.Votes.Prevotes(polRound).BitArray() | |||||
| Send ProposalPOLMessage(rs.Height, polRound, prevotesBitArray) | |||||
| Continue | |||||
| 2) Sleep PeerGossipSleepDuration | |||||
| ``` | |||||
| ### Gossip Data For Catchup | |||||
| This function is responsible for helping peer catch up if it is at the smaller height (prs.Height < rs.Height). | |||||
| The function executes the following logic: | |||||
| ```go | |||||
| if peer does not have all block parts for prs.ProposalBlockPart then | |||||
| blockMeta = Load Block Metadata for height prs.Height from blockStore | |||||
| if (!blockMeta.BlockID.PartsHeader == prs.ProposalBlockPartsHeader) then | |||||
| Sleep PeerGossipSleepDuration | |||||
| return | |||||
| Part = pick a random proposal block part the peer does not have | |||||
| Send BlockPartMessage(prs.Height, prs.Round, Part) to the peer on the DataChannel | |||||
| if send returns true, record that the peer knows the corresponding block Part | |||||
| return | |||||
| else Sleep PeerGossipSleepDuration | |||||
| ``` | |||||
| ## Gossip Votes Routine | |||||
| It is used to send the following message: `VoteMessage` on the VoteChannel. | |||||
| The gossip votes routine is based on the local RoundState (`rs`) | |||||
| and the known PeerRoundState (`prs`). The routine repeats forever the logic shown below: | |||||
| ```go | |||||
| 1a) if rs.Height == prs.Height then | |||||
| if prs.Step == RoundStepNewHeight then | |||||
| vote = random vote from rs.LastCommit the peer does not have | |||||
| Send VoteMessage(vote) to the peer | |||||
| if send returns true, continue | |||||
| if prs.Step <= RoundStepPrevote and prs.Round != -1 and prs.Round <= rs.Round then | |||||
| Prevotes = rs.Votes.Prevotes(prs.Round) | |||||
| vote = random vote from Prevotes the peer does not have | |||||
| Send VoteMessage(vote) to the peer | |||||
| if send returns true, continue | |||||
| if prs.Step <= RoundStepPrecommit and prs.Round != -1 and prs.Round <= rs.Round then | |||||
| Precommits = rs.Votes.Precommits(prs.Round) | |||||
| vote = random vote from Precommits the peer does not have | |||||
| Send VoteMessage(vote) to the peer | |||||
| if send returns true, continue | |||||
| if prs.ProposalPOLRound != -1 then | |||||
| PolPrevotes = rs.Votes.Prevotes(prs.ProposalPOLRound) | |||||
| vote = random vote from PolPrevotes the peer does not have | |||||
| Send VoteMessage(vote) to the peer | |||||
| if send returns true, continue | |||||
| 1b) if prs.Height != 0 and rs.Height == prs.Height+1 then | |||||
| vote = random vote from rs.LastCommit peer does not have | |||||
| Send VoteMessage(vote) to the peer | |||||
| if send returns true, continue | |||||
| 1c) if prs.Height != 0 and rs.Height >= prs.Height+2 then | |||||
| Commit = get commit from BlockStore for prs.Height | |||||
| vote = random vote from Commit the peer does not have | |||||
| Send VoteMessage(vote) to the peer | |||||
| if send returns true, continue | |||||
| 2) Sleep PeerGossipSleepDuration | |||||
| ``` | |||||
| ## QueryMaj23Routine | |||||
| It is used to send the following message: `VoteSetMaj23Message`. `VoteSetMaj23Message` is sent to indicate that a given | |||||
| BlockID has seen +2/3 votes. This routine is based on the local RoundState (`rs`) and the known PeerRoundState | |||||
| (`prs`). The routine repeats forever the logic shown below. | |||||
| ```go | |||||
| 1a) if rs.Height == prs.Height then | |||||
| Prevotes = rs.Votes.Prevotes(prs.Round) | |||||
| if there is a ⅔ majority for some blockId in Prevotes then | |||||
| m = VoteSetMaj23Message(prs.Height, prs.Round, Prevote, blockId) | |||||
| Send m to peer | |||||
| Sleep PeerQueryMaj23SleepDuration | |||||
| 1b) if rs.Height == prs.Height then | |||||
| Precommits = rs.Votes.Precommits(prs.Round) | |||||
| if there is a ⅔ majority for some blockId in Precommits then | |||||
| m = VoteSetMaj23Message(prs.Height,prs.Round,Precommit,blockId) | |||||
| Send m to peer | |||||
| Sleep PeerQueryMaj23SleepDuration | |||||
| 1c) if rs.Height == prs.Height and prs.ProposalPOLRound >= 0 then | |||||
| Prevotes = rs.Votes.Prevotes(prs.ProposalPOLRound) | |||||
| if there is a ⅔ majority for some blockId in Prevotes then | |||||
| m = VoteSetMaj23Message(prs.Height,prs.ProposalPOLRound,Prevotes,blockId) | |||||
| Send m to peer | |||||
| Sleep PeerQueryMaj23SleepDuration | |||||
| 1d) if prs.CatchupCommitRound != -1 and 0 < prs.Height and | |||||
| prs.Height <= blockStore.Height() then | |||||
| Commit = LoadCommit(prs.Height) | |||||
| m = VoteSetMaj23Message(prs.Height,Commit.Round,Precommit,Commit.BlockID) | |||||
| Send m to peer | |||||
| Sleep PeerQueryMaj23SleepDuration | |||||
| 2) Sleep PeerQueryMaj23SleepDuration | |||||
| ``` | |||||
| ## Broadcast routine | |||||
| The Broadcast routine subscribes to an internal event bus to receive new round steps and votes messages, and broadcasts messages to peers upon receiving those | |||||
| events. | |||||
| It broadcasts `NewRoundStepMessage` or `CommitStepMessage` upon new round state event. Note that | |||||
| broadcasting these messages does not depend on the PeerRoundState; it is sent on the StateChannel. | |||||
| Upon receiving VoteMessage it broadcasts `HasVoteMessage` message to its peers on the StateChannel. | |||||
| ## Channels | |||||
| Defines 4 channels: state, data, vote and vote_set_bits. Each channel | |||||
| has `SendQueueCapacity` and `RecvBufferCapacity` and | |||||
| `RecvMessageCapacity` set to `maxMsgSize`. | |||||
| Sending incorrectly encoded data will result in stopping the peer. | |||||
+ 13
- 0
docs/tendermint-core/evidence/README.md
View File
| @ -0,0 +1,13 @@ | |||||
| --- | |||||
| order: 1 | |||||
| parent: | |||||
| title: Evidence | |||||
| order: 3 | |||||
| --- | |||||
| Evidence is used to identify validators who have or are acting malicious. There are multiple types of evidence, to read more on the evidence types please see [Evidence Types](https://docs.tendermint.com/master/spec/core/data_structures.html#evidence). | |||||
| The evidence reactor works similar to the mempool reactor. When evidence is observed, it is sent to all the peers in a repetitive manner. This ensures evidence is sent to as many people as possible to avoid sensoring. After evidence is received by peers and committed in a block it is pruned from the evidence module. | |||||
| Sending incorrectly encoded data or data exceeding `maxMsgSize` will result | |||||
| in stopping the peer. | |||||
+ 0
- 48
docs/tendermint-core/mempool.md
View File
| @ -1,48 +0,0 @@ | |||||
| --- | |||||
| order: 12 | |||||
| --- | |||||
| # Mempool | |||||
| ## Transaction ordering | |||||
| Currently, there's no ordering of transactions other than the order they've | |||||
| arrived (via RPC or from other nodes). | |||||
| So the only way to specify the order is to send them to a single node. | |||||
| valA: | |||||
| - `tx1` | |||||
| - `tx2` | |||||
| - `tx3` | |||||
| If the transactions are split up across different nodes, there's no way to | |||||
| ensure they are processed in the expected order. | |||||
| valA: | |||||
| - `tx1` | |||||
| - `tx2` | |||||
| valB: | |||||
| - `tx3` | |||||
| If valB is the proposer, the order might be: | |||||
| - `tx3` | |||||
| - `tx1` | |||||
| - `tx2` | |||||
| If valA is the proposer, the order might be: | |||||
| - `tx1` | |||||
| - `tx2` | |||||
| - `tx3` | |||||
| That said, if the transactions contain some internal value, like an | |||||
| order/nonce/sequence number, the application can reject transactions that are | |||||
| out of order. So if a node receives `tx3`, then `tx1`, it can reject `tx3` and then | |||||
| accept `tx1`. The sender can then retry sending `tx3`, which should probably be | |||||
| rejected until the node has seen `tx2`. | |||||
+ 71
- 0
docs/tendermint-core/mempool/README.md
View File
| @ -0,0 +1,71 @@ | |||||
| --- | |||||
| order: 1 | |||||
| parent: | |||||
| title: Mempool | |||||
| order: 2 | |||||
| --- | |||||
| The mempool is a in memory pool of potentially valid transactions, | |||||
| both to broadcast to other nodes, as well as to provide to the | |||||
| consensus reactor when it is selected as the block proposer. | |||||
| There are two sides to the mempool state: | |||||
| - External: get, check, and broadcast new transactions | |||||
| - Internal: return valid transaction, update list after block commit | |||||
| ## External functionality | |||||
| External functionality is exposed via network interfaces | |||||
| to potentially untrusted actors. | |||||
| - CheckTx - triggered via RPC or P2P | |||||
| - Broadcast - gossip messages after a successful check | |||||
| ## Internal functionality | |||||
| Internal functionality is exposed via method calls to other | |||||
| code compiled into the tendermint binary. | |||||
| - ReapMaxBytesMaxGas - get txs to propose in the next block. Guarantees that the | |||||
| size of the txs is less than MaxBytes, and gas is less than MaxGas | |||||
| - Update - remove tx that were included in last block | |||||
| - ABCI.CheckTx - call ABCI app to validate the tx | |||||
| What does it provide the consensus reactor? | |||||
| What guarantees does it need from the ABCI app? | |||||
| (talk about interleaving processes in concurrency) | |||||
| ## Optimizations | |||||
| The implementation within this library also implements a tx cache. | |||||
| This is so that signatures don't have to be reverified if the tx has | |||||
| already been seen before. | |||||
| However, we only store valid txs in the cache, not invalid ones. | |||||
| This is because invalid txs could become good later. | |||||
| Txs that are included in a block aren't removed from the cache, | |||||
| as they still may be getting received over the p2p network. | |||||
| These txs are stored in the cache by their hash, to mitigate memory concerns. | |||||
| Applications should implement replay protection, read [Replay | |||||
| Protection](https://github.com/tendermint/tendermint/blob/8cdaa7f515a9d366bbc9f0aff2a263a1a6392ead/docs/app-dev/app-development.md#replay-protection) for more information. | |||||
| ## Configuration | |||||
| The mempool has various configurable paramet | |||||
| Sending incorrectly encoded data or data exceeding `maxMsgSize` will result | |||||
| in stopping the peer. | |||||
| `maxMsgSize` equals `MaxBatchBytes` (10MB) + 4 (proto overhead). | |||||
| `MaxBatchBytes` is a mempool config parameter -> defined locally. The reactor | |||||
| sends transactions to the connected peers in batches. The maximum size of one | |||||
| batch is `MaxBatchBytes`. | |||||
| The mempool will not send a tx back to any peer which it received it from. | |||||
| The reactor assigns an `uint16` number for each peer and maintains a map from | |||||
| p2p.ID to `uint16`. Each mempool transaction carries a list of all the senders | |||||
| (`[]uint16`). The list is updated every time mempool receives a transaction it | |||||
| is already seen. `uint16` assumes that a node will never have over 65535 active | |||||
| peers (0 is reserved for unknown source - e.g. RPC). | |||||
+ 105
- 0
docs/tendermint-core/mempool/config.md
View File
| @ -0,0 +1,105 @@ | |||||
| --- | |||||
| order: 2 | |||||
| --- | |||||
| # Configuration | |||||
| Here we describe configuration options around mempool. | |||||
| For the purposes of this document, they are described | |||||
| in a toml file, but some of them can also be passed in as | |||||
| environmental variables. | |||||
| Config: | |||||
| ```toml | |||||
| [mempool] | |||||
| recheck = true | |||||
| broadcast = true | |||||
| wal-dir = "" | |||||
| # Maximum number of transactions in the mempool | |||||
| size = 5000 | |||||
| # Limit the total size of all txs in the mempool. | |||||
| # This only accounts for raw transactions (e.g. given 1MB transactions and | |||||
| # max-txs-bytes=5MB, mempool will only accept 5 transactions). | |||||
| max-txs-bytes = 1073741824 | |||||
| # Size of the cache (used to filter transactions we saw earlier) in transactions | |||||
| cache-size = 10000 | |||||
| # Do not remove invalid transactions from the cache (default: false) | |||||
| # Set to true if it's not possible for any invalid transaction to become valid | |||||
| # again in the future. | |||||
| keep-invalid-txs-in-cache = false | |||||
| # Maximum size of a single transaction. | |||||
| # NOTE: the max size of a tx transmitted over the network is {max-tx-bytes}. | |||||
| max-tx-bytes = 1048576 | |||||
| # Maximum size of a batch of transactions to send to a peer | |||||
| # Including space needed by encoding (one varint per transaction). | |||||
| # XXX: Unused due to https://github.com/tendermint/tendermint/issues/5796 | |||||
| max-batch-bytes = 0 | |||||
| ``` | |||||
| <!-- Flag: `--mempool.recheck=false` | |||||
| Environment: `TM_MEMPOOL_RECHECK=false` --> | |||||
| ## Recheck | |||||
| Recheck determines if the mempool rechecks all pending | |||||
| transactions after a block was committed. Once a block | |||||
| is committed, the mempool removes all valid transactions | |||||
| that were successfully included in the block. | |||||
| If `recheck` is true, then it will rerun CheckTx on | |||||
| all remaining transactions with the new block state. | |||||
| ## Broadcast | |||||
| Determines whether this node gossips any valid transactions | |||||
| that arrive in mempool. Default is to gossip anything that | |||||
| passes checktx. If this is disabled, transactions are not | |||||
| gossiped, but instead stored locally and added to the next | |||||
| block this node is the proposer. | |||||
| ## WalDir | |||||
| This defines the directory where mempool writes the write-ahead | |||||
| logs. These files can be used to reload unbroadcasted | |||||
| transactions if the node crashes. | |||||
| If the directory passed in is an absolute path, the wal file is | |||||
| created there. If the directory is a relative path, the path is | |||||
| appended to home directory of the tendermint process to | |||||
| generate an absolute path to the wal directory | |||||
| (default `$HOME/.tendermint` or set via `TM_HOME` or `--home`) | |||||
| ## Size | |||||
| Size defines the total amount of transactions stored in the mempool. Default is `5_000` but can be adjusted to any number you would like. The higher the size the more strain on the node. | |||||
| ## Max Transactions Bytes | |||||
| Max transactions bytes defines the total size of all the transactions in the mempool. Default is 1 GB. | |||||
| ## Cache size | |||||
| Cache size determines the size of the cache holding transactions we have already seen. The cache exists to avoid running `checktx` each time we receive a transaction. | |||||
| ## Keep Invalid Transactions In Cache | |||||
| Keep invalid transactions in cache determines wether a transaction in the cache, which is invalid, should be evicted. An invalid transaction here may mean that the transaction may rely on a different tx that has not been included in a block. | |||||
| ## Max Transaction Bytes | |||||
| Max transaction bytes defines the max size a transaction can be for your node. If you would like your node to only keep track of smaller transactions this field would need to be changed. Default is 1MB. | |||||
| ## Max Batch Bytes | |||||
| Max batch bytes defines the amount of bytes the node will send to a peer. Default is 0. | |||||
| > Note: Unused due to https://github.com/tendermint/tendermint/issues/5796 | |||||
+ 177
- 0
docs/tendermint-core/pex/README.md
View File
| @ -0,0 +1,177 @@ | |||||
| --- | |||||
| order: 1 | |||||
| parent: | |||||
| title: Peer Exchange | |||||
| order: 5 | |||||
| --- | |||||
| # Peer Strategy and Exchange | |||||
| Here we outline the design of the PeerStore | |||||
| and how it used by the Peer Exchange Reactor (PEX) to ensure we are connected | |||||
| to good peers and to gossip peers to others. | |||||
| ## Peer Types | |||||
| Certain peers are special in that they are specified by the user as `persistent`, | |||||
| which means we auto-redial them if the connection fails, or if we fail to dial | |||||
| them. | |||||
| Some peers can be marked as `private`, which means | |||||
| we will not put them in the peer store or gossip them to others. | |||||
| All peers except private peers and peers coming from them are tracked using the | |||||
| peer store. | |||||
| The rest of our peers are only distinguished by being either | |||||
| inbound (they dialed our public address) or outbound (we dialed them). | |||||
| ## Discovery | |||||
| Peer discovery begins with a list of seeds. | |||||
| When we don't have enough peers, we | |||||
| 1. ask existing peers | |||||
| 2. dial seeds if we're not dialing anyone currently | |||||
| On startup, we will also immediately dial the given list of `persistent_peers`, | |||||
| and will attempt to maintain persistent connections with them. If the | |||||
| connections die, or we fail to dial, we will redial every 5s for a few minutes, | |||||
| then switch to an exponential backoff schedule, and after about a day of | |||||
| trying, stop dialing the peer. This behavior is when `persistent_peers_max_dial_period` is configured to zero. | |||||
| But If `persistent_peers_max_dial_period` is set greater than zero, terms between each dial to each persistent peer | |||||
| will not exceed `persistent_peers_max_dial_period` during exponential backoff. | |||||
| Therefore, `dial_period` = min(`persistent_peers_max_dial_period`, `exponential_backoff_dial_period`) | |||||
| and we keep trying again regardless of `maxAttemptsToDial` | |||||
| As long as we have less than `MaxNumOutboundPeers`, we periodically request | |||||
| additional peers from each of our own and try seeds. | |||||
| ## Listening | |||||
| Peers listen on a configurable ListenAddr that they self-report in their | |||||
| NodeInfo during handshakes with other peers. Peers accept up to | |||||
| `MaxNumInboundPeers` incoming peers. | |||||
| ## Address Book | |||||
| Peers are tracked via their ID (their PubKey.Address()). | |||||
| Peers are added to the peer store from the PEX when they first connect to us or | |||||
| when we hear about them from other peers. | |||||
| The peer store is arranged in sets of buckets, and distinguishes between | |||||
| vetted (old) and unvetted (new) peers. It keeps different sets of buckets for | |||||
| vetted and unvetted peers. Buckets provide randomization over peer selection. | |||||
| Peers are put in buckets according to their IP groups. | |||||
| IP group can be a masked IP (e.g. `1.2.0.0` or `2602:100::`) or `local` for | |||||
| local addresses or `unroutable` for unroutable addresses. The mask which | |||||
| corresponds to the `/16` subnet is used for IPv4, `/32` subnet - for IPv6. | |||||
| Each group has a limited number of buckets to prevent DoS attacks coming from | |||||
| that group (e.g. an attacker buying a `/16` block of IPs and launching a DoS | |||||
| attack). | |||||
| [highwayhash](https://arxiv.org/abs/1612.06257) is used as a hashing function | |||||
| when calculating a bucket. | |||||
| When placing a peer into a new bucket: | |||||
| ```md | |||||
| hash(key + sourcegroup + int64(hash(key + group + sourcegroup)) % bucket_per_group) % num_new_buckets | |||||
| ``` | |||||
| When placing a peer into an old bucket: | |||||
| ```md | |||||
| hash(key + group + int64(hash(key + addr)) % buckets_per_group) % num_old_buckets | |||||
| ``` | |||||
| where `key` - random 24 HEX string, `group` - IP group of the peer (e.g. `1.2.0.0`), | |||||
| `sourcegroup` - IP group of the sender (peer who sent us this address) (e.g. `174.11.0.0`), | |||||
| `addr` - string representation of the peer's address (e.g. `174.11.10.2:26656`). | |||||
| A vetted peer can only be in one bucket. An unvetted peer can be in multiple buckets, and | |||||
| each instance of the peer can have a different IP:PORT. | |||||
| If we're trying to add a new peer but there's no space in its bucket, we'll | |||||
| remove the worst peer from that bucket to make room. | |||||
| ## Vetting | |||||
| When a peer is first added, it is unvetted. | |||||
| Marking a peer as vetted is outside the scope of the `p2p` package. | |||||
| For Tendermint, a Peer becomes vetted once it has contributed sufficiently | |||||
| at the consensus layer; ie. once it has sent us valid and not-yet-known | |||||
| votes and/or block parts for `NumBlocksForVetted` blocks. | |||||
| Other users of the p2p package can determine their own conditions for when a peer is marked vetted. | |||||
| If a peer becomes vetted but there are already too many vetted peers, | |||||
| a randomly selected one of the vetted peers becomes unvetted. | |||||
| If a peer becomes unvetted (either a new peer, or one that was previously vetted), | |||||
| a randomly selected one of the unvetted peers is removed from the peer store. | |||||
| More fine-grained tracking of peer behaviour can be done using | |||||
| a trust metric (see below), but it's best to start with something simple. | |||||
| ## Select Peers to Dial | |||||
| When we need more peers, we pick addresses randomly from the addrbook with some | |||||
| configurable bias for unvetted peers. The bias should be lower when we have | |||||
| fewer peers and can increase as we obtain more, ensuring that our first peers | |||||
| are more trustworthy, but always giving us the chance to discover new good | |||||
| peers. | |||||
| We track the last time we dialed a peer and the number of unsuccessful attempts | |||||
| we've made. If too many attempts are made, we mark the peer as bad. | |||||
| Connection attempts are made with exponential backoff (plus jitter). Because | |||||
| the selection process happens every `ensurePeersPeriod`, we might not end up | |||||
| dialing a peer for much longer than the backoff duration. | |||||
| If we fail to connect to the peer after 16 tries (with exponential backoff), we | |||||
| remove from peer store completely. But for persistent peers, we indefinitely try to | |||||
| dial all persistent peers unless `persistent_peers_max_dial_period` is configured to zero | |||||
| ## Select Peers to Exchange | |||||
| When we’re asked for peers, we select them as follows: | |||||
| - select at most `maxGetSelection` peers | |||||
| - try to select at least `minGetSelection` peers - if we have less than that, select them all. | |||||
| - select a random, unbiased `getSelectionPercent` of the peers | |||||
| Send the selected peers. Note we select peers for sending without bias for vetted/unvetted. | |||||
| ## Preventing Spam | |||||
| There are various cases where we decide a peer has misbehaved and we disconnect from them. | |||||
| When this happens, the peer is removed from the peer store and black listed for | |||||
| some amount of time. We call this "Disconnect and Mark". | |||||
| Note that the bad behaviour may be detected outside the PEX reactor itself | |||||
| (for instance, in the mconnection, or another reactor), but it must be communicated to the PEX reactor | |||||
| so it can remove and mark the peer. | |||||
| In the PEX, if a peer sends us an unsolicited list of peers, | |||||
| or if the peer sends a request too soon after another one, | |||||
| we Disconnect and MarkBad. | |||||
| ## Trust Metric | |||||
| The quality of peers can be tracked in more fine-grained detail using a | |||||
| Proportional-Integral-Derivative (PID) controller that incorporates | |||||
| current, past, and rate-of-change data to inform peer quality. | |||||
| While a PID trust metric has been implemented, it remains for future work | |||||
| to use it in the PEX. | |||||
| See the [trustmetric](https://github.com/tendermint/tendermint/blob/master/docs/architecture/adr-006-trust-metric.md) | |||||
| and [trustmetric useage](https://github.com/tendermint/tendermint/blob/master/docs/architecture/adr-007-trust-metric-usage.md) | |||||
| architecture docs for more details. | |||||
| <!-- todo: diagrams!!! --> | |||||
+ 0
- 18
docs/tendermint-core/state-sync.md
View File
| @ -1,18 +0,0 @@ | |||||
| --- | |||||
| order: 11 | |||||
| --- | |||||
| # State Sync | |||||
| With block sync a node is downloading all of the data of an application from genesis and verifying it. | |||||
| With state sync your node will download data related to the head or near the head of the chain and verify the data. | |||||
| This leads to drastically shorter times for joining a network. | |||||
| Information on how to configure state sync is located in the [nodes section](../nodes/state-sync.md) | |||||
| ## Events | |||||
| When a node starts with the statesync flag enabled in the config file, it will emit two events: one upon starting statesync and the other upon completion. | |||||
| The user can query the events by subscribing `EventQueryStateSyncStatus` | |||||
| Please check [types](https://pkg.go.dev/github.com/tendermint/tendermint/types?utm_source=godoc#pkg-constants) for the details. | |||||
+ 85
- 0
docs/tendermint-core/state-sync/README.md
View File
| @ -0,0 +1,85 @@ | |||||
| --- | |||||
| order: 1 | |||||
| parent: | |||||
| title: State Sync | |||||
| order: 4 | |||||
| --- | |||||
| State sync allows new nodes to rapidly bootstrap and join the network by discovering, fetching, | |||||
| and restoring state machine snapshots. For more information, see the [state sync ABCI section](https://docs.tendermint.com/master/spec/abci/abci.html#state-sync)). | |||||
| The state sync reactor has two main responsibilities: | |||||
| * Serving state machine snapshots taken by the local ABCI application to new nodes joining the | |||||
| network. | |||||
| * Discovering existing snapshots and fetching snapshot chunks for an empty local application | |||||
| being bootstrapped. | |||||
| The state sync process for bootstrapping a new node is described in detail in the section linked | |||||
| above. While technically part of the reactor (see `statesync/syncer.go` and related components), | |||||
| this document will only cover the P2P reactor component. | |||||
| For details on the ABCI methods and data types, see the [ABCI documentation](https://docs.tendermint.com/master/spec/abci/). | |||||
| Information on how to configure state sync is located in the [nodes section](../../nodes/state-sync.md) | |||||
| ## State Sync P2P Protocol | |||||
| When a new node begin state syncing, it will ask all peers it encounters if it has any | |||||
| available snapshots: | |||||
| ```go | |||||
| type snapshotsRequestMessage struct{} | |||||
| ``` | |||||
| The receiver will query the local ABCI application via `ListSnapshots`, and send a message | |||||
| containing snapshot metadata (limited to 4 MB) for each of the 10 most recent snapshots: | |||||
| ```go | |||||
| type snapshotsResponseMessage struct { | |||||
| Height uint64 | |||||
| Format uint32 | |||||
| Chunks uint32 | |||||
| Hash []byte | |||||
| Metadata []byte | |||||
| } | |||||
| ``` | |||||
| The node running state sync will offer these snapshots to the local ABCI application via | |||||
| `OfferSnapshot` ABCI calls, and keep track of which peers contain which snapshots. Once a snapshot | |||||
| is accepted, the state syncer will request snapshot chunks from appropriate peers: | |||||
| ```go | |||||
| type chunkRequestMessage struct { | |||||
| Height uint64 | |||||
| Format uint32 | |||||
| Index uint32 | |||||
| } | |||||
| ``` | |||||
| The receiver will load the requested chunk from its local application via `LoadSnapshotChunk`, | |||||
| and respond with it (limited to 16 MB): | |||||
| ```go | |||||
| type chunkResponseMessage struct { | |||||
| Height uint64 | |||||
| Format uint32 | |||||
| Index uint32 | |||||
| Chunk []byte | |||||
| Missing bool | |||||
| } | |||||
| ``` | |||||
| Here, `Missing` is used to signify that the chunk was not found on the peer, since an empty | |||||
| chunk is a valid (although unlikely) response. | |||||
| The returned chunk is given to the ABCI application via `ApplySnapshotChunk` until the snapshot | |||||
| is restored. If a chunk response is not returned within some time, it will be re-requested, | |||||
| possibly from a different peer. | |||||
| The ABCI application is able to request peer bans and chunk refetching as part of the ABCI protocol. | |||||
| If no state sync is in progress (i.e. during normal operation), any unsolicited response messages | |||||
| are discarded. | |||||